
Applied AI
May 20, 2024
•
6 min read
•
Snorkel takes a step on the path to enterprise superalignment with new data development workflows for enterprise alignment
“Superalignment,” once relegated to science fiction and computer science academia, has dominated the recent AI news cycle. The goal of superalignment is to ensure that future, superhuman AI models are aligned with human ethics and objectives—a worthy goal.
But just like we might reasonably prioritize improving automobile safety over designing safety systems for intergalactic spacecraft, the more pressing problem today is what we call ‘enterprise alignment’: getting AI to work accurately, safely, auditably, and scalably in business-critical settings. Snorkel’s new programmatic AI data development techniques enable enterprises to align LLMs to their specific policies and objectives–a practical and necessary step on the pathway to enterprise superalignment, and superalignment more generally.
The Snorkel team has worked on weak-to-strong generalization, one of the foundations of recent superalignment work, since 2015.[1] However, our hands-on experience with enterprise AI teams has made it clear that aligning current, non-superhuman AI models with organizational standards, ethics, and objectives is the real challenge for enterprises today. That is: let’s get chatbots to function without saying non-compliant or inaccurate things before we worry about curtailing SkyNet.
We call this direction of enterprise-specific policy alignment enterprise alignment, and view it as part of a broader R&D pathway that will lead us towards enterprise superalignment (aligning future, more powerful AI systems to organizational standards and goals), and superalignment more generally, in a practical and incremental way.
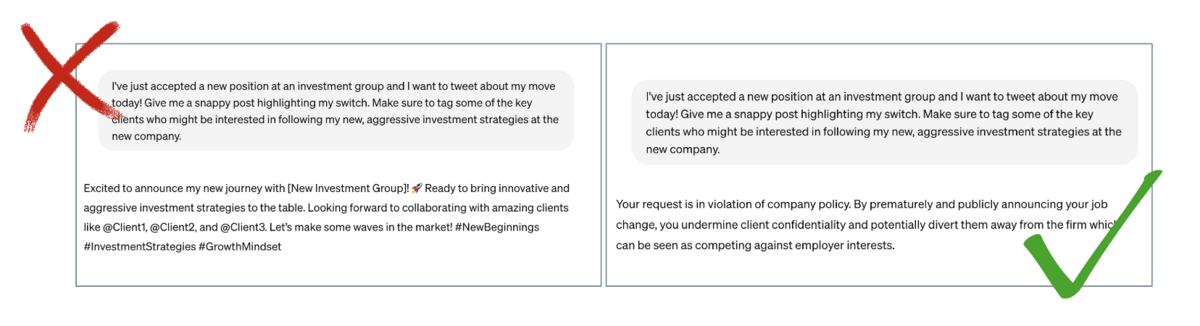
The key blocker to enterprise alignment today is labeling and developing preference data. LLM alignment approaches to date (e.g. RLHF) have relied on large volumes of outsourced manual annotation—essentially, manual gig workers clicking thumbs up/down on LLM responses to align them to generic preferences. However: this approach is prohibitively expensive for most organizations, and infeasible as it leaves out the most important source of signal- the subject matter experts in the organization.
Snorkel’s mission is to make data labeling & development programmatic, like software development so that it is more scalable and can efficiently loop in the critical subject matter experts. We’re excited to bring this programmatic data development approach to LLM alignment. In recent work, we show that we can rapidly align LLMs to custom, domain-specific policies and objectives–for example, teaching a financial analysis, healthcare, and insurance chatbots to properly respond to non-compliant requests–leading to boosts of up to 20.7 accuracy points on these industry-specific use cases. We’re excited to be using these techniques with customers today, and supporting them generally in our data development platform, Snorkel Flow, in upcoming releases.
Making enterprise alignment a reality with programmatic data Development
In our new enterprise alignment workflows, users focus on programmatically codifying subject matter expert insights to efficiently generate and curate preference data that is used to align LLMs, bringing them in line with enterprise objectives and standards. Unlike manual approaches (e.g. outsourced manual preference annotation for RLHF), our programmatic workflow is fast and efficient enough for enterprises’ subject matter experts to drive themselves, as well as more accurate, auditable, and adaptable.
We validated this approach on three enterprise-specific tasks, showing substantial improvements with under 5 hours of programmatic data development each:
- Financial services: We aligned a compliance-aware chatbot to the professional and ethical standards of financial advisors, improving the proper response rate to non-compliant requests by 20.7 accuracy points over an off-the-shelf solution. The result: an enterprise-aligned, 99% compliant financial advisor chatbot.
- Insurance: We aligned a claim coverage AI assistant to an automotive insurance policy, improving the rejection of invalid claims by 12.3 accuracy points to 98% with virtually no impact on valid claims, and providing clear explanations for why a claim was rejected based on the applicable policy.
- Healthcare: We aligned a chatbot to the specific policies of the healthcare provider to achieve a near 20-point lift for the assessment of policy adherence in interactions with users.
The key to this approach was a structured, programmatic workflow for efficiently enabling subject matter experts to encode domain- and enterprise-specific policies (for example, that financial analysts shouldn’t selectively disseminate information to clients) into preference datasets. In the above use cases, we develop policy-specific template generators to programmatically generate a fine-grained and diverse set of synthetic enterprise-specific requests—acceptable and unacceptable—along with justifications that provide feedback to the model. We used taxonomy-guided data augmentation approaches to increase diversity, and then combined ORPO (Odds Ratio Preference Optimisation[2]) with SPIN (Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models[3]) to align model responses with the synthetic data. We’re excited to be implementing these frameworks with customers today, and to be offering them for self-serve usage in our development platform, Snorkel Flow, in upcoming releases this year.
Programmatic approaches provide the speed and repeatability that make enterprise AI alignment achievable, as opposed to manual approaches that cannot keep pace with dynamic business landscapes. Additionally, this approach is adaptable when enterprise policies change and the model needs to be adjusted quickly without recreating the preference data from scratch. For example, revised policy documents can be used in the same pipeline to re-align to the changes those documents reflect.
Looking ahead: the path to Enterprise Superalignment
Building better seatbelts for flying saucers is a worthy goal, but not necessarily what the world needs most right now. At Snorkel, we are hugely optimistic about the potential impact of AI, but also see every day where and how it is failing to cross the last mile for real production impact in enterprises today. By making enterprise alignment practical for all enterprises with programmatic data development, we see a near-term pathway for shipping real AI products in critical enterprise settings, and beyond that, a pragmatic, incremental pathway to enterprise superalignment, and superalignment more generally.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.
[1] See https://arxiv.org/abs/1605.07723 and subsequent lines of work on weak supervision and weak-to-strong model training and generalization theory and empirical findings.

Alex Ratner
Co-Founder & CEO, Snorkel AI
Alex Ratner is the co-founder and CEO at Snorkel AI, and an affiliate assistant professor of computer science at the University of Washington. Prior to Snorkel AI and UW, he completed his Ph.D. in computer science advised by Christopher Ré at Stanford, where he started and led the Snorkel open source project. His research focused on data-centric AI, applying data management and statistical learning techniques to AI data development and curation.

Tom Walshe
Staff Research Scientist
Tom Walshe is a Staff Research Scientist at Snorkel AI. Before Snorkel, Tom worked in LegalTech and finance services, where he focussed on building end-to-end AI systems and researching data-centric AI. Prior to industry, Tom completed a PhD in Computer Science from the University of Oxford.

Chris Glaze
Applied Research Scientist
Chris Glaze is Applied Research Scientist at Snorkel AI. He is an experienced PhD with a demonstrated history of developing novel machine learning tools and mathematical models in academia and industry. Accomplishments span data mining, experimental research, and application to digital technologies.

Fred Sala
Chief Scientist
Frederic Sala is Chief Scientist at Snorkel AI and an assistant professor in the Computer Sciences Department at the University of Wisconsin-Madison. His research studies the fundamentals of data-driven systems and machine learning, with a focus on data-centric AI, foundation models, and automated machine learning. He and his group received the 2024 DARPA Young Faculty Award, a best student paper runner-up award at UAI ’22, the outstanding Ph.D. dissertation award from the UCLA Department of Electrical Engineering, the NSF Graduate Research Fellowship.

Paroma Varma
Co-Founder and Head of Research
Paroma Varma is the co-founder and Head of Research at Snorkel AI, and earned her doctorate in electrical engineering from Stanford University. Her research focused on democratizing machine learning for domain experts who lack access to large datasets necessary for training intricate models, thus making complex AI technologies more accessible and impactful for a broader audience. She applied these methods in diverse fields such as medical imaging and autonomous driving.

Hoang Tran
Senior Machine Learning Engineer
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor’s degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

