100x
Category
Research
Our picks
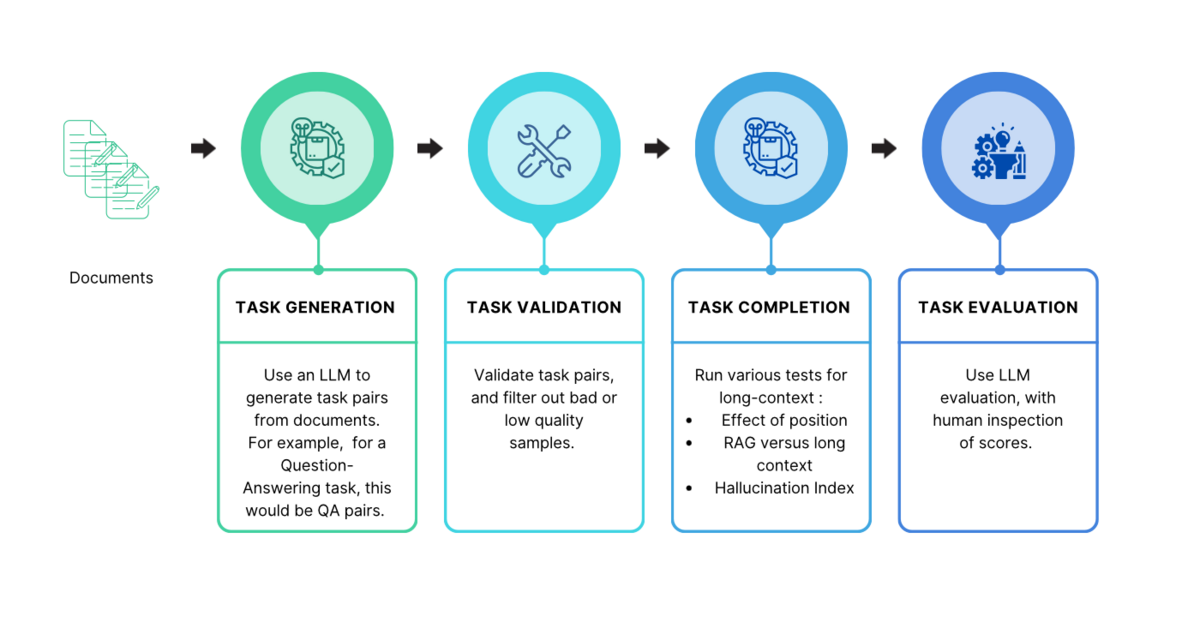
Long context models in the enterprise: benchmarks and beyond
Snorkel researchers devised a new way to evaluate long context models and address their “lost-in-the-middle” challenges with mediod voting.

Snorkel AI researchers present 18 papers at NeurIPS 2023
The Snorkel AI team will present 18 research papers and talks at the 2023 Neural Information Processing Systems (NeurIPS) conference from December 10-16. The Snorkel papers cover a broad range of topics including fairness, semi-supervised learning, large language models (LLMs), and domain-specific models. Snorkel AI is proud of its roots in the research community and endeavors to remain at the forefront…
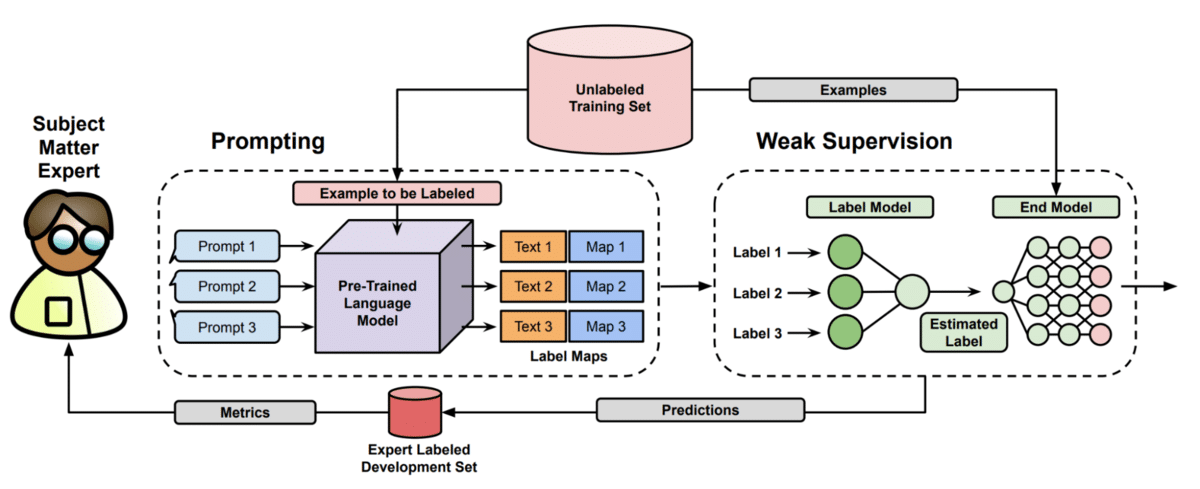
Getting better performance from foundation models (with less data)
Getting better performance from foundation models (with less data)
Recomended for you
Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench…
Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated…
Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can…
All articles on
Research

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench…

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated…


Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can…

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated…


Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration…


Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that…

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based…

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with…

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —…



Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
At our latest Snorkel AI Reading Group, Yijia Shao (Stanford NLP) stopped by our San Francisco office to present Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration. As LLM agents get better at automating tasks on their own, a large class of real-world problems still needs a human in the loop – for their preferences, their domain expertise, or simply for control….

Benchtalks #2: The future of coding benchmarks
For our second Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with John Yang, a Stanford PhD student and creator of the SWE-bench franchise, SWE-smith, CodeClash, and most recently ProgramBench. Highlights More on ProgramBench: See the benchmark and the upcoming leaderboard at programbench.com. More from John Yang: Publications and writing at john-b-yang.github.io. Snorkel…

Code World Models and AutoHarness for LLM Agents
At our latest Snorkel AI Reading Group, Carter Wendelken of Google DeepMind walked us through two related papers he presented at ICLR: Code World Models for General Game Playing and AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness. Both ask the same question from opposite ends: when you want an LLM to act reliably in a complex, possibly…


Why coding agents need better data, evals, and environments
Coding agents have moved from tab-complete to teammate. They autonomously inspect repositories, edit files, run commands, diagnose failures, and work through multi-step engineering tasks. That creates a harder reliability problem. A model that only suggests code is easy for a human to evaluate. A coding agent refactoring your repository and testing its own changes is much harder to supervise –…


Understanding Olmix: A Framework for Data Mixing Throughout Language Model Development
At our latest Snorkel AI Reading Group, Mayee Chen (Stanford, Hazy Research) stopped by our San Francisco office to walk us through Olmix: A Framework for Data Mixing Throughout LM Development — work she contributed to during her internship at Ai2 on OLMo 3. Olmix tackles one of the messiest, least-documented levers in LLM pre-training: how to set the ratios…

Benchmarks should shape the frontier, not just measure it
Since launching the Open Benchmarks Grants, we’ve received more than 100 applications from academic groups and industry labs spanning a wide range of domains and capabilities. As the best benchmarks drive how the field allocates research effort, the bar for benchmarks has risen as well. Here, we share what’s now table stakes for useful benchmarks, and what separates the ones…

See how Snorkel can help you get up to:
Faster data curation
40x
Faster model delivery
99%
Model accuracy