
The introduction of ChatGPT in November 2022 upended the AI landscape. Corporate leaders soon urged data science teams to use large language models (LLMs), and data science teams turned to fine-tuning and retrieval-augmented generation (RAG) to mitigate generative AI (genAI) shortcomings.
Professionals in the data science space often debate which approach yields the best result. The answer is “both.” Neither fine-tuning nor RAG requires excluding the other, and the two approaches work better together.
To use a metaphor, a doctor needs specialty training (fine-tuning) and access to a patient’s medical chart (RAG) to make a diagnosis.
Let’s take a look at how each approach works, and why to treat them as collaborators rather than rivals.
GenAI challenges to solve
Generative AI is the most impactful technology of the last decade, according to Gartner, but the field is still in its infancy. Generative models available today present a number of challenges—some of them significant.
- Out-of-date information. At the time of this writing, ChatGPT warned users that its pre-training data contains no information after September 2021. Updating a pre-training corpus requires a lot of time and effort, and likely won’t be a regular process for the foreseeable future.
- Lack of domain knowledge. Generative applications built atop foundation models (FMs) often contain a wealth of general knowledge but struggle with tasks focussed on narrow domains or specializations.
- Hallucinations. Generative models respond confidently at all times, even when their pre-training data does not cover the topic at hand. The models sometimes fabricate plausible nonsense, which can lead users astray.
- Poor performance on specific tasks. Generalist models handle an impressive spread of tasks surprisingly well. But they may struggle on specific tasks important to particular data teams.
Researchers have investigated solutions to these challenges, and have developed several candidates—the most prominent of which are retrieval augmentation and fine-tuning.
Fine-tuning
Fine-tuning adapts the LLM’s weights to custom domains and tasks.
Data scientists feed the model a collection of prompts and expected responses. The model learns the gaps between what it currently produces and what the training pipeline expected and adjusts its “attention” to specific features and patterns.
For example, if a data team wants to use an LLM to examine financial documents—something the model may perform poorly on out of the box—the team can fine-tune it on something like the Financial Documents Clustering data set.
Fine-tuning mitigates underperformance for the target domain and task(s). It can also help the model overcome some of its biases and limitations, such as hallucination, repetition, or inconsistency.
In a past experiment, Snorkel researchers working with academic partners at Stanford and Brown found that a fine-tuned RoBERTa model significantly outperformed zero-shot prompts on an off-the-shelf version of GPT-3.
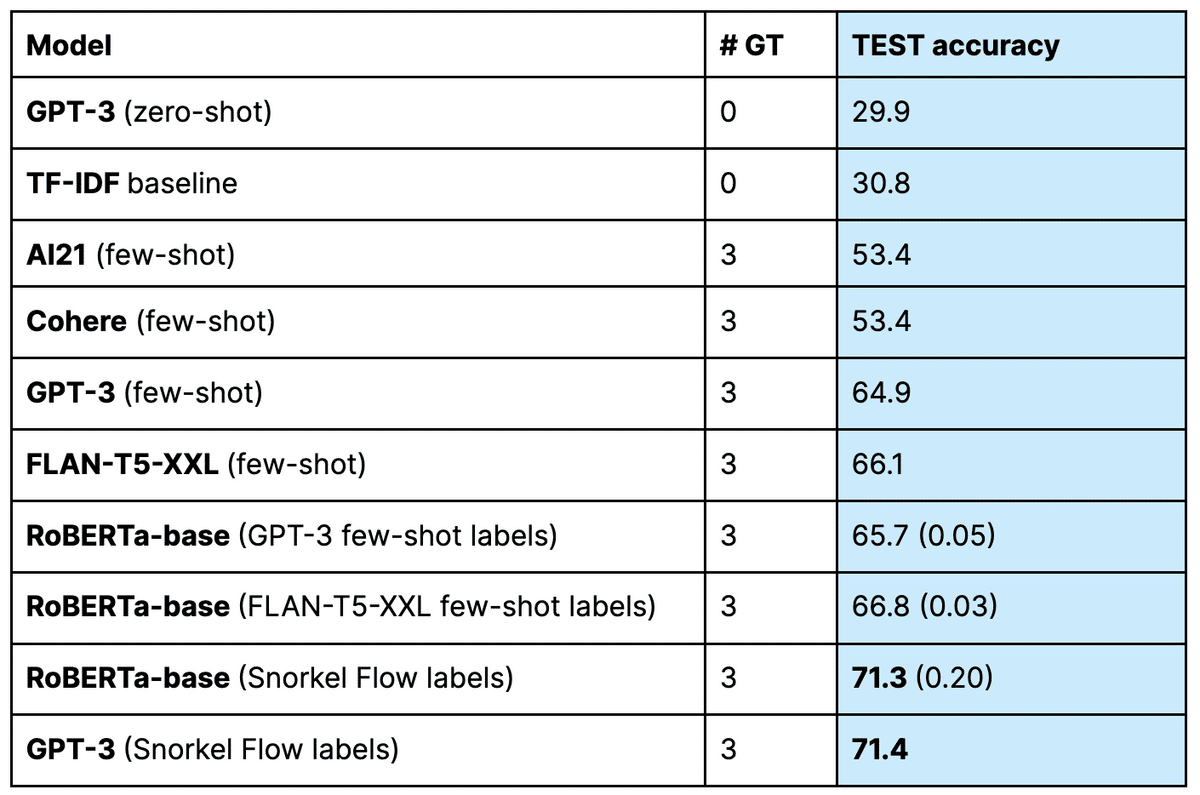
However, fine-tuning requires a large amount of labeled data, which may be scarce, noisy, or expensive to obtain. It also requires significant computational resources, which could present a significant hurdle.
Retrieval augmented generation (RAG)
Retrieval augmented generation inserts an additional step between users’ requests and the generative model.
In this step, the pipeline finds information relevant to the user’s request and injects it as context. For example, Google’s Bard and Microsoft’s Bing Chat perform traditional search queries relevant to the user’s prompt before feeding the search results as additional context to the LLM.
This information could come from:
- A vector database such as FAISS or Pinecone.
- Traditional databases such as SQL or MongoDB.
- APIs such as those for Google Maps or IMDB.
- A search engine such as Google or Bing.
RAG mitigates the challenge of out-of-date pre-training data by providing up-to-date information at inference time.
While quantifiable real-world examples are hard to come by, the results from the original paper the proposed RAG (Retrieval-Augmented Generation fo Knowledge-Intensive NLP Tasks, Piktus Et al.) remain compelling.
In a head-to-head comparison, human testers were shown a subject and presented with two Jeopardy-style questions that the subject would answer. The interface asked the testers which question was more factual. They rated answers from the RAG-enhanced model as factual 54.4% of the time compared to just 18.8% of the time for the non-RAG model.

However, RAG presents its own pitfalls. Effective RAG implementations require an efficient and effective mechanism to retrieve the correct context. Improperly implemented RAG tools can negatively impact responses by injecting irrelevant information—or, worse, it could surface sensitive information that should have been kept confidential.
Fine-tuning vs. RAG
Retrieval augmentation and fine-tuning address different aspects of LLMs’ limitations.
Fine-tuning outperforms RAG when addressing slow-to-change challenges, such as adapting the model to a particular domain or set of long-term tasks. RAG outperforms fine-tuning on quick-to-change challenges, such as keeping up with incremental documentation updates or records of customer intersections.
These approaches are neither mutually exclusive nor incompatible. In fact, they can be combined to achieve better results.
For example, imagine a customer support chat copilot. When agents require guidance during live interactions, they prompt the copilot, which triggers the following process:
- The pipeline retrieves essential customer information, including the customer ID.
- The pipeline queries the customer’s history, issues, policies, special circumstances (e.g., outages), current support team availability, and other dynamic external variables.
- The pipeline consolidates the gathered context and the original query into a final prompt.
- The model generates a response grounded in the provided context.
While this pipeline could use an “off-the-shelf” model, the style of the generated response may vary and deviate from internal policies or end-user requirements. To improve the likelihood of consistent, helpful responses, the data team can train a “specialized” copilot model.
The data team would start with an appropriate foundation model, such as Llama 2 or GPT-3.5. Then, they would build or curate a corpus of examples of likely inputs (context + prompt) and ideal outputs (including desired formatting) for each specific task type the model will regularly encounter. This could include separate approaches for tasks that customer service agents would handle themselves (such as reactivating an account) and tasks that involve guiding the user through actions on their side (such as troubleshooting a problem).
In this instance, fine-tuning and retrieval augmentation work hand-in-hand to deliver the right solution, faster.
Fine-tuning and retrieval augmentation: a powerful pair
Fine-tuning and RAG are not rivals, but complementary techniques that collaboratively enhance LLMs. Each has its own goals, mechanisms, advantages, and disadvantages, but they also synergize and benefit from each other.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Hoang Tran
Senior Machine Learning Engineer
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor’s degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

