
Utilizing large language models as zero-shot and few-shot learners with Snorkel for better quality and more flexibility
Large language models (LLMs) such as BERT, T5, GPT-3, and others are exceptional resources for applying general knowledge to your specific problem. Being able to frame a new task as a question for a language model (zero-shot learning), or showing it a few examples to try and emulate (few-shot learning), has proven to be incredibly effective on some of these larger pre-trained models. The information that is captured by these LLMs, which can then be queried directly, is remarkable to see in cherry-picked examples 1.

Then again, they often also encounter failure modes that can seem comical to us humans.

While these LLMs clearly contain a lot of useful information embedded in their pre-trained weights, they are typically insufficient as a full solution out of the box. This can be due to gaps in their knowledge, or a lack of ability to sufficiently transfer what they do know to the task at hand.
A natural question then arises: is there a way to take advantage of what LLMs do know in these settings without having to “settle” and just accept the areas where they fall short?
In this post, we briefly outline and present some empirical results for what we have found to be the most effective framework: applying language model knowledge via weak supervision.
We find that over four academic datasets from the WRENCH benchmark, treating our best LLM as a labeling function in a weak supervision framework and combining it with other (human-generated) labeling functions outperforms:
- using the LLM directly as a predictor (41.6% error reduction), suggesting that the other LFs help to correct or fill in gaps of the LLM
- using human-generated LFs alone (20.1% error reduction), suggesting that the LLM does indeed provide useful additional information to the problem
Why combine language models and weak supervision?
There are many ways to apply LLMs to an ML problem.
One option would be to use the model as is for zero-shot predictions. This is very simple from a training perspective, as no training occurs! The downside is that the model will almost certainly achieve lower quality overall without any additional attention toward improving it on the task at hand (and the results we share later in this post confirm this).
A second option is to fine-tune the LLM using a labeled training set. This comes with two difficulties:
- Getting labeled training data. One of the reasons why zero-shot and few-shot learning have gained such attention in the ML community is because they sidestep what many have found to be the primary bottleneck in building ML solutions—labeling training data. To label a non-trivial amount of data often requires a non-trivial amount of time, money, and effort from subject matter experts.
- Training and deploying the model. Large language models are large—so large that they are often unwieldy to train on lots of data. (In fact, some LLMs are so large that their weights can’t even all fit in memory at the same time on most machines! 2) They can also be difficult to serve, depending on the hardware, memory, and latency requirements in a production serving environment.
When LLMs are used instead in a weak supervision framework such as Snorkel, the challenges above are naturally addressed:
- The language model is now being used as a noisy source of supervision (to be combined with other complementary sources) rather than the final model, so it’s ok if it’s used in a zero-shot or few-shot fashion where not all gaps in its knowledge have been “patched” with manually labeled examples
- If the LLM is being used in a zero-shot manner, then no further training of that large model is required.
- The large language model’s knowledge can be utilized without requiring the final model that gets deployed to be a large language model of that size, effectively decoupling the decision to utilize a rich (but massive) model’s knowledge from a commitment to deploy the same massive model in your production environment.
For an overview of how weak supervision with Snorkel works, we recommend starting here. One of the great advantages of that framework is that new sources of supervision (even ones that are expensive to run or rely on external resources like LLMs) easily fit within the abstraction of a labeling function, making it easy to regularly fold in state-of-the-art techniques and models into new or existing pipelines based on that framework.
Experiments with large language models
Over the past few years, we have seen LLMs used to great effect by researchers and practitioners alike in a variety of verticals and on a variety of tasks (text classification, sequence tagging, relation extraction, etc.). In this post, we use some of the relatively “small” LLMs (BERT-base and BART-large) on a set of public datasets as a simple illustrative example of the types of trends we have observed in practice on a larger scale.
We start by using BERT as a zero-shot classifier. No additional training data—just immediate predictions for new tasks. We then show how even just a handful of relevant training examples (a few-shot learning setting) can help BERT to become a significantly stronger contributor, though the benefit of additional data points quickly peters off. Finally, we look at a version of the BART model that has been pre-trained on entailment tasks in order to make it a better zero-shot classifier without the extra labeled data burden of a few-shot model. The model is then pre-trained to predict whether the hypothesis is “entailed” by (i.e. logically follows from) the premise.
For each of these settings, we compare the performance of using the LLM classifier directly, using a set of human-generated LFs to create a training set for a RoBERTa model to learn from, and using the combination of an LLM LF plus human-generated LFs to create a training set for the same model.
All human-generated LFs come from the WRENCH repository, a baseline for weak supervision with nearly two dozen datasets and associated labeling functions. In this post we report experimental results on four datasets in particular: YouTube spam classification, IMDB sentiment classification, Yelp sentiment classification, and AGNews topic classification. For consistency, all weak supervision experiments use the MeTaL label model for combining multiple LF votes into resulting training labels. All results reported are averaged over 3 random seeds.
Zero-Shot with LLMs
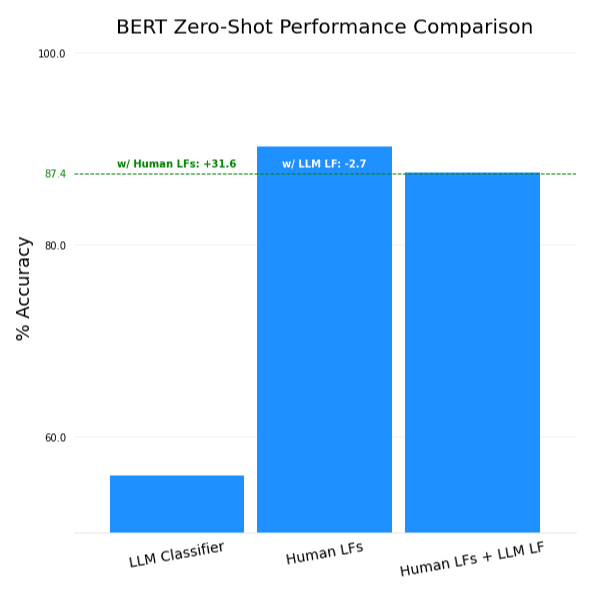
Using BERT out of the box as a zero-shot classifier sadly does not yield great results. It significantly underperforms the human-generated LFs, and actually hurts overall performance if added to them. To be effective, it needs to either be tuned to the new tasks with a few labeled examples, or have its zero-shot abilities improved.
Few-shot learning with LLMs
Adding a few “shots” of labeled examples to fine-tune BERT helps to better connect what it knows to the problems at hand. We updated the model weights following the strategy outlined here, and used a range of 3 to 20 shots per-label (up to 80 labeled examples for the AGNews dataset, which has 4 labels) to see how well the model performed at different levels of training data availability.
We found…
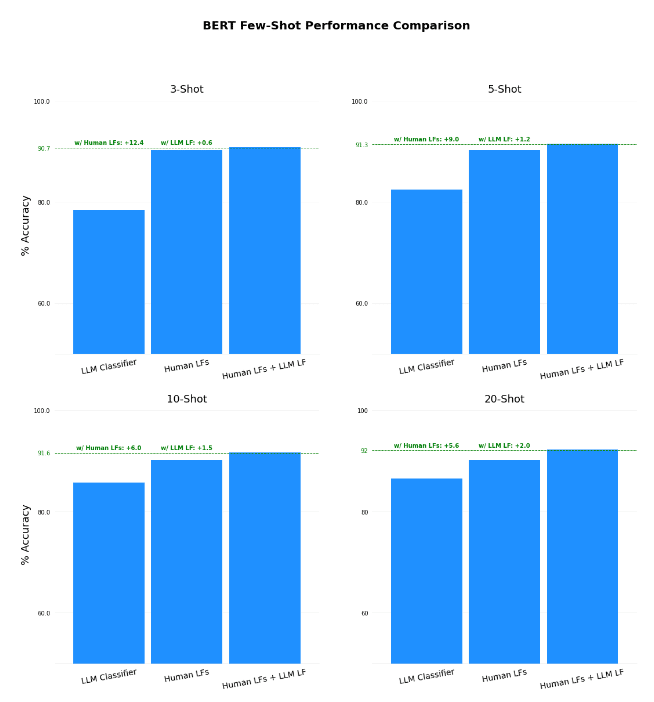
Success! We saw an overall improvement in both scenarios for every single number of “shots” – 3, 5, 10 and 20. The fact that we see improvement at all on these datasets in conjunction with the human-created LFs is impressive, as these LFs were manually curated to provide high-level performance on-par with using a fully labeled training set 3.
We can dive a little deeper into where BERT does well, and where it struggles. Below we see a per-dataset view of BERT used as a zero- and few-shot learning classifier, with and without weak supervision. The gap between using the LLM with and without weak supervision is substantial, even as the amount of training data we feed into BERT increases.
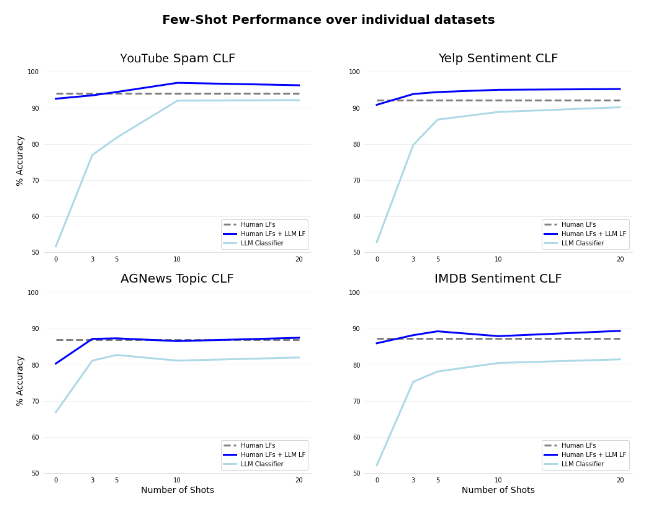
More interestingly, we can also note that the incremental performance gain given by more training data drops off fairly quickly – performance both with and without weak supervision seems to plateau midway through the graph. At a certain point, it seems that it is more beneficial to focus your efforts on creating new labeling functions to complement what your LLM knows (jumping from the light blue to the dark blue line in the graphs), rather than hand-labeling more and more data to eke out slightly more performance with the few-shot model. Doing this will give you the best of both worlds – utilizing both the few-shot capabilities of these models, and the efficiency benefits of weak supervision as you increase performance without new labeled data.
Now, while these models did show impressive results, they did still have some drawbacks. The few-shot language models took a non-trivial amount of GPU time (10-30 minutes per dataset) to train, as well as figuring out good default hyperparameters to conduct that training. They also required us to constrain our answer space mapping (a map from tokens output by the model to classes in the label space of the problem) to a single token – which can be hard when a class requires a more detailed description than “spam” or “positive” (see more here).
What we’d really like is a way to help the model improve its ability to contribute to new tasks without requiring extra training or restricting how we frame our problem.
Zero-shot entailment with LLMs
The “BART-large-MNLI” model by Facebook is a BART model 4 that has then been fine-tuned on the Multi-NLI dataset, an entailment task. At a high level, this just means that you can pass the model two input texts: a premise, and a hypothesis. To bring this back to our problem, all we have to do is treat each example we are trying to classify (e.g., a YouTube comment to identify as spam or not) as a premise, then pass the model our task-specific True/False statement (“This comment is spam.”).
We found that incorporating this model in a zero-shot manner gave…
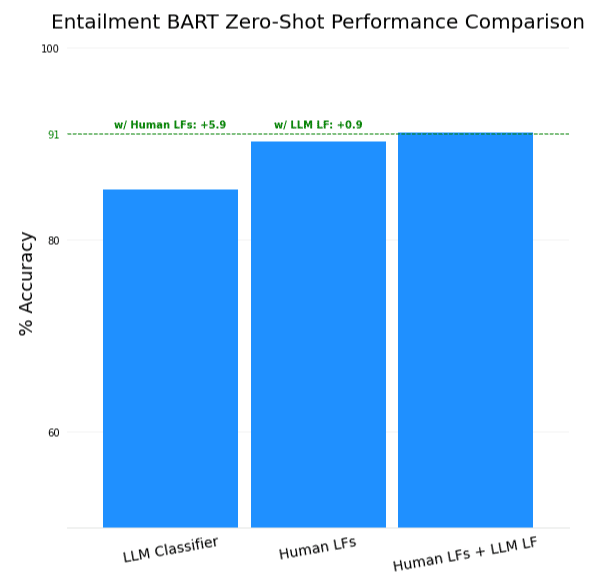
A boost as well! While the boost over the LLM classifier is not as significant as the one achieved by the 20-shot version of BERT, it did beat out the 3-shot model. This is the direction we expect to be most appealing in the long run, as the zero-shot potential of these types of models allows for a few key benefits:
- No (new) training is required—simply deploy the model as-is for inference
- Generalize to unseen data—few-shot learning models can have bad failure modes when new data samples are dissimilar from the (few) that they were trained on. Capable zero-shot models, however, have never seen your task-specific data and can generalize to domain shifts much better.
- One model serves multiple tasks — rather than creating a new variation of the LLM for every task that it is applied to, the model itself can remain fixed and only the inputs change
Final thoughts on obtaining the benefits of few-shot learning with large language models
Large language models continue to delight with every surprising demo of their zero- and few-shot learning capabilities. Such demos hint at the rich knowledge stored inside these models, and researchers are still working on creative ways to extract and incorporate all of this knowledge into solutions to real-world problems.
Weak Supervision stands as an excellent way to leverage these models in your production pipeline. It not only gives significant performance gains compared to using these models off the shelf, but it also offers flexibility in how we drill into that rich untapped signal. Treating BERT, T5, or GPT-3 as an additional axis of knowledge instead of an oracle allows us to incorporate other subject matter expertise into our solution, and provides a benefit in both directions—subject matter experts get a free boost in signal from an external resource, and large language models don’t need to reach production levels of accuracy before they can be utilized.
In the experiments outlined briefly in this post, we found that even in a simple case where labeling functions are created independently from the LLM (rather than in response to its gaps) and only one of the “smallest” LLMs is used (BERT), overall model quality can be instantly improved by plugging in a pre-trained LLM as an additional labeling function. As the study and development of LLMs continue, we expect to see increasingly large gains from incorporating these rich resources into weak supervision pipelines.
Learn more about Snorkel AI’s published research on our website. To learn more about data-centric AI with Snorkel Flow, request a demo, or stay informed about future news and research from the Snorkel team, you can follow us on Twitter, Linkedin, Facebook, or Instagram.
1 Positive and negative examples copied from “Giving GPT-3 a Turing Test” by Kevin Lacker
2 “T-Zero/README.Md At Master · Bigscience-Workshop/T-Zero”. 2022. Github. https://github.com/bigscience-workshop/t-zero/blob/master/inference/README.md.
3 Zhang, Jieyu, Yue Yu, Yinghao Li, Yujing Wang, Yaming Yang, Mao Yang, and Alexander Ratner. 2021. “WRENCH: A Comprehensive Benchmark For Weak Supervision”. Arxiv.Org. https://arxiv.org/abs/2109.11377.
4 Lewis, Mike, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. “BART: Denoising Sequence-To-Sequence Pre-Training For Natural Language Generation, Translation, And Comprehension”. Arxiv.Org. https://arxiv.org/abs/1910.13461.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

