
Snorkel AI co-founder and CEO Alex Ratner recently interviewed several Snorkel researchers about their published academic papers. In the video above, Alex talks with Brown University Computer Science Assistant Professor (and Snorkel collaborator) Stephen Bach, about the work he did with BigScience on improving and refining foundation models like GPT-3 with curated task-specific data. Below follows a transcript of their conversation, lightly edited for readability.
Stephen Bach: Thanks so much for having me, Alex. My name’s Steve Bach, I’m a snorkel researcher and I’m also an assistant professor of computer science at Brown University.
Alex Ratner: Awesome. Today we’re talking about a pretty big paper in terms of waves that have been made, usage in the open source and number of authors. So this was the, yeah. “Multitask Prompted Training Enables Zero-Shot Task Generalization.” This is at ICLR this year and was a collaboration amongst a ton of different organizations.
Steve, you were one of the lead researchers, you wanna kick it off just by sharing a little bit about the paper, the model, and the overall kind of community effort here?
SB: Yeah, absolutely. So this paper was a great community effort among many collaborators in the BigScience workshop, particularly Victor Sanh, Albert Webson, Colin Raffel, and Sasha Rush, the other lead contributors to this.
The goal of this paper—and this entire project—was to investigate how to improve prompting. Prompts are natural language representations of queries. They can look a lot like questions you might ask a human annotator, like “what is the topic of the following article?” Prompting has gotten really popular in the last couple of years, particularly with the rise of large foundation models like GPT-3.
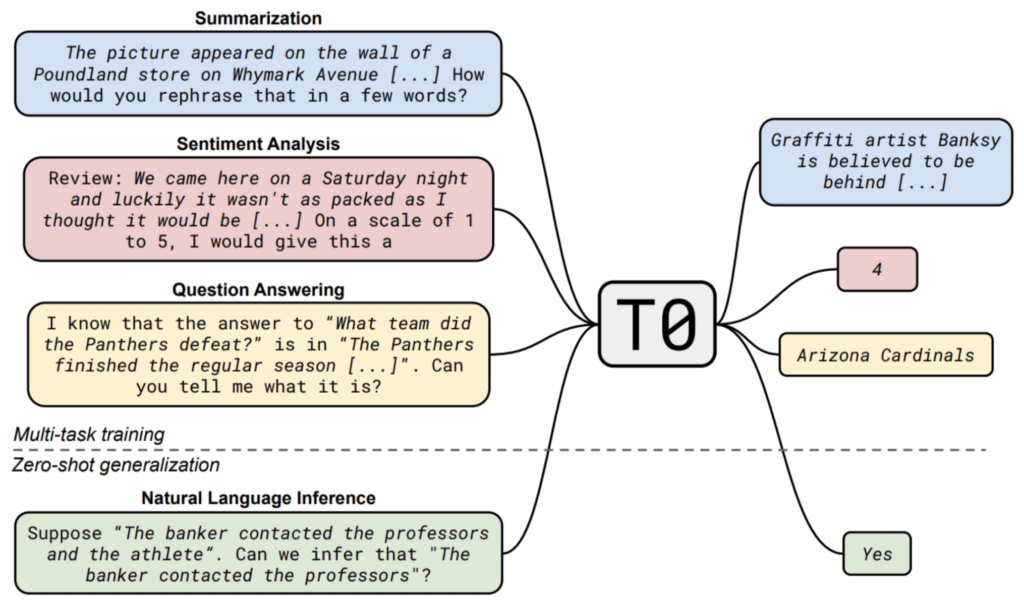
We wanted to look at how we could improve this method of prompting for tasks that haven’t been seen before—in other words, for tasks that we don’t have any training data for. That’s sometimes called zero-shot learning or zero-shot inference.
How could we improve this process, particularly for models that are smaller than the scale of GPT-3? Could we improve this process for models that could fit on a single node?
AR: That’s awesome. You were able to get a model that was 16 times smaller than GPT-3 that outperformed it on a bunch of benchmark tasks by curating a multitask training data set. I’m being overly reductive, but—just at a high level—it’s a pretty interesting and relevant idea as we see so many more of these foundation model innovations come from something around data curation or development.
One follow-on to this work that I’m curious about is what you think this translates to in practice. I think all of the base foundation models are gonna incorporate some supervised data. One route is maybe every foundation model that comes out—open-source, closed source—includes not just self-supervised training, but also multitask, supervised training.
Another version is everyone starts doing their own multitask supervision specific to their data set, their organization, their types of tasks, and curating these big databases like you all did. Multitask supervision becomes part of the edge that people have in building their own foundation models.
Where do you see this kind of playing out from this work that you did?
SB: Yeah, I think that’s a great summary, and absolutely the big idea of this approach was, in my opinion, very data-centric. Prior to this work, the goal was just to make the language models bigger; do self-supervised learning on more and more data.
Many works that have come out since then have really followed this direction of saying: “Okay. To get the best performance—to really adapt these foundation models in order to better align them with what people want them to do—we want to further train them on data that looks more like the task that we want them to eventually perform on.” And so I think the trajectory is going to be increasingly specialized. It’s interesting to see how there are almost family trees of models.
We have T5, for example, which T0 was descended from because T5 was trained in a self-supervised way. Then we fine-tuned in on what we call P3, this big collection of prompts, and now people are further fine-tuning T0 using other types of techniques, incorporating things like co-training, semi-supervised learning, and additional curated data.
All of these things get added onto the foundation, if you will. And I think that is going to be increasingly important. In our research, we’re looking at how to get that additional knowledge, domain expertise, whatever it is into that foundation so that when I prompt my model to solve new tasks, it can better answer those queries.
AR: Yeah. That’s fascinating, man. That family tree idea that you have this kind of hierarchy of specialization. You start with the self-supervised base, then maybe you have self-supervision on sub-domains like legal documents. PubMed GPT just came out from the CRFM (Center for Research into Foundation Models) at Stanford. Then you have multitask-supervised descendants like in your paper.
It’s maybe daunting, but also fascinating and exciting. Think of how many combinations there are of potential multitask data sets to train your model on. It’s not just “look, we just train on this dump of data and it works.” Now you have all the combinatorial blow-up of different kinds of training tasks that you could put together to then further train it. It opens up this whole space of how to craft these foundation models.
Maybe one quick tack-on: what was your experience of working in this very kind of open-source, community-centric way versus a solo team, closed-source kind of project?
SB: Yeah, I think it was a lot of fun. I haven’t worked on a project with quite that many different collaborators, but I think it really complimented what we were trying to do in terms of collecting a diverse set of training data so that the model would better respond to a wide range of test queries.
We had lots of people—universities and other institutions all around the world—contributing their ways of phrasing tasks to the training data. So, not only was it a lot of fun, and it was really cool to meet all of these new people, but I think it actually also made the work a lot better.
AR: That’s awesome. I guess we have to wrap here. I could go on and on about this work, which I think is just objectively so exciting. But again, really exciting themes around how—obviously compute scale up and data scale up and architecture innovation is always gonna be a critical piece—but how important the dataset curation is. Both the unsupervised data, but in the case of your work, the multitask supervised dataset curation specific to the kinds of domains and tasks you’re looking at. And that obviously a great data-centric punctuation on the current data foundation model.
So Steve, thank you so much for taking the time.
SB: Thanks Alex.

Recommended articles
View all articles

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

