
The following was originally published on Wayfair’s tech blog. We have cross-posted it here, edited only to fit Snorkel’s formatting guidelines.
—
One of our missions at Wayfair is to help our 22 million customers find the products they are looking for. For example, when a customer searches for a “modern yellow sofa” on Wayfair, we want to show the most relevant options from the tens of thousands of sofas available in our catalog. To do that, it is important to have a strong understanding of the products we sell. We use machine learning algorithms to analyze and understand the descriptive information (e.g. color, shape) of over 40 million products provided by more than 20 thousand suppliers in our catalog.
What are product tags?
We use product tags to organize and store descriptive information about our products. These tags capture specific attributes of each product, such as its color, design, and pattern, in a structured manner. This allows us to provide targeted search results to our customers. For example, when a customer searches for a “modern yellow sofa,” only products that have “color” tagged as “yellow” and “style” tagged as “modern” will be displayed in the search results. Moreover, we use product tags to enhance customer-facing experiences such as personalized recommendations and marketing campaigns.
We currently have more than 10 thousand product tags to describe over 40 million products in the catalog.
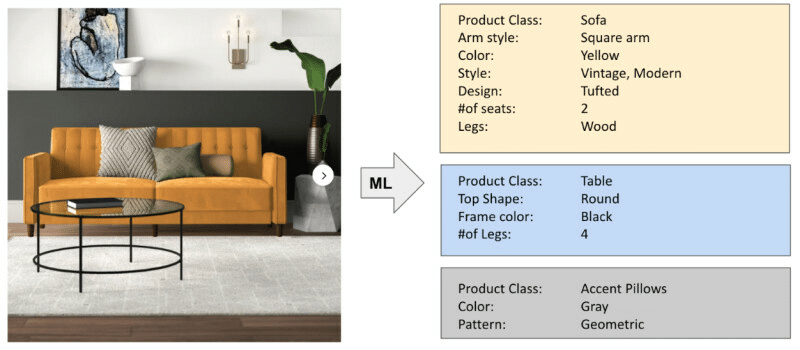
Figure 1: We store a variety of different tags for each product
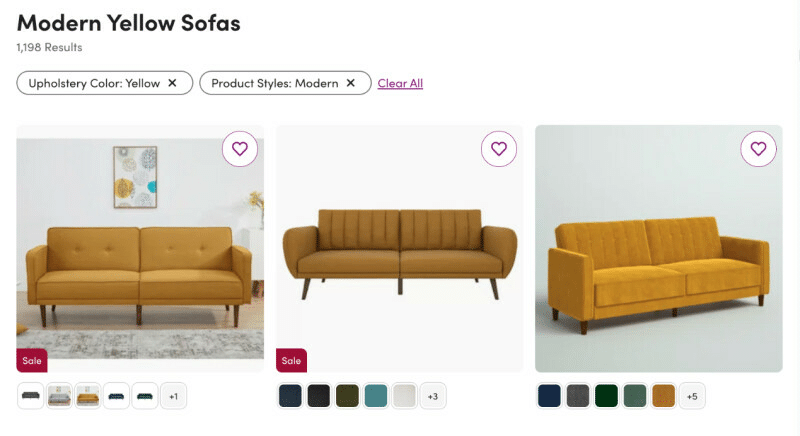
Figure 2: We then use product tags to power how customers can search and filter products. Example above shows results for “modern yellow sofa”
We develop machine learning algorithms to extract product tags from images which are available when suppliers upload products to our catalog. With this effort, we aim to obtain comprehensive and accurate information about our products and simplify the product addition process for suppliers while ensuring that customers can easily find what they are looking for and trust what they receive is what they purchased.
The challenge of manually tagging products
Without Machine Learning, we would have to rely on suppliers or human agents for product information. This information is then used to show relevant products to customers. But there are some challenges with this approach.
First, this manually provided information is:
- Inconsistent, where one supplier calls a sofa ‘red’ while another calls it ‘orange’
- Inaccurate – dimensions of a chair may be incorrect because the width and height measurements are flipped
- Incomplete, with a supplier only providing a basic color name “blue sofa” instead of a more granular color name such as “cerulean sofa”
This means that customers have a less than ideal experience trying to find the right product. For example, a customer may order a chair that doesn’t fit their space or can’t find the right color they want. Second, asking dozens of questions for each product can be a laborious and time-consuming process for our suppliers.
Extracting product tags from imagery: challenges faced

Figure 3: Visual tags describe products on features like Design, Pattern, or Subject/Theme
Many tags in our catalog describe visual characteristics of products, such as design, pattern, and theme. Examples of design-related tags include “Barrel Chair,” “Wingback Chair,” and “Curved Sofa.” Meanwhile, pattern-related tags include “Chevron Rug,” “Striped Curtain,” “Floral Accent Pillow,” etc. Examples of theme-related tags include “Outer Space Rug,” “Bird Decorative Object,” etc.
We began by developing a suite of deep learning models trained on Wayfair imagery that can extract these product tags at scale. However, we have thousands of tags and building models for these tags requires a large amount of labeled data for training and highly curated ground truth data for evaluation. We initially relied on two sources: supplier-provided labels and labels annotated by human agents. However, these sources have their limitations. Supplier-provided labels might be incorrect, or the supplier might not provide tags at all. On the other hand, hand-labeling thousands of tags is time-consuming, difficult to modify with changing taxonomies, and not the best use of human agents’ time.
Limited success with off-the-shelf foundation models
To unblock ourselves from the requirement of a large amount of hand-labeled training data, we then experimented with an off-the-shelf foundation model, CLIP, for zero-shot image retrieval tasks.This worked well for some of the tags such as the subject of a piece of Wall Art (Animal, Nature, etc.), which covers less than 5% of the product tags. But, it did not work for most of the Wayfair catalog specific tags (e.g. style, design, product types, shape, pattern, season etc.) due to two main reasons. First, the highly confident predictions were still inaccurate. Second, the off-the-shelf model was not able to provide all required tags. We still needed a better way to solve our need for high quality training data and expedite our model development process.
Enter the Wayfair x Snorkel AI computer vision design partnership!
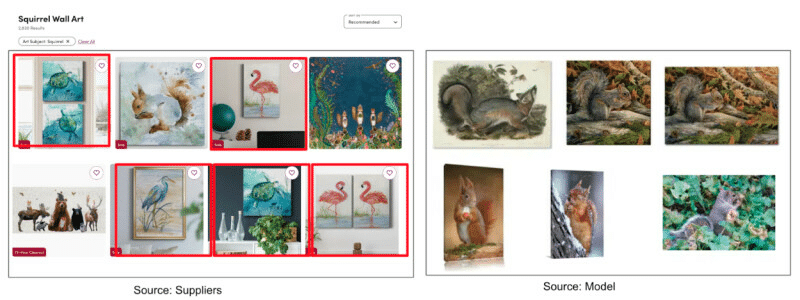
Figure 4″ Tagging the “subject” of the wall art as “squirrel”: Using off-the-shelf CLIP model, accuracy improved by more than 50 percentage points

Figure 5: Tagging the pattern of accent chairs as “Chevron”: Off-the-shelf CLIP model cannot distinguish between “Chevron” and “Geometric” very well.
Wayfair x Snorkel computer vision
Snorkel’s main product, the Snorkel Flow platform, enabled our data scientists to use an iterative process to programmatically label large sets of data leveraging foundation models and weak supervision rather than manually hand-labeling every data point. Snorkel has helped many Fortune 500 companies build NLP models to solve their bespoke business problems. With this partnership, Snorkel expanded on their core data-centric development offering and applied it to computer vision workflows, piloting their new capabilities with our product tagging use case.
Snorkel’s computer vision workflow for tagging
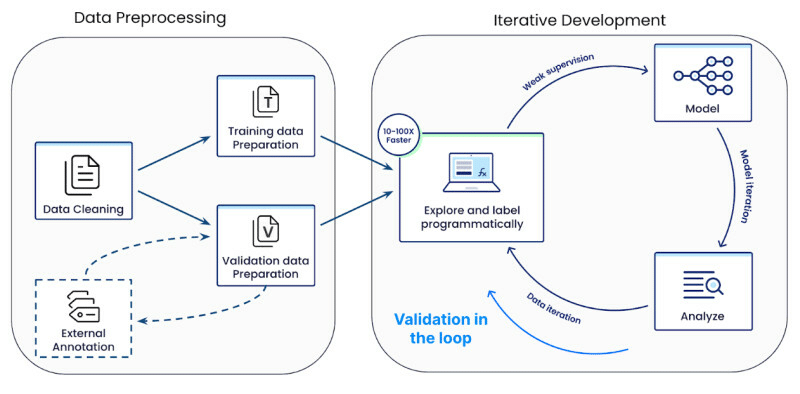
Figure 6: Snorkel’s computer vision workflow for Data preprocessing and iterative model development
We collaborated with the computer vision research team at Snorkel and discussed our challenges with the quality of our training data. During our partnership, we also uncovered additional data quality issues with our dataset such as “duplicate images” and “outlier images – images that are incorrectly associated with products.” The Snorkel team designed a workflow that included (1) Data Preprocessing (2) Iterative Model Development steps to solve these challenges, enabling us to quickly curate vast amounts of training data in minutes instead of the weeks and months required for manual data annotation.

Figure 7: Duplicates and outliers in the catalog data
The “Data Preprocessing and Curation” step ensures the high quality of initial training and evaluation datasets.
- Data Cleaning: We encountered quality issues on our data, such as duplicate and outlier images. The Snorkel workflow included deduplication feature that prevents overlapping samples in the training and evaluation dataset and outlier removal step which ensures that datasets only contain relevant images associated with valid products.
- Training/Validation data preparation: Preparing training and validation data is critical to ensure the quality of the trained model and we did not have a representative validation set for any given tag. The “validation data preparation” feature in the Snorkel workflow allows for the sampling of a validation set using a combination of uniform, stratified, and similarity-based sampling methods. These samples are then sent to human agents/subject matter experts for labeling. This feature helps create a validation set that has high coverage and diversity, ensuring the quality of the trained model.
“Iterative Development” is the next step that enables us to efficiently label visual data and iteratively build better models. The key features include:
- Explore and label programmatically: This involves creating labeling functions with prompts ( text or images) using pre-trained foundation models. For example, by providing a prompt “Chevron area rugs,” we can generate thousands of labels that can be further filtered with human supervision.
- Model: Another feature is the denoising model, which helps to clean up the labels generated by combining the labeling functions via label model. We can then train a model (e.g. “Chevron” or “Not Chevron”) using the resulting de-noised labels.
- Analyze: This feature enables us to visually analyze the failure modes of the model on the validation data (e.g. “Geometric” pattern mistakenly tagged as “Chevron”) which allows us to iteratively obtain richer training data (e.g. add geometric accent chairs as negative labels) to create better models.
- Validation in the loop: Prior to our design partnership with Snorkel, labeling the validation dataset using only human agents (HITL) came with a large amount of upfront effort. This involved preparing training materials, training and managing the human agents, and still, there were quality issues in the validation dataset. Snorkel’s “validation-in-the-loop” feature enables subject matter experts (e.g. Merchants or Category managers) and data scientists to rapidly correct errors or augment the validation dataset as necessary, addressing these challenges.
In this two-step, iterative workflow, we start with Wayfair specific product images and relevant metadata, and very quickly, we can get the labeled training data as well as models trained on a specific tag (e.g. “Chevron” pattern or not).
Results
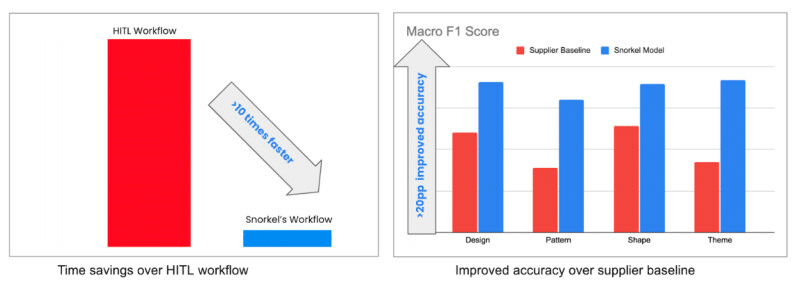
Figure 8: Results from the design partnership. Large time savings and accuracy improvements over our baselines.
The results from this design partnership were quite promising. Some highlights include:
- Accuracy improvements over our baseline model (using supplier labels): We trained the models on labeled training data using Snorkel’s platform and compared with baseline models trained with supplier-provided labels. We saw consistent improvements on models across design, pattern, shape and theme tags over the supplier baseline. We were able to improve F1 scores by 20 percentage points or more.
- Massive time savings over Human-in-the-Loop (HITL) workflows: We compared the time it takes to build and iterate models using a manual labeling workflow vs Snorkel’s iterative approach starting with the same data for one tag (Area rug pattern) and found that we were able to achieve the same or better accuracy 10 times faster by leveraging Snorkel Flow. These time savings will be compounded as we scale training to thousands of tags allowing us to get models in production in months compared to years it would take with HITL workflows.
- Iterative workflows: Tags and searches from customers evolve over time, and updating a model to adjust to these changes is a time consuming and a manual task. With the iterative, data-centric workflow that Snorkel Flow provides, it becomes easy to add a new tag, or to modify an existing tag, enabling catalog backfills or clean ups at scale in a rapid and cost effective manner.
Results on Chevron pattern tag:
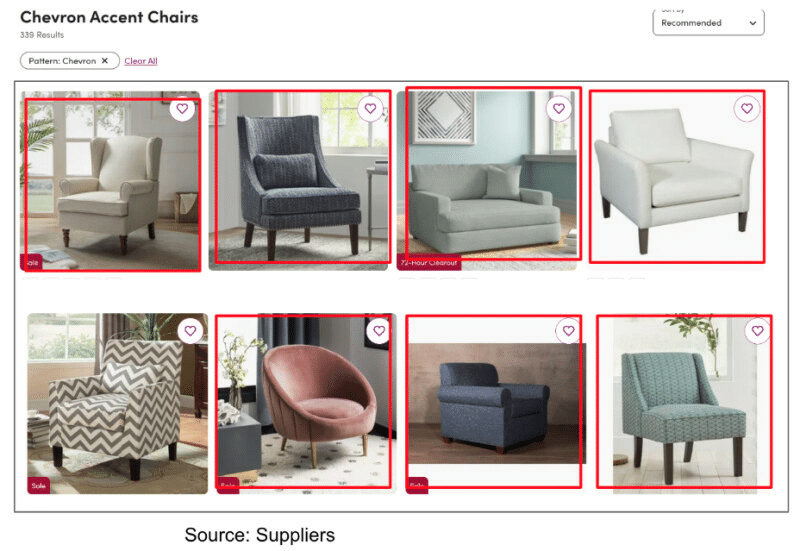
Figure 9: Results from the first page on Wayfair website for “Chevron Accent Chairs”. These are based on supplier-provided product tags

Figure 10: Examples of results for “Chevron Accent Chairs” based on model. Accuracy improved by more than 20 percentage points
Accurate models enable us to provide more relevant products for customers, so that when they are looking for a “chevron accent chair” or a “yellow modern sofa”, they find just what they need. We are also able to provide this experience sooner compared to using HITL workflows. This translates to better customer satisfaction and potentially increased revenue for the company. We currently leverage labeled data from Snorkel’s platform and train the models in-house. We then deploy them in our orchestration platform built on Google Cloud. In the future, we will launch an A/B test to understand the impact of our models in a customer’s journey.
The future of the partnership
As we continue this partnership, there are two avenues we are most excited about.
- Leverage new features and capabilities for various use cases:
- Object Detection and Segmentation – In order to get better at extracting information from parts of the product images (for example frame color, upholstery color, arm type, number of products) we are currently exploring object detection and segmentation capabilities.
- Fine-tuning foundation models – While foundation models have certainly shown great promise, they are inherently limited by the data they have been trained on. We would like to fine-tune foundation models with Wayfair datasets (e.g. text-image pairs) to improve their representations. This should enable us to have even faster model iterations and more accurate models.
- Using generative AI for iterative labeling & model building – One area of future work would be leveraging generative AI models to create synthetic data. With Snorkel Flow we can use data-centric methods to see where we may have gaps in our training data. For example, if we do not have enough examples of floral accent chairs in our dataset, we can use generative AI to create more training examples. In the future we hope to add generative models in the loop to let us programmatically shore up these weak points.
- No Code/Low code ML development and deployment across Wayfair: We would like to include Snorkel Flow in our enterprise MLOps workflows that includes data processing, training/evaluation, deployment, and monitoring across Wayfair so that subject matter experts and operators can automate tagging with no or minimal code. This will help subject matter experts realize value without the bottleneck of our ML teams’ bandwidth.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Archana Sapkota
ML Manager
Archana is an ML manager at Wayfair. She leads automation of catalog tagging to make sure the information about products in the catalog is rich and clean—a crucial task to help customers find what they are looking for via search, filter, recommendation, etc. She has also led projects to provide personalized experiences to customers by providing visual similarity-based recommendation and browsing experiences. Within Wayfair, she is recognized as an expert in computer vision.
Recommended articles
View all articles

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

