Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Snorkel AI FAQ
Browse through these FAQ to find answers to commonly raised questions about Snorkel AI, Snorkel Flow, and data-centric AI development. Have more questions? Contact us.
Programmatic labeling
- What is a labeling function?
- How does the labeling function know what the label should be?
- What is the output of a labeling function?
- What happens when labeling functions generate conflicting labels?
- How is writing labeling functions different from feature engineering?
- How do you know how many labeling functions are enough?
- Do labeling functions have to be created through the UI?
Use cases
- What kinds of problems are the best fit for solving with Snorkel Flow?
- Does Snorkel Flow work with structured data (CSV, tabular data, etc.)?
- Does Snorkel Flow work with semi-structured data (PDF, website, etc.)?
1. What is a labeling function?
A Labeling Function (LF) is an arbitrary function that takes in a data point and outputs a proposed label or abstains. The logic used to decide whether to label and what label to output can be based on any number of things—existing resources (e.g., noisy labels, other models, ontologies, lookup tables, etc.) or newly captured heuristics from subject matter experts. This ability to reuse existing resources, combine them, and build on them means that many labeling problems being tackled with Snorkel Flow can begin with a “warm start” incorporating prior work that is then added to and refined to drive model quality up further. As an additional benefit, those existing resources can now be up-weighted or down-weighted intelligently and automatically based on what the label model learns about their relative accuracies, correlations, areas of expertise, etc.

Some simple examples of the kinds of labeling functions that you could write for an email spam detector
2. How does the labeling function know what the label should be?
Labeling functions are an expression of subject matter expertise captured in code. Every labeling function is based on an existing resource or user-provided heuristic. Thus, rather than attempting to create labels automatically on their own (in what would amount to something like a free-energy machine), labeling functions provide a flexible abstraction for integrating and reasoning about many potential sources of information about a problem, making it easier to rapidly build new training sets and machine learning models in a way that is scalable, adaptable, and auditable.
3. What is the output of a labeling function?
The input to a labeling function is a data point and the output is either a proposed label for that data point or a sentinel value such as None or “ABSTAIN” that indicates that the LF abstains. LFs do not output confidence values—the magnitude of the effect each LF should have on a data point’s final aggregated label will instead be automatically learned by the label model.
4. What happens when labeling functions generate conflicting labels?
It is common and entirely expected for labeling functions to output conflicting labels at times. In fact, they may even make correlated errors, not cover all the data, be more accurate on some classes than others, etc. And in most cases, we don’t actually have the ground truth label for our training examples. But we can use theoretically grounded and empirically proven mathematical methods to identify optimal ways of combining these noisy supervision sources to create high-quality labels nonetheless, and now at a much greater scale and with much lower cost than doing so manually. This is also in contrast to rule-based systems, where the strategy for resolving every potential rule conflict must be explicitly enumerated ahead of time.
The model that we use to solve this problem of resolving LF conflicts is called a label model. It’s important to note that there are many such models that we could use for this problem. Over the years, the Snorkel team has proposed different models and algorithms that make different assumptions and work best in different scenarios. Some of our early work is available in papers (e.g., NeurIPS 2016, ICML 2017, AAAI 2019, etc.), but none of these is “the Snorkel label model” any more than the final model architecture we choose or the LF templates we use. They are each just different choices for a single component in the framework. Today, Snorkel Flow includes the world’s most comprehensive library of label model algorithms, with all the above plus additional work from the past couple of years, including algorithmic, speed, and stability improvements. Importantly, these label models do not require ground truth to learn how to best combine the weak labels, though they can all take advantage of any available ground truth labels if provided.
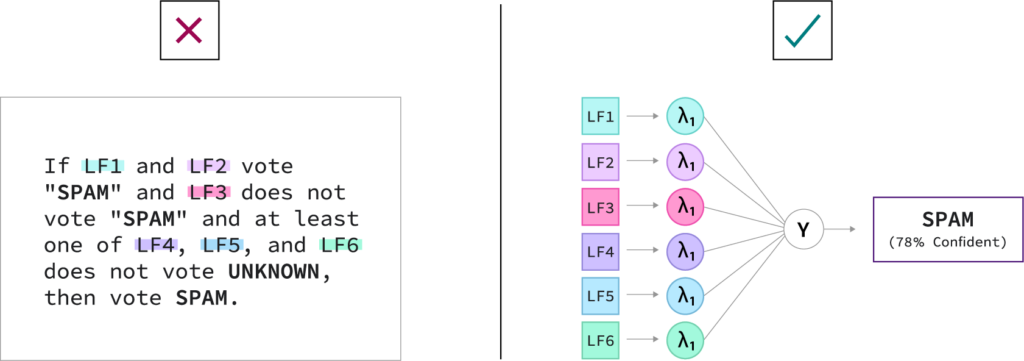
Rather than having to specify exactly how to deal with every potential conflict between labeling functions, Snorkel Flow allows you to dump them all into a single model that automatically learns how to combine them optimally using unsupervised techniques (no ground truth labels required).
5. How is writing labeling functions different from feature engineering?
There are some similarities between feature engineering and writing labeling functions with Snorkel, but important differences as well.
Feature engineering used to be absolutely essential for many applications. In the past decade, much of that burden of feature development has been replaced by deep models that are able to automatically learn high-quality features from the data, especially for unstructured data like text and images. In either case, these features can now be utilized by a classifier, but labeled training examples are still required to learn how to weigh and combine these features.
Labeling functions, on the other hand, are used for creating labeled training sets, orthogonal to what model you train or what features you use. LFs may reference existing features (e.g. an existing “column” in your data) or describe new ones (either in code or via one or more built-in LF templates) and can be thought of as a specification of a feature plus a prior on what class or classes that feature is most often associated with. By default, labeling function outputs are not passed through to the final ML model—this is one nice way to force the model to generalize and take advantage of many features in the training set rather than relying on only those that were referenced by labeling functions. Regularization can also help with this objective, reducing the amount of weight that can be given to any single feature, regardless of how correlated it is with the training labels.
6. How do you know how many labeling functions are enough?
The decision to author more LFs, edit existing ones, or stop iterating on your dataset altogether should be guided by analysis of your latest model. The recommended best practice is to create a minimal set of LFs (e.g., one per class), train a first model, and then begin iteratively improving your training set from there. Snorkel Flow provides multiple types of analysis tools and in-app guidance to highlight where programmatic labeling efforts should be focused so that user time is most likely to result in model improvement. Active learning is one of these tools available to the user, but with an input that now allows the user to much more rapidly update training labels (labeling functions as opposed to individual labels).
In contrast with a labeling pipeline where labels are collected before any labeling begins, this allows the user to avoid wasting time providing additional labels where they’re not needed (e.g., where the model is already performing well). For the same reason, users should not attempt to create every labeling function they can think of before training a first model.
7. Do labeling functions have to be created through the UI?
Labeling functions can be created either in the UI (using no-code interfaces or low-code DSL) or the integrated notebook environment (using raw code with a simple decorator). Once created, all labeling functions are interoperable and can be viewed and reasoned about together throughout the app. Labeling functions created in the UI can be exported as JSON-like config objects that correspond to the available user controls in the UI. These configs can then be inspected, modified, and optionally uploaded back to the application to be viewed in the UI in their modified state if desired.
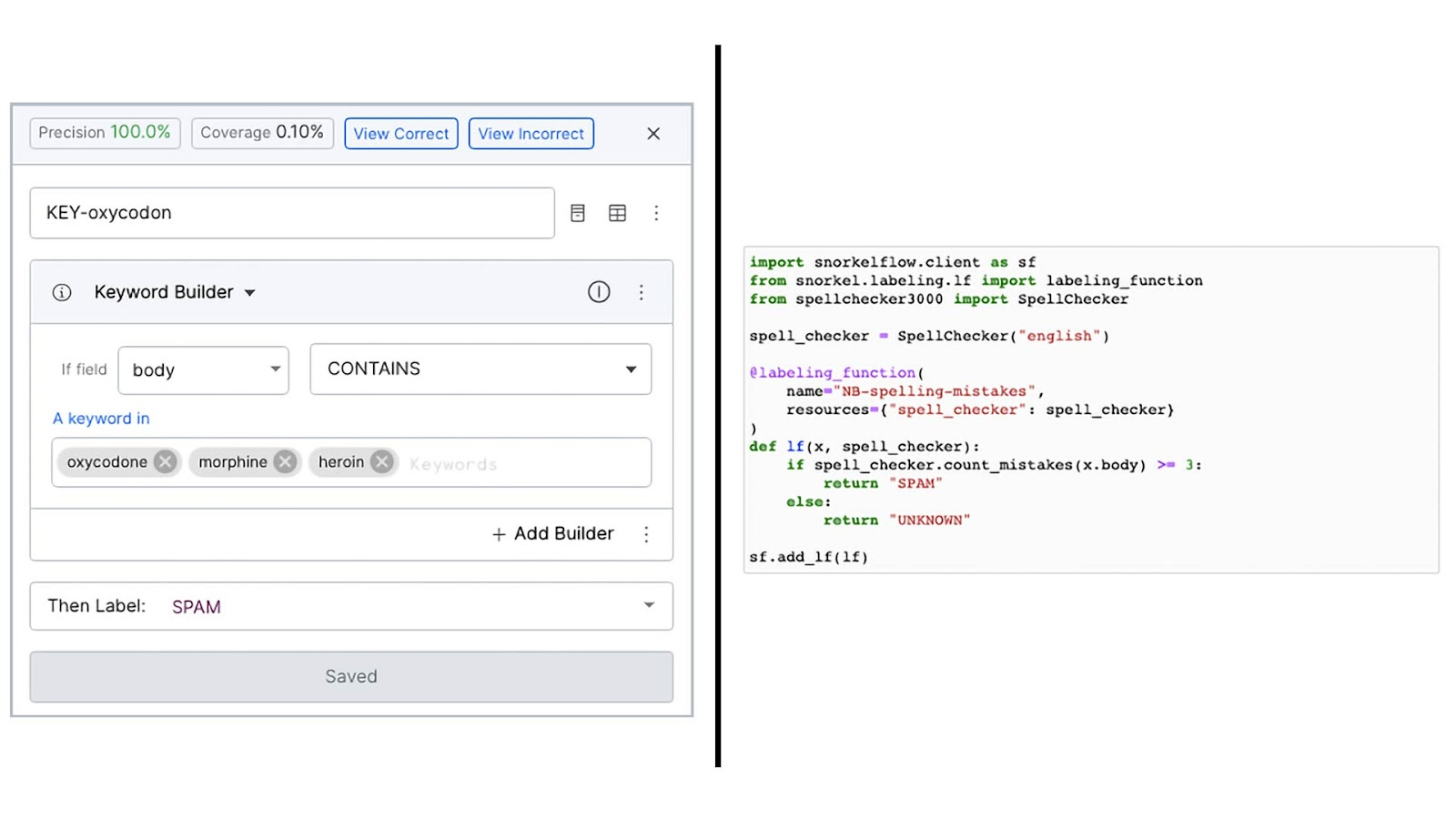
Labeling functions can be created using no code (via templates in the GUI), low-code (with a lightweight DSL) or custom code (in the integrated notebook environment). Once created, all LFs are fully interoperable throughout the platform.
8. What kinds of problems are the best fit for solving with Snorkel Flow?
Snorkel has been applied to a huge variety of problem types over the years by the Snorkel team and the border data science and ML engineering community (see our research papers for some published examples). In short, nearly any machine learning application that utilizes labeled data can benefit from using Snorkel Flow and its data-centric approach to generate those labels.
Enterprises often get the highest return on investment when any of the following are true:
- Your task would benefit from larger training sets. With Snorkel, your training set size is only limited by how much raw data you have (which can be programmatically labeled), rather than by how much manual labeling you can afford to do.
- Your training data needs to be created quickly. With Snorkel, labeling functions label at the speed of computer rather than the speed of humans, so once a set of labeling functions exist, the labeling process itself is quite fast (usually on the order of seconds or minutes, depending on how much data you have and how computationally intensive your LFs are). This allows for datasets to be created quite quickly.
- Your labels need to be updated often. There are many reasons for updating training labels. Some of these include adjusting to observations about your data, clarifying edge cases, reflecting changing requirements, adjusting label schema to add or remove classes, adapting to data drift over time, responding to adversarial adjustments (such as spam detection), etc. In any of these cases, having the ability to regenerate the entire training set with the click of button after making any necessary adjustments—rather than relabeling from scratch or reviewing each individual label generated manually—results in potentially multiplicative savings as you avoid having to pay labeling costs repeatedly with each change.
- There are limits on who can label your data. For tasks where relatively few people can label the data (e.g., due to expertise constraints such as tasks labeled by doctors, lawyers, analysts, underwriters, or other professionals; or due to privacy constraints such as the data needing to remain in-house or requiring a certain level of security clearance), labeling via LFs can dramatically increase the amount of labeled data that can be created by a single individual. As a bonus, the fact that a single individual can now label where previously large teams were required can result in more consistent labels across the dataset.
- Your training labels or models need to be auditable. In many regulated industries (finance, insurance, etc.), models and sometimes training data need to undergo review processes where they are assessed for risk and bias. Programmatic labeling provides a new level of transparency into exactly how your training labels were created, by whom, when, using what features, etc. Unlike labeling decisions made entirely in annotators’ heads, labeling functions explicitly encode the factors used to decide how data is labeled. Snorkel Flow effectively provides a full “bill of materials” and fully version controlled assets behind every label, training set, and model. This can significantly simplify the model risk management process and reduce risk for companies deploying those models.
9. Does Snorkel Flow work with structured data (CSV, tabular, etc.)?
We have seen Snorkel used quite effectively with structured datasets—especially for problems where deep expertise is required to label, labels are updated frequently, or complex relationships are present that require large data to learn sufficiently. Labeling functions can refer to specific columns or combinations of columns using a variety of built-in templates (e.g., an LF template that accepts SQL queries is a common choice for these types of problems) or custom LFs, and common models for structured data such as XGBoost are readily available in-platform. However, for some structured problems—particularly those with relatively few parameters to learn and more static requirements—a rich set of features and a relatively small labeled dataset will suffice. In those cases, we recommend simply using the Annotation workspace in Snorkel Flow to create the required labels. Should you decide to transition to a programmatic labeling workflow in the future for any number of reasons, those manual labels can easily be reused to warm start your new training set which you can then build upon with additional labels or labeling functions.
10. Does Snorkel Flow work with semi-structured data (PDF, website, etc.)?
Snorkel Flow does support ML tasks (classification, extraction, NER, etc.) from semi-structured data such as PDFs or websites. In addition to the normal data viewers, LF templates, and models for text data, Snorkel provides access to a rich library of features that utilize spatial and structural information from the data, such as page number, font size, visual alignments, location on the page, etc. These features can be used to easily express additional types of LFs relevant to your problem and to provide relevant features to your ML model for training.
Have more questions? Contact us.
This FAQ is not a comprehensive list. Snorkel AI will continue to update this page ad-hoc.

Team Snorkel