
Introducing new capabilities for Data-centric Foundation Model Development in Snorkel Flow
Powerful new large language or foundation models (FMs) like GPT-3, Stable Diffusion, BERT, and more have taken the AI space by storm, going viral—even beyond technical practitioners—thanks to incredible capabilities around text generation, image synthesis, and more. However, enterprises face fundamental barriers to using these foundation models on real, scaled, high-value use cases; these include adaptation to complex, domain-specific tasks and deployment within existing cost and governance constraints.
At Snorkel AI, we’ve been pioneering and developing data-centric AI development methods for over seven years, starting at the Stanford AI lab and now via our data-centric AI development platform, Snorkel Flow. We’ve spent the last 12+ months researching, developing, and validating a data-centric AI solution for enterprises to successfully adopt foundation models.
Today, we’re excited to introduce Data-centric Foundation Model Development, a new paradigm for enterprises to use foundation models to solve complex, real-world problems. With this new approach, you can use programmatic labeling to fine-tune and adapt foundation models or use FMs automatically label data and train smaller, specialized deployable models. To make this approach immediately accessible to enterprise data science and machine learning teams, we’ve added a new suite of capabilities to the Snorkel Flow platform. These features, available in preview today, include:
- Foundation Model Fine-tuning: Fine-tune modern foundation models like GPT-3, RoBERTa, CLIP, and more by programmatically creating large, task- and domain-specific training data sets.
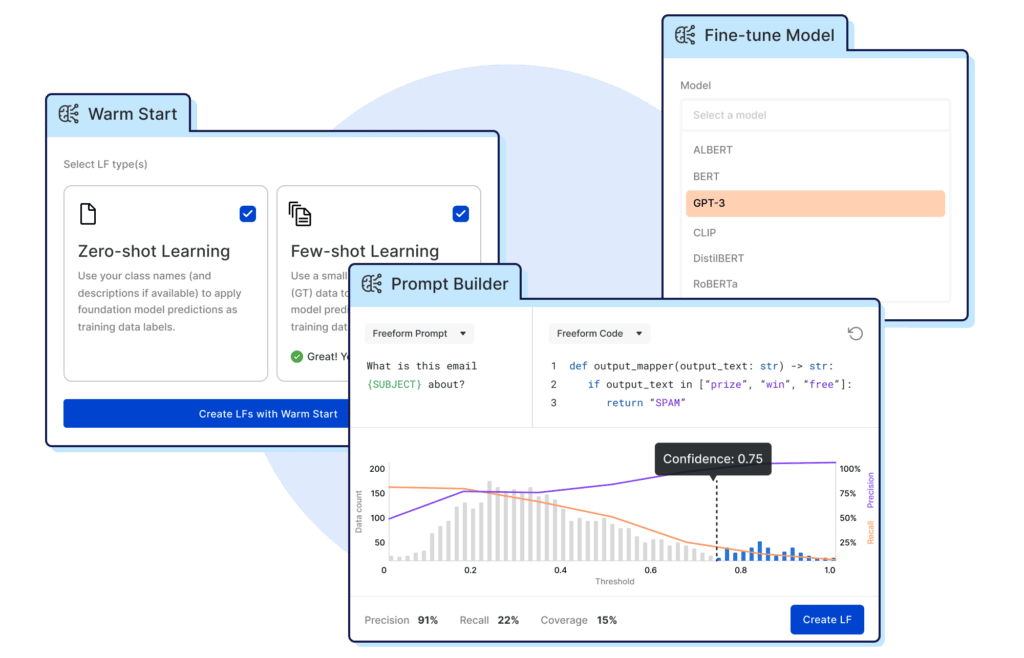
- Foundation Model Warm Start: Use foundation models with zero- and few-shot learning to auto-label training data with a push of a button to train deployable models.
- Foundation Model Prompt Builder: Develop, evaluate, and combine prompts to tune and correct the output of foundation models to precisely label datasets and train deployable models.
Across academic papers, research studies, and with Fortune 500 customers, we’ve validated how Data-centric Foundation Model Development can unlock the power of foundation models in transformative ways. In one case study on LEDGAR, a complex 100-class legal benchmark task, we used the Data-centric Foundation Model Development workflow to achieve the same quality as a fine-tuned GPT-3 model with a model that was 1000x smaller and required <1% as many ground truth labels. These results were also achieved with dramatic cost savings; creating the model was 75% less expensive, and inference for the smaller model was 0.1% of the cost to use GPT-3.
Snorkel Flow customer Pixability, a video advertising platform, needed to constantly and accurately categorize millions of new YouTube videos to help brands suitably place ads and maximize performance. With Snorkel Flow, they distilled knowledge from foundation models to build smaller, deployable classification models with more than 90% accuracy in just days, improving ad performance and brand-suitable targeting.
“With Snorkel Flow, we can apply data-centric workflows to distill knowledge from foundation models and build high-cardinality classification models with more than 90% accuracy in days.”
Jackie Swansburg Paulino, CPO, Pixability
Together with a cross-section of our customers, we’ve seen similar results applying Data-centric Foundation Model Development to various NLP and other classification and extraction tasks on text, documents, PDFs, conversation transcripts, and other data types.
- A top US bank improved accuracy from 25.5% to 91.5% over a complex NLP problem extracting information from multi-hundred page contracts.
- A global home goods e-commerce company improved accuracy by 7-22% when classifying products from descriptions and reduced development time from four weeks to one day.
Let’s take a closer look at the barriers keeping enterprises from applying foundation models—and how Snorkel Flow’s Data-centric Foundation Model Development capabilities help overcome them.
Adaptation and deployment gaps block enterprises from using AI-supercharging foundation models
Massively scaled, self-supervised foundation models accomplish generative tasks, like producing long-form text, images, and even videos, with remarkable realism and flexibility, pulling on multi-billions of parameters learned over terabytes of data, mostly open web text.
However, step into an enterprise organization (whether a large US bank, government agency, or healthcare system—even those with significant AI spending and production deployment), and odds are you won’t find any foundation models in production for critical applications. This is despite the fact you’ll undoubtedly see the excitement for foundation models from individual data scientists up to the C-suite. Why is there such an astonishing gap? And how do we bridge it?
Enterprises face—and will continue to face—two key challenges around using foundation models: adaptation to complex, domain-specific tasks and deployment within governance and cost constraints.
Adaptation to complex, performance-critical use cases
Foundation models are used today for generative tasks, which are often exploratory or creative. They typically entail a human-in-the-loop and don’t require high accuracy. For example, it’s ok for a user to sort through dozens of tries before getting the “right” image. Foundation models have also been successfully applied to simple automation tasks where accuracy is required, but problem datasets and tasks are fairly standard, such as binary classification on generic web text similar to the data used to train a given foundation model.
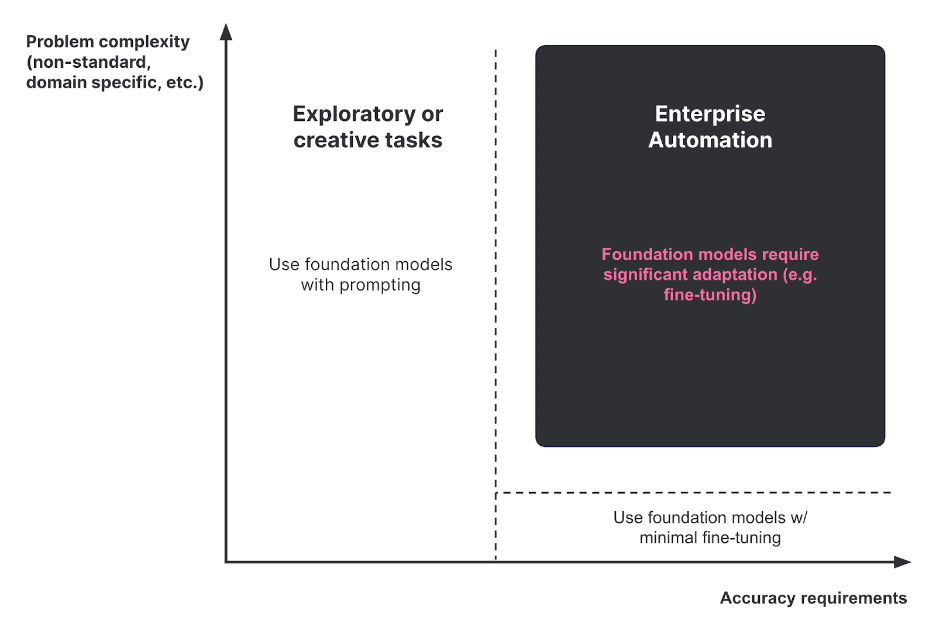
However, foundation models (FMs) don’t magically work out of the box on complex, domain-specific tasks that require high accuracy to ship to production. Unlike generative or simpler, generic tasks, real-world enterprise use cases require fine-tuning FMs on large labeled datasets. And as nearly all AI/ML teams have experienced, creating high-quality training datasets with traditional, manual data labeling approaches is painfully slow and expensive.
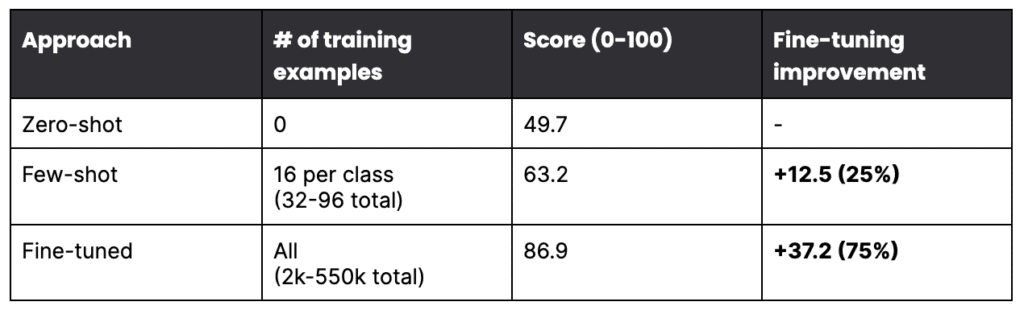
Deployment with governance and cost constraints
Foundation models are extremely costly and slow to maintain and serve in production. Even more importantly, there are likely years of governance challenges ahead, given their complex, emergent behaviors, which researchers are just beginning to tackle and understand. This is especially true for critical use cases and within regulated industries.
“We currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties.”
On the Opportunities and Risks of Foundation Models: Report by Stanford Institute for Human-Centered Artificial Intelligence
Unfortunately, existing foundation model solutions don’t do anything to solve critical adaptation and deployment problems blocking use on real enterprise AI problems. Generally, they relegate the task of adapting back to the user (for example, by requiring advanced prompting techniques or extensive manual data labeling for fine-tuning) and don’t support deployment options beyond direct inference APIs, which aren’t currently feasible for most high-value enterprise use cases.
Foundation models, which hold the potential to supercharge and accelerate AI, are a key priority for every enterprise looking to put AI to use. How do we bridge these adaptation and deployment gaps to enable the foundation model-powered enterprise? The answer comes down to the data.
Foundation models are entering their data-centric era
Like most modern machine learning techniques, the secret sauce of foundation models is increasingly in the data they’re trained on. Recent foundation models like BLOOM (Le Scao et al., 2022), OpenAI Whisper (Radford et al., 2022), and more have converged to use roughly the same architectures but differ in the creative and careful ways their training datasets are curated. Academic studies show the key impact of dataset design and development (e.g., Nguyen et al., 2022). And the recent results of FLAN (Wei et al., 2022) and others have shown tremendous power in intentional, extensive fine-tuning to improve foundation model performance.
Given recent foundation model advancements are predominately achieved with data-centric approaches from the ground up, it’s unsurprising that data (and data development) is key to solving the major challenges of adapting and deploying FMs in enterprise settings.
To start: when adapting foundation models to be performant in production on complex predictive tasks, fine-tuning on custom-labeled training data is critical from initial self-supervised training to final target task fine-tuning.
What about the challenge of deployment? Recent work, including several papers from our extended Snorkel AI team (Smith et al., 2022; Arora et al., 2022), provides a solution for deploying massive FMs when AI/ML teams face governance or cost constraints (as is the case in most enterprise settings). The solution is using FMs to power the data-centric development of smaller, more targeted deployment models—which results have shown to deliver even higher accuracy.
Introducing Data-Centric Foundation Model Development in Snorkel Flow
With Snorkel Flow’s Data-centric Foundation Model Development capabilities, enterprise AI/ML teams overcome the challenges blocking them from using foundation models. They do so by:
- Rapidly adapting foundation models to complex, domain-specific datasets and tasks via fine-tuning with Snorkel Flow’s unique programmatic labeling capabilities and data-centric development workflow.
- Building deployable models by distilling relevant foundation model knowledge into training data used to train more efficient, specialized models that can be shipped to production within governance and cost constraints and MLOps infrastructure.
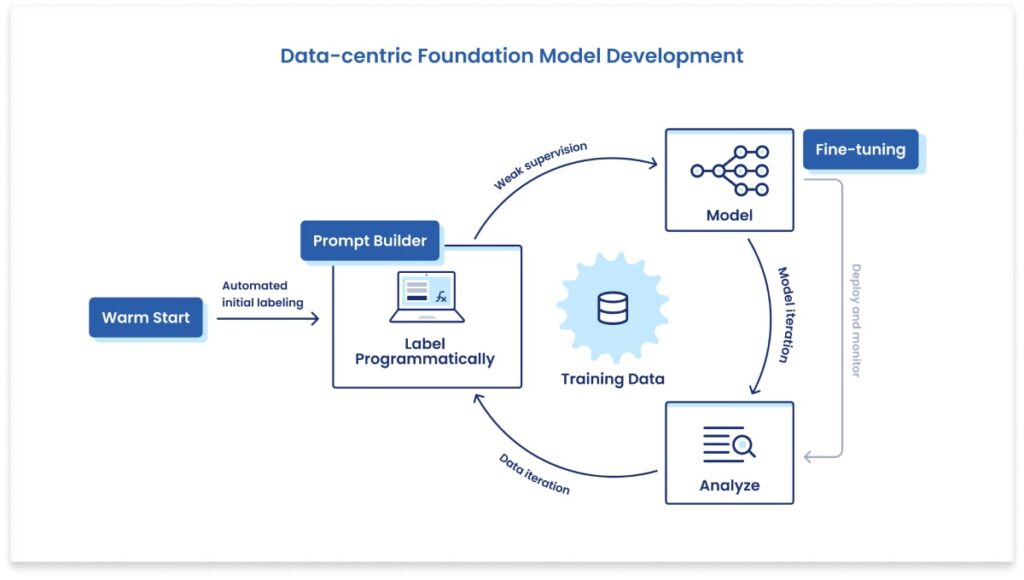
Adapting foundation models with Foundation Model Fine-tuning
As we’ve established, foundation models require significant adaptation to do well on the complex, custom datasets and tasks that generally constitute high-value enterprise use cases. Human/AI analogies are often misleading, but in this case, a simple one applies: imagine learning to read on generic internet text, and then being asked to parse a multi-hundred-page legal document; you’d probably need some further training first! Foundation models are similarly powerful “generalists” that must be adapted for “specialist” problems through fine-tuning.
Snorkel Flow has supported fine-tuning models since inception, dramatically accelerating training data creation through programmatic labeling and data-centric development (techniques pioneered by our team over the last 7+ years). Now, with Foundation Model Fine-tuning in Snorkel Flow, users apply this same advantage to fine-tune FMs like GPT-3, RoBERTa, CLIP, and more, radically faster and within a single, unified workflow.
A top US bank has applied Snorkel Flow’s Data-centric Foundation Model Development to save its team of experts thousands of hours of manual information extraction for KYC verification as part of anti-money laundering procedures.
A top US bank improved accuracy from 25.5% to 91.5% when extracting information from contracts by fine-tuning a foundation model using Snorkel Flow.
Building deployable models with Foundation Model Warm Start and Prompt Builder
In many enterprise settings, however, fine-tuning and deploying a large foundation model to production isn’t an option. In Snorkel Flow, users can instead now apply the power of foundation models to accelerate labeling and developing training data. They then use this high-quality dataset to train smaller models that can be deployed within existing cost and governance constraints and on existing MLOps infrastructure. This Data-Centric Foundation Model Development workflow is powered by two new features in Snorkel Flow, Foundation Model Warm Start, and Prompt Builder.
Foundation Model Warm Start: Automatically jump-start training data labeling
Foundation Model Warm Start is a new feature for first-pass, push-button auto-labeling powered by foundation models combined with state-of-the-art zero- and few-shot learning techniques. Warm Start can be viewed as a way of distilling the relevant information from foundation models to quickly jumpstart development on a new problem. Warm Start auto-labels the “easier” parts of training data using class names and descriptions (for zero-shot learning) and a small amount of ground truth data (for few-shot learning). From there, users focus on refining and adapting trickier, low-confidence slices of their dataset using the rest of Snorkel Flow’s data-centric AI workflow, including Foundation Model Prompt Builder.
Foundation Model Prompt Builder: Correct and refine foundation model knowledge
Foundation models will make many mistakes on complex, real-world problems. The same applies to Warm Start, which is why it’s just that—a starting point. This is where the third new foundation model capability we’ve launched shines: Foundation Model Prompt Builder. Prompt Builder provides push-button and power-user code options for developing and refining prompts.
With Prompt Builder, users query foundation models with specific, pointed questions or prompts to extract domain-relevant knowledge efficiently. For example, to use the canonical example of a spam classifier, we might auto-label some obvious types of spam with Warm Start, then use the Prompt Builder to create a more targeted prompt LF asking, “Is this email asking for my password?” In doing so, we convey domain knowledge about a particular type of spam (phishing).
In Snorkel Flow, prompts are just another type of labeling function. They fit seamlessly into Snorkel Flow’s data-centric workflow, which supports combining, tuning, and integrating their outputs using theoretically-grounded modeling and human-in-the-loop error analysis techniques. With the combination of Prompt Builder and Snorkel Flow’s data-centric AI development loop, users can identify specific foundation model errors, correct them, and refine their output by pruning, modifying, and developing new FM prompts.
Critically, the labeling functions created by Warm Start and Prompt Builder can be combined with many other sources, expressed as labeling functions in Snorkel Flow. While foundation models represent a phenomenal advancement for AI, they’re generalists, as we’ve described. With Snorkel Flow, instead of relying on singular FMs, users combine many FMs with their rich enterprise knowledge sources as inputs into programmatic labeling. Examples of enterprise knowledge sources include previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and more. These inputs are intelligently combined, tuned, and integrated, as described above.
A global home goods ecommerce company improved accuracy by 7-22% when classifying products from descriptions by leveraging foundation models using Snorkel Flow.
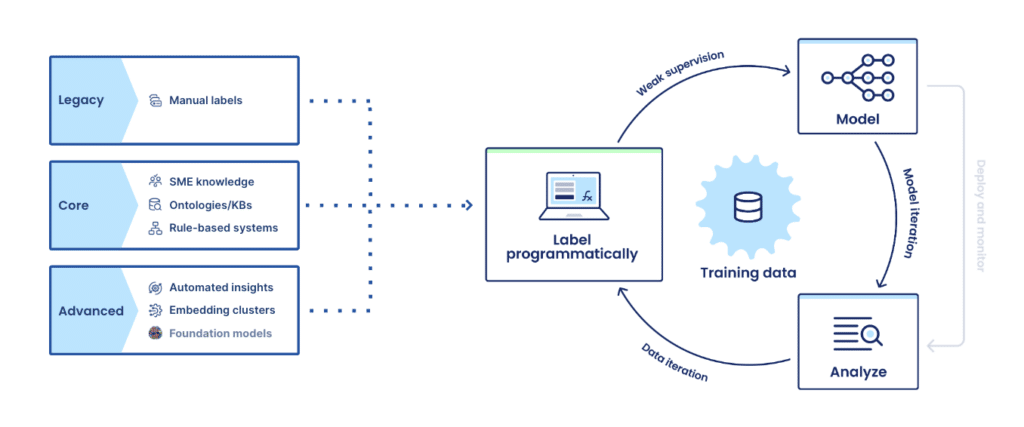
With high-quality labeled training data, users are ready to train any model for deployment. As we’ve described, this is most often a dramatically smaller, more accurate model that can be deployed in existing governance and MLOps environments.
Bridging the adaptation and deployment gap with Data-centric Foundation Model Development in Snorkel Flow
Foundation models are rightfully compared to other game-changing industrial advances like steam engines or electric motors. They’re core to the transition of AI from a bespoke, less predictable science to an industrialized, democratized practice. With Snorkel Flow’s Data-centric Foundation Model Development, enterprise data science and machine learning teams can now cross the chasm of adaptation and deployment challenges and use the full power of foundation models to supercharge AI development.
Learn more about Data-centric Foundation Model Development in Snorkel Flow:
- Join us at the virtual launch event led by Alex Ratner, Co-founder and CEO at Snorkel AI, on November 22nd, 2022.
- See a demo of the new features in Snorkel Flow by Braden Hancock, Co-founder and Head of Research at Snorkel AI, on December 15th, 2022.
- Attend the Data-Centric Foundation Model Summit, a one-day research event with speakers from Cohere, Google, SambaNova Systems, Snorkel AI, Stanford AI lab, and more, on January 17th, 2023.

Alex Ratner
Co-Founder & CEO, Snorkel AI
Alex Ratner is the co-founder and CEO at Snorkel AI, and an affiliate assistant professor of computer science at the University of Washington. Prior to Snorkel AI and UW, he completed his Ph.D. in computer science advised by Christopher Ré at Stanford, where he started and led the Snorkel open source project. His research focused on data-centric AI, applying data management and statistical learning techniques to AI data development and curation.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

