
Jan Neumann, Vice President, Machine Learning, Comcast Applied AI and Discovery gave a presentation entitled “Data-Centric AI in Comcast’s Voice and Conversational Interfaces” at Snorkels Future of Data-Centric AI conference in 2022. Below follows a transcription of his presentation, lightly edited for readability.
Jan Neumann: I’m excited to talk today about how we are using data-centric AI and the Snorkel framework at Comcast to power our voice and conversational interfaces. Let me get started with the presentation.
I’m leading the Comcast Applied AI and Discovery team, and our mission is to delight our customers by connecting them to the moments that matter, either via connectivity or in the entertainment domain. Our team is split into five product verticals. One, which I will talk about today, is Voice Control, where we want to use voice for all the interactions with our Xfinity systems.
But there are also other teams such as Content Discovery, where we recommend the right show at the right time. Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services. We also have a team focused on the Digital Home and the applications of AI inside of it. For example, building algorithms that run on our cameras and detect if somebody is coming home, or if a package gets delivered for you. And then finally, we also work on machine learning and AI for the Customer Experience, where we’re building “smart assistants” to help our customers, agents, and technicians solve different kinds of problems.
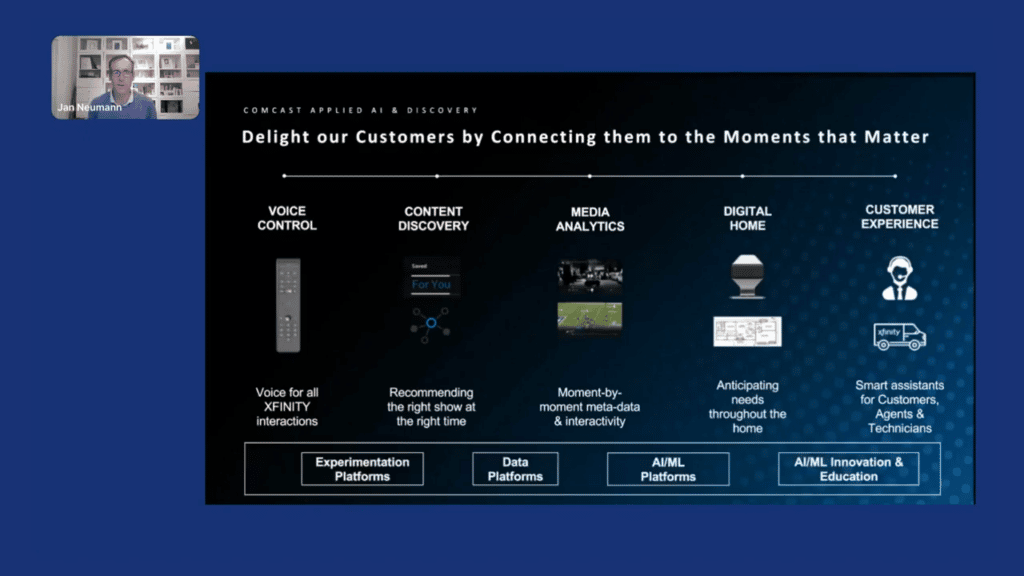
In addition, we are also responsible for the Experimentation Platforms at Comcast and the products, the data platforms that kind of underlie all these AI and machine-learning applications, as well as our product analytics platforms that make it easier to train, develop, and manage models. And finally, also, AI/ML innovation and educational efforts.
But let’s focus on the use-case of data-centric AI for Voice.

The voice remote was launched for Comcast in 2015. They are now about 28 million-plus remotes in use just on our X1 system alone. And we are receiving about 12-billion-plus voice queries from Comcast Sky as well as our syndication partners. That is a lot of data that we need to analyze to improve the models that power Voice remote. But so how does it actually work?

If you take the Voice remote, you see this blue button in the middle, you press it, and we then stream the audio to our speech recognition system where we then translate the sound into a text query.
Once we have the text query, we then have multiple machine-learning models that translate the raw text into an intent, and then also identify what is the right action that you, as the customer, would like to accomplish. Then, once we identify the most likely solution, we basically execute it. So, send the results to the set-top box and make it appear on the TV screen—in this case, all the latest news about artificial intelligence.
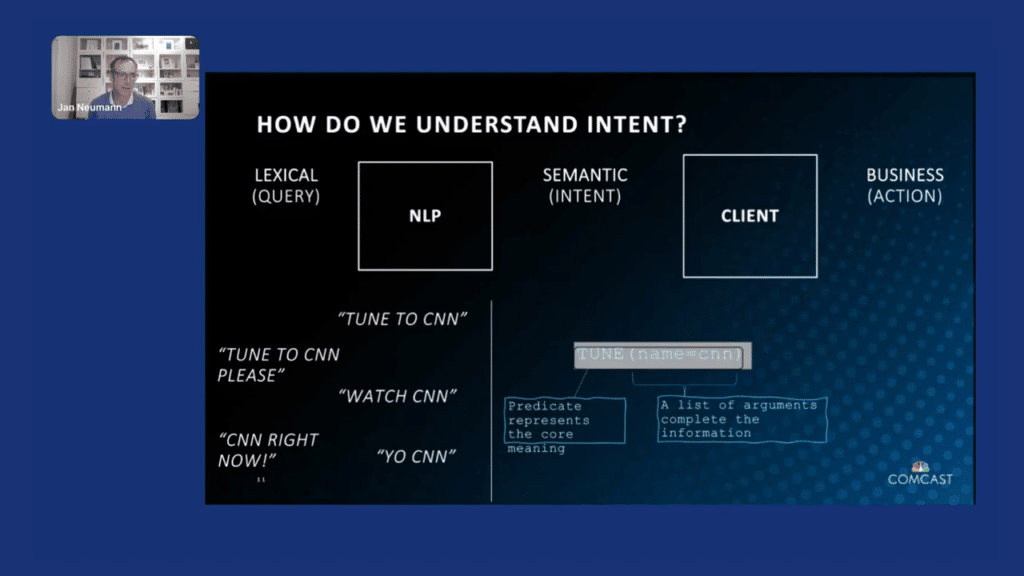
How do we understand the “intent”?
You can really think about intent as a translation of (as I mentioned) the lexical query, using NLP [natural language processing] technologies to understand the semantics of the query, which is the intent, and then translating it into a business action.
In this case, specifically, we are focusing on the query-to-intent portion. One of the challenges we have is that the customers use many different expressions to express the same intent. So, if you want to tune to CNN, you could say: “tune to CNN”; “tune to CNN, please”; you can say, “watch CNN”; “CNN right now”; or, even very colloquially, “yo, CNN.” Each time, no matter what you say, ideally, the output should be an intent of a tune, right? That represents the core meaning. And then, a set of parameters, in this case, CNN, as the name of the channel you want to tune to, right? That completes all the information necessary to then identify the correct business action.
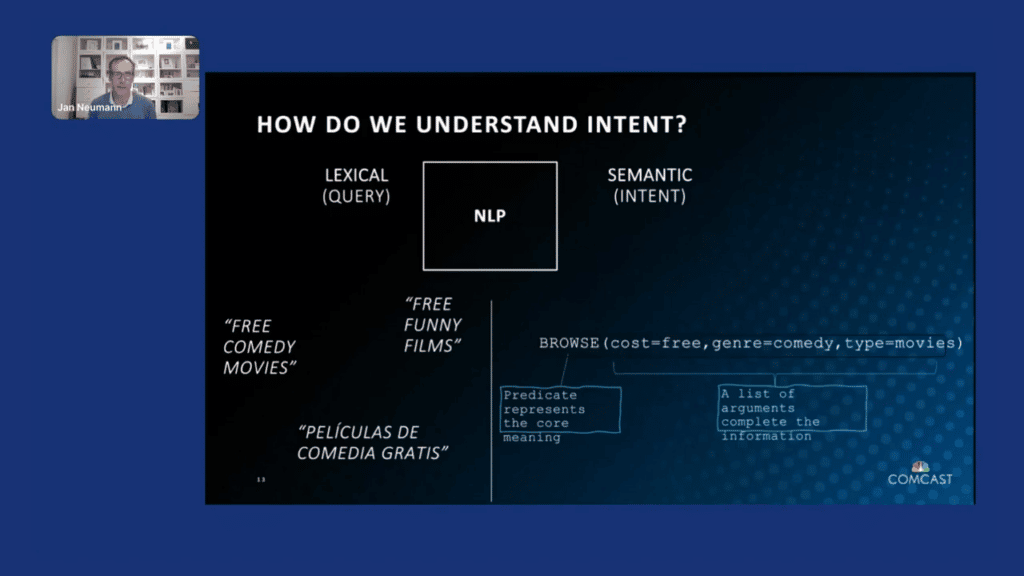
There are also other examples. So, for example, here if the customer says, “free comedy movies,” “free funny films,” or even uses a different language to ask for, essentially, just browsing for movies that are free, that are of the genre comedy, and that are of the type movies. And so you can imagine that this is not an easy problem.
What are some of the reasons why this is difficult?
Many of the queries that we have to process are short and they’re very diverse, and we have to refer to many different entities. In our catalogs, we have millions of entities and hundreds of thousands are often added every single day. And they change. There’s a lot of ambiguity. “Chicago Fire” is both a TV show and a sports team. Which one are you referring to? Often our customers don’t remember exactly what the correct title of a given show is. For example, they might say, for the show “Big Little Lies,” they ask for “Little Big Lies,” or “little big” something.
We have multiple sequels or the original movie. People will still just ask for “Princess Diaries,” so which one should we return? Another issue is that on the TV, there are only limited ways where you can back up to typing in the search because you don’t have a keyboard readily available that allows you to input your search. The type of personalization is often more limited because the TV is often a shared living-room device, rather than your phone, where we know that if you’re using it, it’s you. And finally, also speech recognition can be very tricky, for example, to distinguish between “you” versus “Caillou.” It’s very difficult for an automatic system.
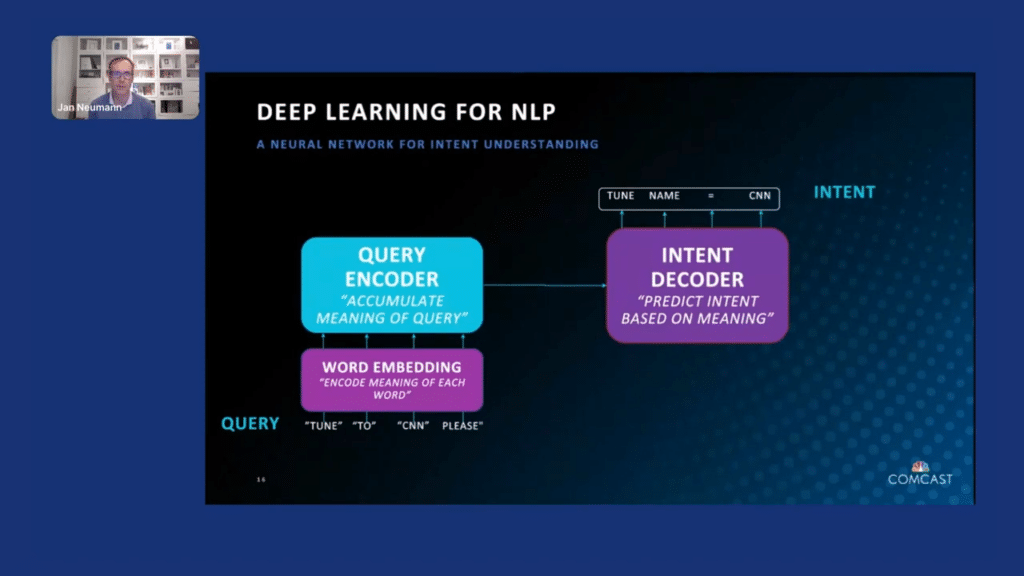
How do we solve these problems?
For the models, we are using what is very popular, a combination of encoder-decoder pattern as well as transformers. The basic idea here is that you take the sentence, “tune to CNN, please,” you encode, using word embeddings, each of these words into a vector, and then the query encoder takes these individual vectors and accumulates them together to capture the meaning of the query. We then train our intent decoder which essentially translates that query into the intent representation. So, in this case, as we indicated earlier, a “tune,” and then a parameter with the value “CNN.”
To train these models, we need a lot of data. One way you can train it is by using synthetic examples. Given that many of our queries are short, domain experts are able to write rules in template form that allow us to capture a number of the intents even without deep learning.
For example, “show me all <genre> on <channel>” should be translated to the “browse genre and channel” information. Now with these placeholders, we can use our metadata database and insert various forms, be it synonyms—for example for the genre as well as all the different channels. By creating a lot of this synthetic data, we can now train deep-learning models that are able to handle both these relatively simple use cases as well as more complex use cases.
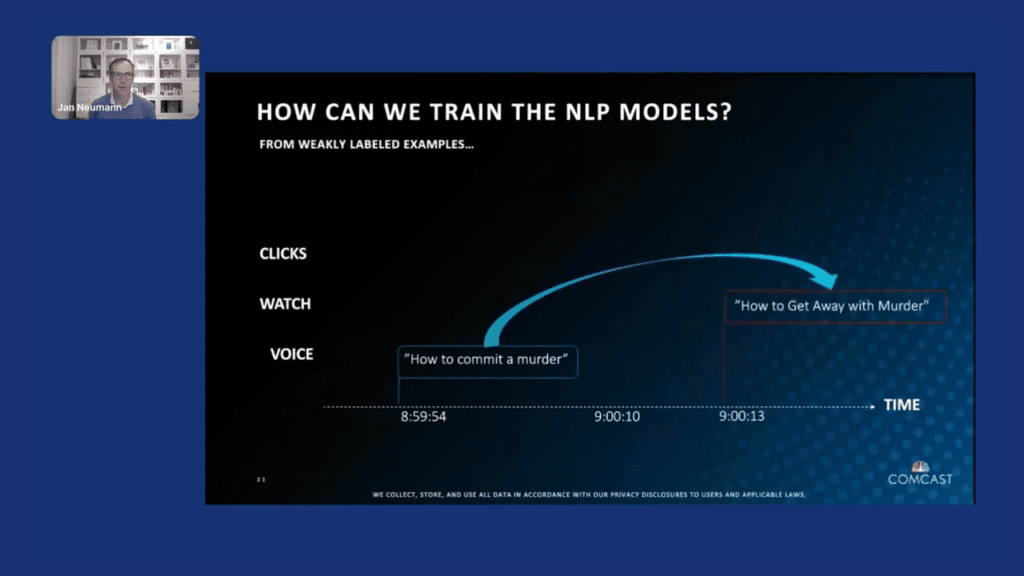
At the same time, this is not exhaustive, right? I mentioned also that we are receiving millions of queries every single day. It is not possible to annotate and verify that we capture all these patterns. We have to do some automatic training. So, how can we do that?
I want to use one example, which is a real example from our production logs, where we noticed that a number of people were asking us how to commit a murder, which is not something where (I hope) as a system, we have a good answer for. What are the customers actually trying to accomplish here, assuming positive intent?
What we then saw when we looked at our overall usage logs is that once our system did not return the desired answer, which was a TV show, they actually went into our interface and were able to navigate to the “How to Get Away With Murder” show OnDemand.
Similarly, we saw with other folks for the same query that they then used another query called, in this case, “ABC,” and then, “watch the show, How to Get Away With Murder.”
What this allows us to do now is if we are looking at our session logs, we can identify weakly labeled examples that we can then use to augment our training of our NLP models.

To do this with a weak label, we use what we call our Automatic Labeling Framework (ALF). We combine our NLP speech logs, the logs from the user interface of how our customers are navigating through our interface, we then use a session builder to create these temporally aligned sessions for our customers. And then we use the Snorkel framework with its data labeling functions to weakly label the data. Then, using that generative model, we can now apply it to a number of use cases for our system.
The easy way is that we can use it to identify positive and negative exemplars for our speech transcriptions. When did our speech system actually perform accurately and when did it not?
We can also predict the user experience. Basically, we track what we call the negative interaction score, which is if you are making a query and you are not watching something very soon after then we probably didn’t understand you correctly. Or if you have to repeat queries. In this case, if we see a query of where the customer wanted to say “Telemundo,” but we capture only the “mundo” from the speech recognition, then we would basically use a negative label and assume we had a negative experience.
Similarly, we can identify incorrect transcriptions, truncations, et cetera. For example, “dashing through the snow,” and the suggestion, “crashing through the snow,” when you said it again, would allow us to identify an error type.
And finally, we are not using any guard words in our system, so sometimes we predict that the domain for a query is incorrectly identified. So, instead of it being a TV query, if you are asking, “who’s the president of the USA,” we won’t have an answer for you in the TV domain. Instead, it should have been going to the general knowledge domain and answered there, so we can then identify what we have to improve in our domain classifier so that the mapping from the query to the domain is done correctly.
Let’s take a look at some of these sessions in detail. Here’s an example of where we started out, the first interaction was a voice query, which we transcribed and understood as “gorilla.” And then the customer pressed exit to start over. Then they said the query again and this time we got “Cruella.” And then we see the customer navigating, entering, entering, followed by “tune” to actually watch something, which we can interpret as a positive interaction, at least after “Cruella,” right? But we know that “gorilla” was not working out as planned.
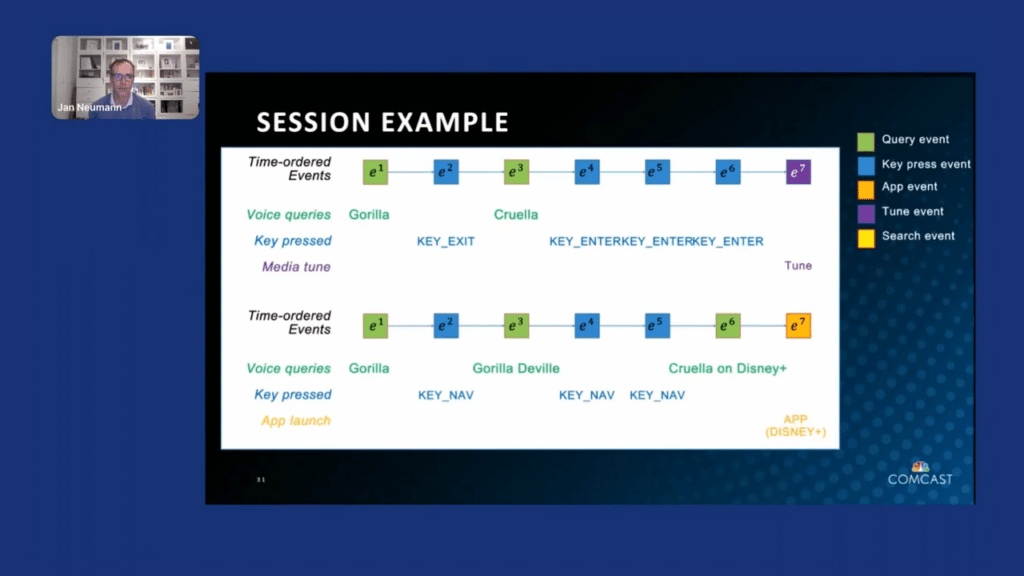
Similarly, if you navigated after that and then said “gorilla Deville,” and navigated again, and finally you were able to get to “Cruella on Disney+,” and said that again, we know that our previous recognitions, again, were incorrect, and the app launch for Disney+, we see that we were actually not linking to the correct show directly and forcing you to go into the app and find it yourself there, which is a negative outcome.

What are, now, some of the labeling functions that we came up with?
A positive label is if the query was actually completed, as I mentioned, with one of these following actions. If I have a query followed by a “tune,” an “app,” a “play” or a “volume” change, we label it as positive. If a query is followed with a text search—so instead of using voice, you actually type it into a search interface. You [then] use the menu, the tv linear guide, or a channel selection, and we did not take you there directly, then we probably got it wrong and we used it as a negative example.
If queries are repeated, then depending on how these two queries relate—if they’re the same query and/or very similar queries—then the first one would be labeled as negative. If they’re the same, if the second query was done, then the second one would be neutral-different. If we go into an app—so you give up on us finding the show, but you know on which app it is, then we would label that as negative. And if you’re, instead of looking for the show, you can now change it to another entity, like an actor or something, then we don’t quite know how to handle that. And then also if you say a query, and then you navigate after that, then at least we interpret that as getting you closer to the right outcome and label that as a positive sign.

How are we actually now integrating this into our voice architecture?
I mentioned in the beginning that we use a combination of speech and natural language understanding components to understand what you’re saying on the voice remote, but that is not enough. I already mentioned that we need a lot of training data to train deep-learning models, so we need to create data that we can then feed into our training algorithms, right? So it could be the raw data, but it’s also the training data labels, business logic, and overrides as well as ontologies that need to be input.
That data can come from external data stores. We have a central metadata service where we get, for example, our information about potential entities that we can search for in our system. We have a voice data annotation UI that allows you to manually annotate what the right interpretations of queries are. We have a content management system where we can create additional content that we might want to show. And then we also have explicit tests via QA where we can verify if our models behave correctly.
Now what we did is we basically added this automatic labeling framework as an additional input into this data store, where we take our production events as described, use the ALF framework to create the weak and self-supervised labels, and thereby augment our overall system.

Why do we go through all that trouble?
You could probably build a much simpler system if you are content with only doing exact matches, which a lot of the systems in the market currently do. You could match to the exact titles for movies and episodes, or you could only… basically match against only a fixed set of metadata tags such as comedies, horror shows, et cetera. But we are not satisfied with that. What we really envision for Voice remote is for you to be able to ask us anything and we will show you relevant results.
So, for example, you should be able to ask for movies about any place in the world, or movies about certain people, even if they’re not actors. You should be able to ask for shows about concepts such as climate change. And we should basically be able to return semantically meaningful results for you. Also, it’s often hard to remember titles exactly, especially of episodes. I never know what the title of an episode was, but I very well know what happened in it that made me remember it. If I can just describe what happened in the episode and it will bring up the correct one, that is very powerful. As we are evolving into more conversational interactions with our devices, we truly need to get to that level of semantic understanding that is necessary and automatic training is essential to make this possible.

I hope this was helpful for you. If you would like to learn more about what our team is doing, both on the Voice side and in our other domains, please check us out on our team page. I was privileged being able to present this to you, and I’m looking forward to any questions you might have. Thank you so much.
Piyush Puri: Jan, thanks so much for that presentation and thanks so much for joining me for a live Q&A now.
JN: You’re very welcome. Looking forward to your questions.
PP: Yeah, looks like the audience, has a few questions. We’ll go from the top. The first question we have is: How do you analyze journeys with greater than 10 and still find associations from happy/not-so-happy paths?
JN: With greater than the 10 steps I assume?
PP: I imagine that’s what it’s asking. Yeah.
JN: Yeah. So, the way we’re thinking about it is that we are taking all our Voice sessions, UX interactions, and then sessionize them together. The length is really not a problem. Mostly what we’re using is breaks between interactions to group different sessions together, so there’s no hard length to each of the interactions.
PP: Okay, so the next question is: How does this process scale as new TV shows/labels are added continuously? Do we adapt the model for this one class or retrain the entire model?
JN: We continuously update, so the way we do it is in a multi-step process. One is that we identify, as I described in the beginning, the intent plus parameters. We can identify parameters even if we don’t necessarily know about them, just by their position in the query itself. And then we interface with our content discovery solution to send them that name of the show, in this case, to our search system, which will then return results. And that gets updated as soon as new entries get added to our catalog. That happens throughout the day, pretty much within a few hours after they basically get submitted to us by our partners.
PP: That’s awesome. The next question we have is from Joe D.: You mentioned query encoder and intent decoder. Are you using common large-language models like BERT or GPT-3, or full transformer models like T5?
JN: Currently our model is an adaptation of the BERT model. We are currently exploring the use of larger language models such as GPT-3 and similar versions. Though for our use case, since we’re focusing on the entertainment domain, the range of speech is somewhat limited also because our queries are relatively short as they’re spoken as commands, usually. We did not necessarily need the larger language models, though as I mentioned, as we are expanding into more conversations where we want to look at the whole conversation and also take prior context into account for the resolution, we are exploring the use of GPT-3 and other larger language models for that use case.
PP: That’s very helpful. The next question is: Could you speak a little bit to the data infrastructure? How are we getting deeper tags and semantics about TV shows and movies like content and metadata?
JN: We use multiple sources. On one hand, we built an internal metadata store that includes ingesting information from various partners. It could be directly from our app partners, it could be from the Rovi or Gracenote that provide TV metadata to us. That is usually at the show level. I mentioned in the beginning that we also have an internal team that focuses on media analytics, where they analyze videos to get scene-level metadata. So: who’s on screen when, what are they talking about? And they can provide us with more detailed analysis of what’s going on in a show. Music analysis, themes, and emotions that we can incorporate into our queries.
PP: Great. We have a question that just came in: How do you manage intent conflicts as you scale?
JN: Part of it, we are validating how or if the correct intent was recognized by seeing how the customer reacts towards it. Part of the goal of identifying of negative interactions, as I called them here, is to also then forward them to our annotation team and add new intents as necessary to the models and so that we can basically add them as training data.
PP: The last one is less of a data science question and more just: how do we connect with what’s going on at Comcast? What’s the website to connect and see what’s going on with your team and at Comcast at large?
JN: Probably the easiest way to find the webpage is just to look me up on LinkedIn. I have it in my profile. We are always looking for people to want to learn more about us, and I’m happy to chat.
PP: Awesome. Thanks so much, Jan. Thank you for the presentation. Thank you for answering these questions and just being here with us today. We really appreciate it.
JN: Yeah, thanks for giving me the opportunity, and I enjoyed it.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

