
Table of contents
Large Language Models (LLMs) are redefining what’s possible across industries. They represent a significant leap forward in transforming enterprise processes and enhancing customer interactions. However, LLM evaluation poses complex challenges for enterprises who wish to deploy them.
LLMs behave differently from traditional models, meaning data scientists must assess them differently. Traditional record-by-record assessments used in machine learning don’t apply. Off-the-shelf solutions, while useful, will rarely boost an LLM system’s performance high enough to meet an organization’s production requirements. Organizations that wish to deploy customized LLM systems must instead evaluate them by scalably applying their expert’s assessment.
In this post, we’ll explore what challenges data scientists face with LLM evaluation and how to overcome them.
The challenges of LLM evaluation
For enterprises, defining what constitutes “success” for a Generative AI (GenAI) model isn’t clear-cut. Different outputs can all be correctly contextualized, making it tough to establish uniform benchmarks.
This nuance demands more sophisticated, flexible evaluation frameworks for context-specific accuracy and relevancy. Without these, enterprises risk deploying models that neither align with nor enhance their strategic goals.
These challenges demand more than simply relying on traditional accuracy metrics. Organizations must develop criteria that incorporate factors such as coherence, creativity, adaptability, and the best judgment of the organization’s Subject Matter Experts (SMEs). Each of these factors contributes to a model’s overall effectiveness, yet they are extraordinarily difficult to quantify.
Additionally, large language model failure modes pose a troubling basket of risks; an inaccurate response from a predictive model may only result in a wrong classification, but a flawed GenAI response could result in poor user experiences or misinformation. Thus, enterprises must carefully craft evaluation measures that not only address basic functionality but also the subtleties and implications of real-world applications.
Common evaluation criteria
Enterprises typically rely on a suite of common criteria to evaluate LLMs. These often include:
- Accuracy: How well does the model output match the expected content or intent?
- Compliance: Does the output adhere to regulatory and organizational guidelines?
- Safety: Is the language generated by the model free from harmful or offensive content?
- Explainability: Can the outputs be easily interpreted and understood by users?
- Robustness: How well does the model maintain performance across varying inputs?
These criteria offer a foundational approach to assessing LLM performance and are integral to fostering trust and security within AI applications. Accuracy ensures that models deliver reliable and relevant information, while compliance and toxicity controls protect user safety and align with legal standards. Explainability and robustness further enhance the user experience, enabling an understanding of model decisions and ensuring consistent performance across diverse scenarios.

Why common criteria fall short
Generalized criteria might gauge a model’s basic performance but largely ignore an organization’s specific needs and values, which can be best-assessed by the organization’s internal experts.

A customer service AI must not only produce accurate responses but also align with the company’s tone and style guidelines to maintain brand consistency. Among many other potential nuances, an organization might want to ensure a customer-facing chatbot never mentions its competitors—something generic evaluation approaches will miss. Sectors like healthcare or finance demand additional layers of compliance, empathy, and precision in communication that generalized criteria are ill-equipped to address comprehensively.
Even different business units within the same organization might prioritize different aspects of generative outputs. A marketing team might value creativity and engagement above all, whereas a legal department might focus on compliance and accuracy. Generalized criteria do not adapt to the multifaceted nature of enterprise operations, necessitating more tailored, adaptive approaches to LLM evaluation.
Generalized solutions for LLM evaluation
In response to LLM evaluation challenges, researchers and data scientists have developed useful generalized solutions, such as benchmarks and LLMs that judge other LLMs.
Benchmarks for LLM evaluation
LLM benchmarks make an LLM act like a traditional machine learning model. These systems give the model a prompt with a narrow, defined answer space and then judge whether the model responds correctly.
Researchers have developed a wide array of benchmark sets, including SuperGLUE. This set includes a variety of language-understanding tasks. Many of them ask binary questions, such as whether or not there will be a 13th season of the TV show Criminal Minds based on a paragraph about its renewal.
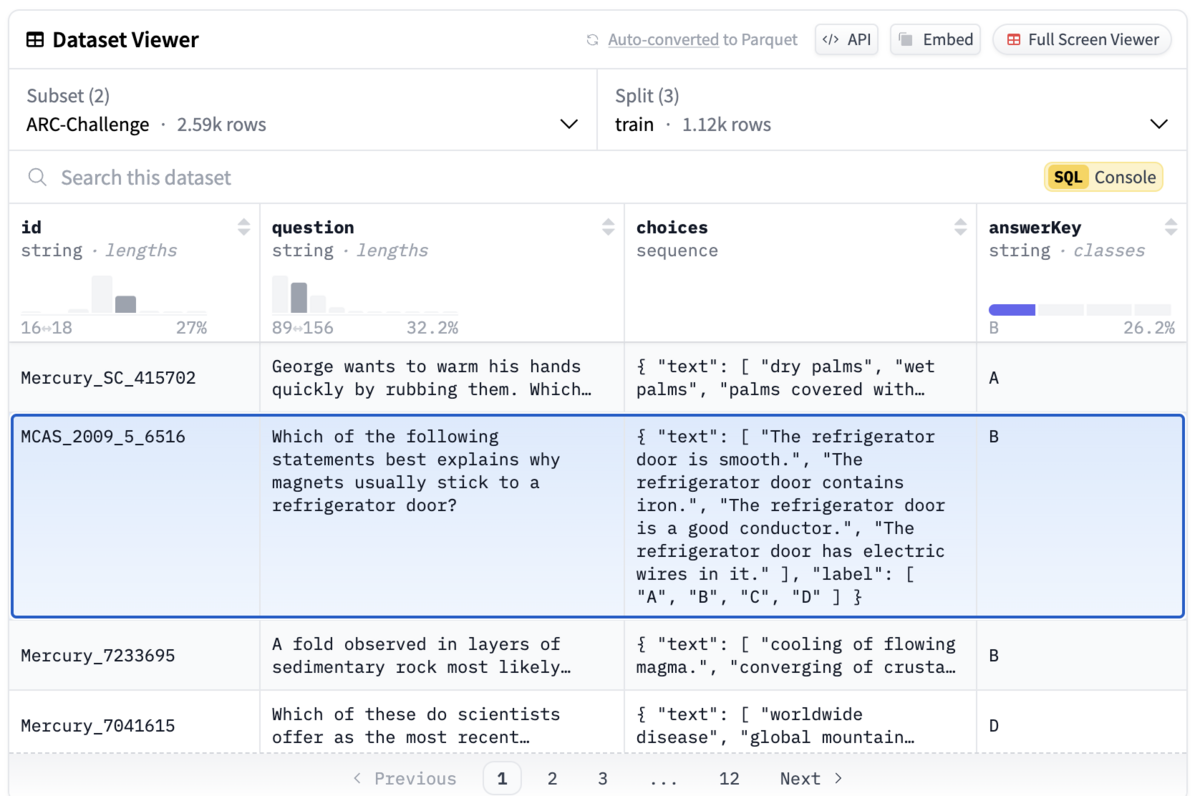
Other prompts ask multiple-choice questions or prompt the model to respond with a number between 1 and 7 to indicate how distressed an author was feeling. The numerical approach can yield more nuanced results, as it can quantify not just whether or not the model was wrong but also how wrong it was.
Benchmarks offer a clear comparative framework for establishing standards. The Holistic Evaluation of Language Models (HELM) program at Stanford has collected SuperGLUE and many other benchmarks into customizable leaderboards.
Benchmarks often serve as a starting point—a way to assess whether a model meets basic industry expectations. However, these benchmarks may not correspond directly with a company’s unique needs. To bridge this gap, enterprises must develop bespoke benchmarks for each use case they want to address.
Off-the-shelf analysis tools
Readily available models can handle some aspects of LLM evaluation that don’t fit into the benchmark format.
Hugging Face, for example, hosts many models that can evaluate text for sentiment and toxicity. Data scientists can use models like these to evaluate different foundation models and track how responses from their chosen model change as they fine-tune it or iterate on their prompt templates.
While these can serve as a useful starting point, they will likely not satisfy every organization’s needs. The marketing department for a consumer products company may have a higher bar for what qualifies as “positive” than the compliance department at a bank, for example.
Fortunately, these models can be customized to fit an organization’s needs.
LLM as judges
The LLM-as-judge approach asks one LLM to judge the output of another.
In a basic setup, a pipeline will feed a prompt to the LLM under evaluation. Then, the pipeline combines the evaluated LLM’s response with the original prompt and asks the judging LLM to assess the response’s quality.
This approach offers exciting potential because it enables greater nuance than benchmarks while also enabling high throughput. An LLM-as-judge can evaluate many prompt/response pairs in the time that it would take a human to judge just one.
While powerful, the resulting judgments reflect the limitations and biases inherent in the judge LLM’s training data and instructions. Snorkel AI researchers once experimented with improving the performance of a 7-billion parameter open-source LLM through an approach called “direct preference optimization” (DPO). Their model soared up the AlpacaEval leaderboard. However, their analysis revealed that their Snorkel-Mistral-PairRM-DPO model achieved its success in part by accidentally exploiting the judge LLM’s biases. The judge preferred longer answers, regardless of whether the additional content added greater understanding.
Like benchmarks, off-the-shelf LLM-as-judge setups can help guide an organization’s choices when choosing and customizing a model, but they are unlikely to elevate a model to production quality.
Moving to custom LLM evaluation
When generic LLM evaluation approaches reach their limit, enterprise data scientists must shift their approach to custom evaluation methods.
Regardless of what customized approach you use, it should be well grounded in feedback from and collaboration with appropriate subject matter experts.
Customized LLM-as-judge
Data scientists can customize their “judge” LLM through one of two approaches:
- Fine-tuning: Adjusting an LLM to be better at judging other LLMs.
- Prompt iteration: Crafting and re-crafting an appropriate prompt template to induce reliable judgments from a foundation model.
For many organizations, working with SMEs to craft the right prompt template will succeed in directing a full-sized frontier model to reflect the SMEs’ judgement closely enough to serve as a reliable proxy. This may be more work than it sounds like, but less work than fine-tuning a customized judge model.
Quality models
At Snorkel AI, our researchers and engineers have also tried the “quality model” approach.
In this approach, data scientists collaborate with subject matter experts to label a corpus of prompt/response pairs as accepted or rejected on specific criteria. With the dataset assembled, the data scientists can train a small neural network to act as the SME’s proxy.
Our researchers and engineers enhance this process by adapting SME’s explanations into scalable labeling functions. This amplifies SME impact while minimizing the amount of time they must dedicate to the project. Data scientists can achieve a similar approach with standard manual labeling, but they may struggle to secure sufficient SME time for this approach.
Quality models can assess responses holistically or on specific aspects—format or tone, for example. Holistic quality models offer a lot of power as a headline approach, but some teams may want to add one or more narrowly focused quality models to address specific LLM performance complaints.
Data slices and the need for fine-grained evaluation
In addition to evaluating LLM responses according to an organization’s specific needs and standards, they should also parse this evaluation according to specific tasks the organization cares about.
At Snorkel, we create detailed “data slices” by labeling prompts according to what kind of task they represent. This segments data into relevant scenarios—for instance, inquiries in Spanish or requests to cancel a customer account. Such fine-grained analysis unveils strengths and deficiencies that generalized assessments might miss, providing a clearer picture of a model’s suitability across varied contexts.
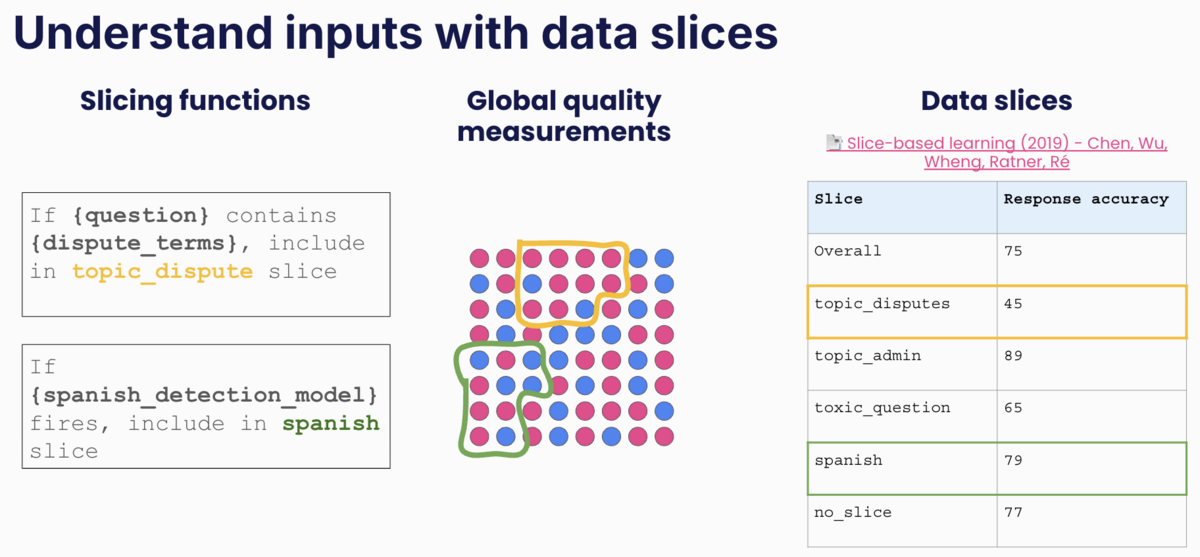
By focusing on specific segments and scenarios, enterprises gain actionable insights that can be used to fine-tune models and improve outcomes. In practice, this means leveraging frameworks like Snorkel Flow to customize criteria and model parameters, creating tailored evaluation processes that reflect an organization’s core objectives and operational intricacies.
From LLM evaluation to actionable insights
Ultimately, evaluations must do more than diagnose; they must provide actionable insights that drive continuous improvement. Knowing where a model falls short is not enough; enterprises need pathways to address these gaps effectively. Actionable insights form the bridge from evaluation to development, allowing teams to implement strategic improvements. Snorkel Flow not only emphasizes identifying these insights but also facilitates the creation of actionable workflows that integrate seamlessly with enterprise objectives.
As LLMs carve out an increasingly significant role in enterprise applications, understanding and implementing robust evaluation frameworks grows more important. By moving towards specialized, task-driven evaluation methods crafted in deep consultation with SMEs, organizations can better harness the transformative power of LLMs, ensuring alignment with their unique needs and strategic goals.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Matt Casey
Data Science Content Lead
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

