
The how, what, and why of Snorkel’s programmatic data labeling approach and the state-of-the-art Snorkel Flow platform
The year was 2015. For the first time, machine learning (ML) had outperformed humans in the annual ImageNet challenge. Neural machine translation began to look not just possible but inevitable. AlphaGo became the first computer Go program to beat a human professional Go player.
But underneath these and other tantalizing AI wins was a dirty secret: behind nearly every ML-driven “automated” process was a shocking amount of very manual labeling. And the models were only getting bigger and more data-hungry by the year. Motivated in part by these observations, the Snorkel team (then a part of the Stanford AI Lab) set out to develop a fundamentally new way of approaching AI—one that could provide all the power of modern machine learning without the pains of hand-labeling. The Snorkel project was born!
Fast-forward six years and Snorkel has grown substantially:
- Powering critical applications at some of the world’s largest organizations (Google, Apple, Intel, etc.)
- Enabling doctors, scientists, and journalists to unlock new ML applications
- Being taught in textbooks and courses at some of the world’s premier universities (Stanford, Brown, Advanced NLP, etc.)
- Driving business value for Fortune 500 companies in finance, insurance, healthcare, telecom, retail, software, etc.

But what exactly is Snorkel? Is it an algorithm? A platform? A company?
And underneath that adorable blue octopus, how does it work?In this post, we aim to answer these and other frequently asked questions about Snorkel.
What Is Snorkel?
Snorkel is an ML approach that utilizes programmatic labeling1 and statistical modeling to build and iteratively improve training datasets. It is not limited to a specific algorithm or modeling technique, as many variants of each have been utilized in various iterations of Snorkel over the years.
Snorkel Flow is a first-of-its-kind data-centric platform for building AI applications, powered by the Snorkel approach to ML and incorporating years of experience by the Snorkel team in applying it to real-world problems. Today, it is used by numerous Fortune 500 companies to build AI applications.
Snorkel AI is the AI company founded in 2019 by the original creators of Snorkel, which develops Snorkel Flow and strives to unlock a better, faster way to build AI applications.
With terminology out of the way, let’s dive into how Snorkel works! As a toy running example, we’ll pretend we’re building a binary classifier for identifying spam emails.
How Does It Work?
The Snorkel approach consists of four primary steps, which a user iterates through to systematically improve the quality of an ML model until it’s ready to deploy:
- Label
- Integrate
- Train
- Analyze
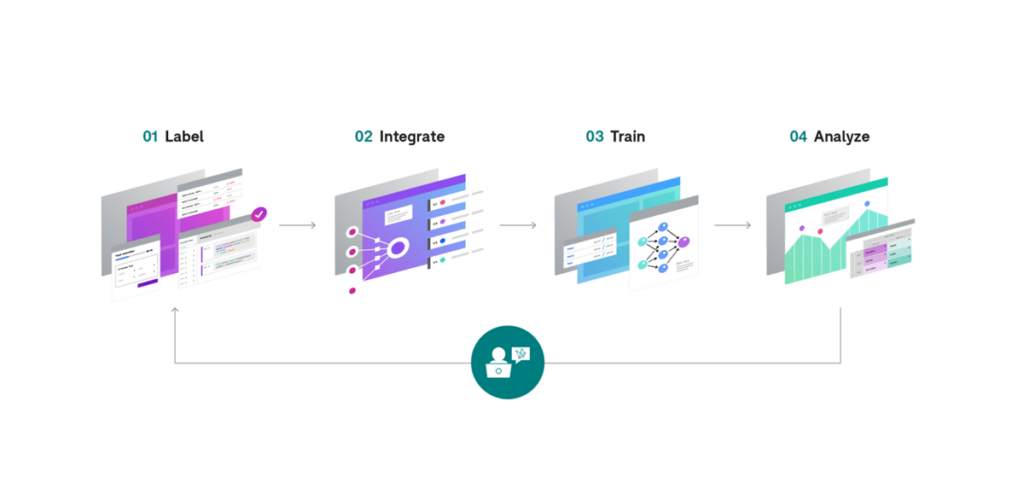
At first glance, this looks very much like a traditional ML pipeline. But you’ll see as we walk through each step below in greater detail that:
- When powered by Snorkel, each step has more flexibility and control than its counterpart in a traditional pipeline.
- In a Snorkel application, it is much easier to iterate through these steps repeatedly, allowing for systematic improvement in hours or days instead of weeks or months.
Label
With a legacy hand-labeling approach to ML, you may begin by labeling anywhere from thousands to millions of individual data points one-by-one. Some are easy to label, some are hard, and some may feel redundant because of how similar they are to ones you’ve already labeled, but it doesn’t matter—you label them all, one-by-one. For most examples that you label, you could explain why you’re labeling it that way. But there’s nowhere to incorporate that reasoning in a legacy approach, so you toss it away and just give a label instead.
With Snorkel, you don’t have to throw your rich domain knowledge away—instead, you capture it in the form of labeling functions.
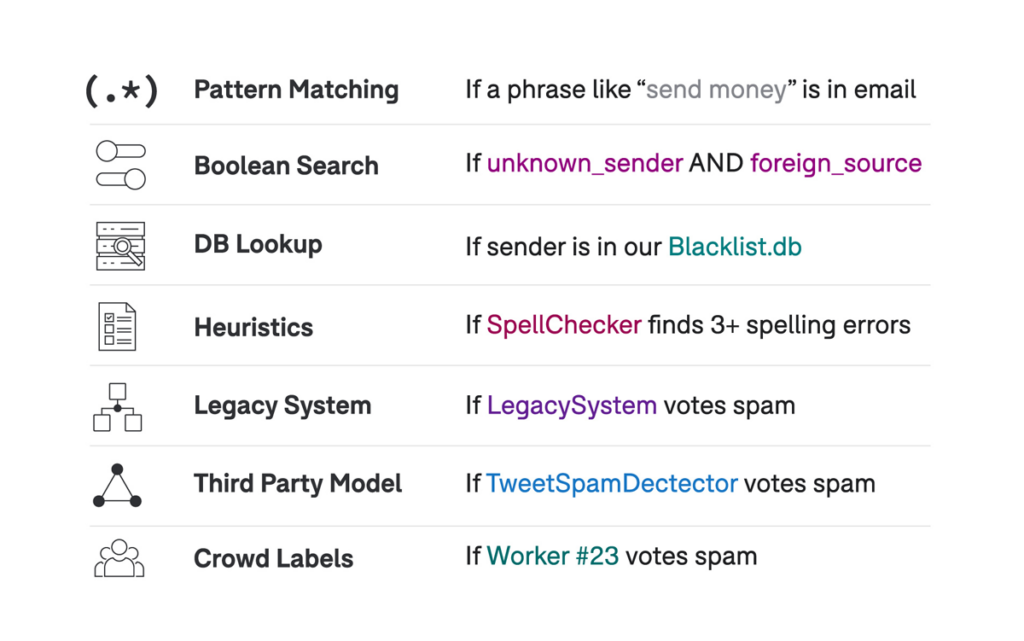
Labeling Functions (LFs) are a core abstraction of the Snorkel approach to ML. An LF is simply an arbitrary function that takes in a data point and either outputs a label or abstains. Importantly, this interface assumes nothing about how your LF arrives at that label. In practice, this flexible definition allows for incorporating a huge variety of signals in your training data creation process (the “kitchen sink” approach)—essentially, if you can think of a programmatic way to label some subset of your data with a precision that’s better than random, toss it in!
Running Example. As an example, imagine that you are trying to train an email spam detector for your company’s email server. One approach for creating a training set would be to label tens or hundreds of thousands of individual emails by hand. Another approach would be to encode your domain knowledge in labeling functions. For example, you wouldn’t have to look through many data samples to realize that certain words (“viagra”, “wire transfer”, etc.) are strongly correlated with spam, while others (“spreadsheet”, “OKR”, etc.) tend to occur in valid business-relevant emails. By converting these keywords into labeling functions, you can potentially label thousands of examples at once, based on your own domain knowledge, but applied now at a much greater scale.
Question. How do I know what LFs to write?
You may be wondering: “That’s great that I can create a wide variety of LFs—but how do I know which ones I should write?” The answer comes from focusing on your ultimate goal: you’re not trying to create a training set—you’re trying to train a high-quality ML model! So rather than trying to come up with the long list of LFs that you could write, in Snorkel Flow, you start by creating some minimal initial set of LFs (e.g., one LF per class) and then iterating. As you’ll see in Step 4: Analyze, in Snorkel Flow, you get feedback on where your model is making mistakes and how that’s correlated with your training data and LF outputs. As you look at those specific examples and think about how you as a human would label them, that can guide you to what type of LF you should write next, whether that’s bringing in an existing resource or writing a new heuristic. If you have a small amount of labeled data in your training set, Snorkel Flow can also auto-suggest entire LFs or auto-tune thresholds for LFs whose structure you define.
Question. Do my LFs need to have human-level precision?
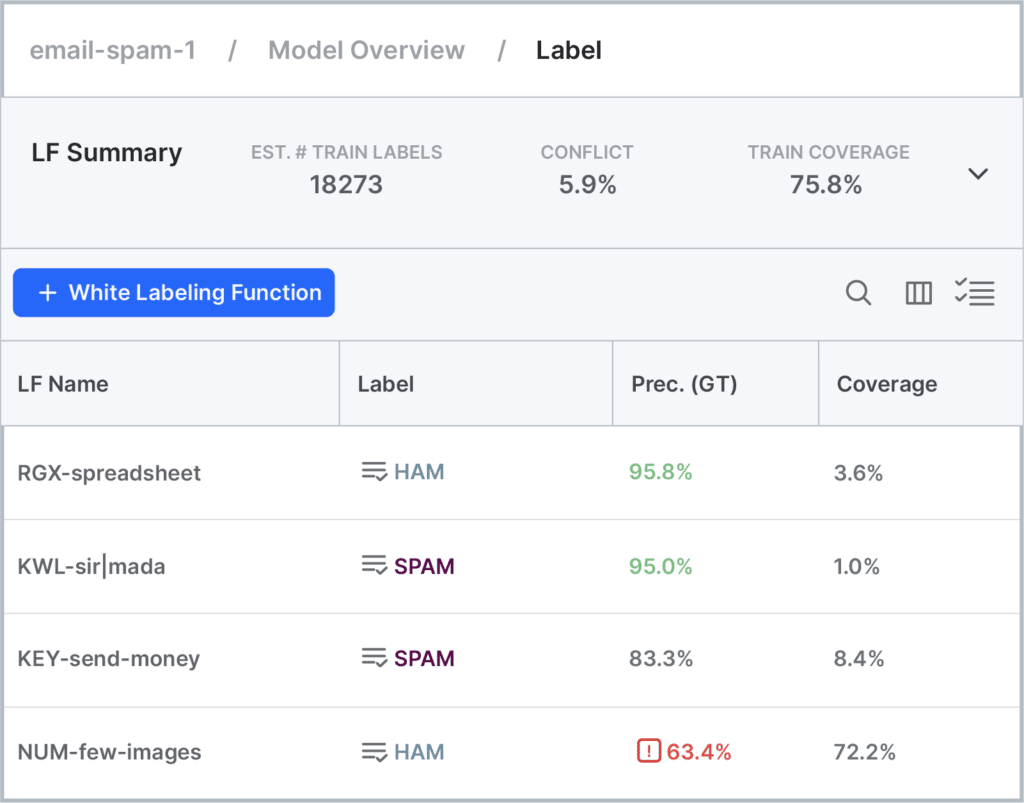
Nope! It’s called “weak supervision” for a reason—Snorkel expects “weak” labels. From a theoretical standpoint, with enough raw data to label, all Snorkel requires is that your LFs are better than random on average. But in practice, the more precise your LFs are (and the higher their coverage on your dataset), the quicker you’ll get to a high-quality training set of sufficient size for your model, so Snorkel Flow color-codes LFs based on their precision and coverage to help you identify which ones are good to go, and which may need additional attention. Your LFs also don’t need to cover the entire dataset—more coverage means a larger dataset, but we’ll ultimately be training a classifier over a much more comprehensive feature set than just our relatively small set of LFs.
Question. How should I express my LFs?
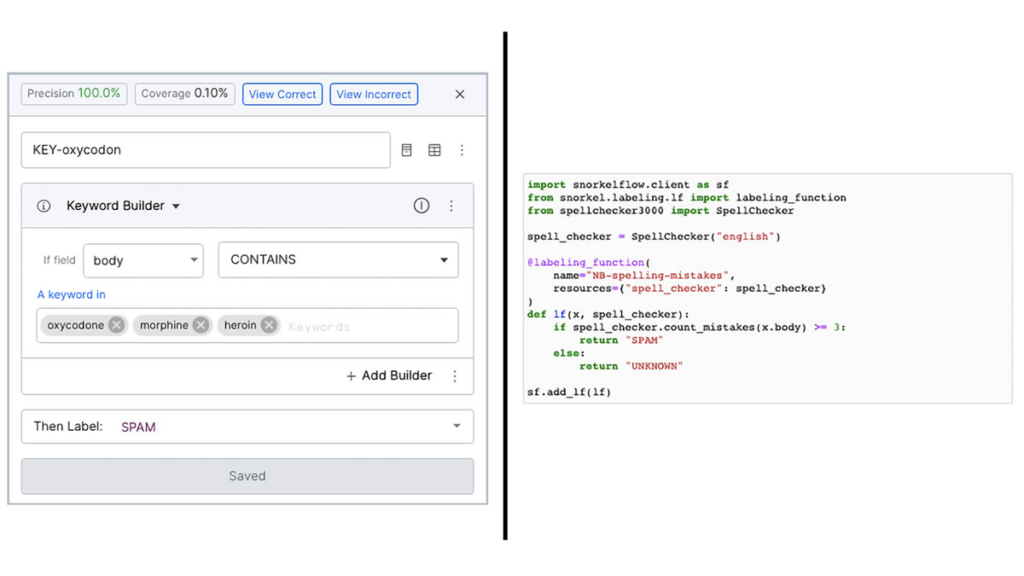
For many common types of LFs, Snorkel Flow includes a library of no-code templates where all you need to provide is the nugget of domain knowledge to complete it. For example, provide the specific keyword that you’re looking for within the first three sentences of your document and toggle whether or not you want it to be case-sensitive, but let the template handle compiling that down into an optimized executable function. However, in some cases, you may want to express a very specific type of signal that doesn’t have a corresponding template yet or which uses a closed source library that only you have access to—in that case, you can use the Python SDK to define a custom LF in the Snorkel Flow integrated notebook.
Question. How is writing LFs different from building a rules-based classifier?
Read on, my friend! We answer that precise question in Step 3: Train.
Integrate
Once you’ve got a set of LFs, how do you turn these into training labels? As mentioned in the previous section, these LFs can be noisy—they may conflict with each other at times, make correlated errors, not cover all data points, cover certain classes better than others, etc.—and in most cases, we don’t actually have the ground truth label for our training examples. But we can use theoretically grounded and empirically proven mathematical methods to identify optimal ways of combining these noisy supervision sources to create high-quality labels nonetheless, and now at a much greater scale and with much lower cost than doing so manually.
The problem we have to solve can be modeled as follows:
- Every data point has some “true” (hidden or latent) label Y—what the world’s foremost expert on your problem would label it.
- We don’t have that, but we do have a bunch of weak labels λ that, in general, are correlated with the true label.
- We now need a process for inferring the most likely true label for each data point given all these noisy labels across our dataset.

The model that we use to represent this problem is called a label model. It’s important to note that there are many such models that we could use for this problem. To quote a famous statistician, “All models are wrong, but some are useful. “Over the years, the Snorkel team has proposed different models and algorithms that make different assumptions and work best in different scenarios. Some of our early work is available in papers (e.g., NeurIPS 2016, ICML 2017, AAAI 2019, etc.)g, but none of these “is Snorkel” any more than the final model architecture we choose or the LF templates we use. They are each just different choices for a single component in the framework. Furthermore, we’ve never stopped innovating here—Snorkel Flow includes the world’s most comprehensive library of label model algorithms, with all the above plus additional work from the past couple of years, including algorithmic, speed, and stability improvements.
After an appropriate label model has been selected and applied to our inputs—LF votes per data point, any ground truth labels that exist in the training set2, priors about class balance, etc.—the model’s output is a probabilistic label distribution per data point. In other words, for each data point in the training set, the model estimates how likely it is that its true label belongs to each class. We can then use these labels as-is for models that accept label distributions or keep only the maximum likelihood label for each. This becomes our training set.
Running Example. Returning to our spam detector mentioned above, many of our rules will have less than perfect accuracy. For example, an LF that looks for prescription drug names as a sign of spam email may vote incorrectly on emails from a valid customer that sells prescription drugs. On the other hand, an LF that looks at the historical response rate to emails sent from this sender may have high confidence that this is, in fact, an email worth responding to. The key is that we don’t need to negotiate every area of conflict manually. Because the output of this step is a training label, not a final prediction, we can combine multiple LF votes (even conflicting ones) into a single confidence-weighted label per data point (e.g., I’m only 78% sure that this email is spam), and train on that.
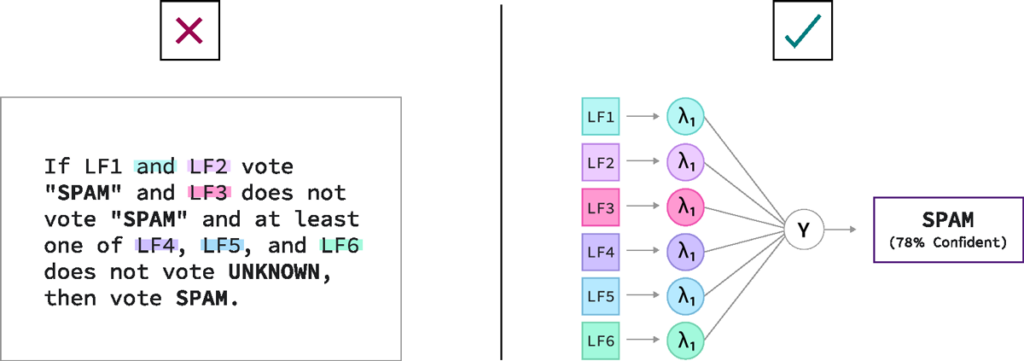
Importantly, once a set of LFs has been developed, creating a new training set—even one with hundreds of thousands or millions of data points—now takes on the order of seconds or minutes, not person-weeks or person-months! As a result, the barrier to updating or adapting your training set to respond to emerging needs, data drift, etc., is significantly lowered, and you end up being able to iterate on your models orders of magnitude more quickly than with legacy approaches driven by hand-labeling.
Train
With a large, freshly generated, domain-specific training dataset, the third step is to train a model appropriate for your data modality and task type. Here we recommend taking advantage of the fantastic progress that has been made in recent years in accessible, user-friendly, open-source model libraries. For example, in Snorkel Flow, we provide a model training interface compatible with Scikit-Learn, XGBoost, Transformers, and Flair, to name a few. You can also export training labels to train a custom model offline and then upload the predictions via the SDK.

The natural question to ask at this point is: Why do we need a model if we already have a bunch of LFs (“rules”) capable of creating training labels (and therefore predictions)? The primary reason is that we want to generalize to other examples, including ones where none of our LFs apply. Additional reasons are listed below:
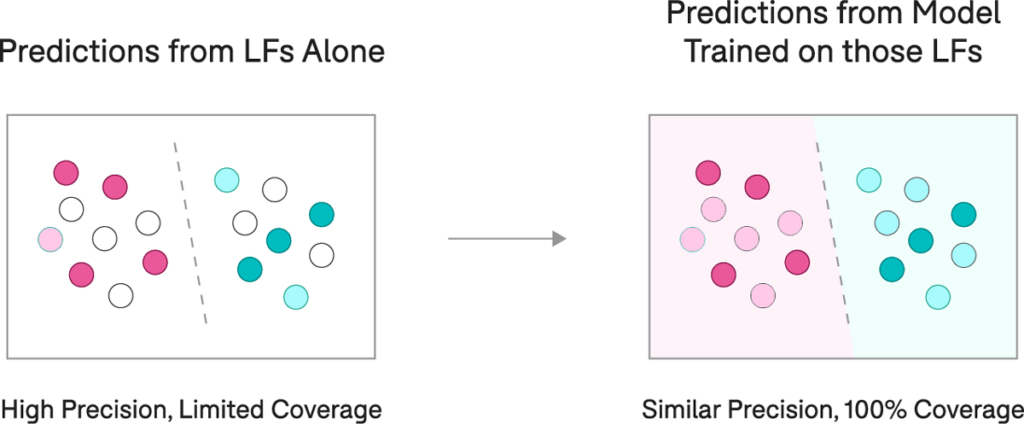
- Generalization: Rules are nice—they’re direct and interpretable. However, they also tend to be brittle. On the other hand, machine learning models tend to do a much better job of dealing with minor variations between data points. For example, imagine two emails identical in every way except for one word being swapped out for a synonym. A rule-based system looking for that keyword may fail on one and not the other, while an ML model will almost certainly classify the two similarly. This disparity is because the model can utilize a more comprehensive feature set. In other words, rather than depending on one keyword to make its decision, the model can factor in the presence (or absence) of thousands of keywords all at once.
- Non-Servable Features: In a rule-based classifier, all rules must be able to be executed at inference time. With Snorkel, on the other hand, it is possible to create your training set using features that won’t be available at test time—we call these types of features “non-servable.” For example, you can use the historical response rate to emails from certain senders to add weak labels to thousands of emails in your dataset for which you have that information, and then train a model only on the content of the email (all “servable” features) so that it can make predictions on new incoming emails as they arrive.
- Transfer Learning: One reason machine learning (and more specifically, deep learning) has taken off in recent years is the evolution of representation learning, or learning rich features for your data automatically from the data rather than feature engineering by hand. Pre-trained embeddings and models like the ones available in Snorkel Flow bring rich background information to the table—e.g., for NLP tasks, synonymous words may share no similarities in their surface forms, while having nearly identical representations in a model. Utilizing these techniques can significantly improve the ability of a model to generalize to unseen examples.
Analyze
Once an ML model has been trained, what are your options? First, you’ll want to evaluate its performance with metrics appropriate for your problem (e.g., accuracy, F1, etc.). If its quality is sufficient, you can deploy it as part of an AI application and begin to monitor its performance over time (more on that in the next section). If quality is insufficient (which it nearly always is on your first try), you begin a targeted, iterative improvement process, improving the model by improving the data.
What do we mean by targeted improvement? When a model predicts the wrong label for an example, there are multiple possibilities why:
- There’s an issue with the model. For example, you may have a model with insufficient learning capacity, or your regularization parameter may be set too high.
- There’s an issue with the data. For example, you may have too many incorrect training labels, or there may be “blind spots” in your dataset, where examples in your test set have no similar examples in your train set.
In our experience, too many practitioners assume (implicitly or explicitly) that their dataset is complete, correct, and untouchable, so they spend all their time iterating on the model. In reality, most model mistakes are the fault of the data, not the model architecture or training routine! And if the issue is in the data, then that’s where you should spend your time, rather than blindly hyperparameter tuning (hoping to land in a better local optimum somewhere) or collecting more data in general with no attention to where the issues actually lie within it.
Running Example. Returning to our spam detector example, our training set may include many labeled examples of spam emails trying to sell us prescription drugs or get us to wire them money. It may not have any labeled examples of social engineering attacks, where the sender is pretending to be someone we know in order to get us to share sensitive information. If this new type of attack doesn’t have enough in common with the other types of spam emails where we have more examples, our model may perform poorly on most of them—not because we need a different model or more data in general, but because we have a blind spot. One new LF that covers even just a small portion of this new class of errors could easily be enough signal to squash that whole bucket, and the analysis page can guide us right to those examples.
In Snorkel Flow, there is a designated Analysis page for exploring model performance and identifying the sources of errors by your model. Automated tools suggest actions to take, group errors into buckets for inspection, and allow you to view model performance over time over different subsets of your data.
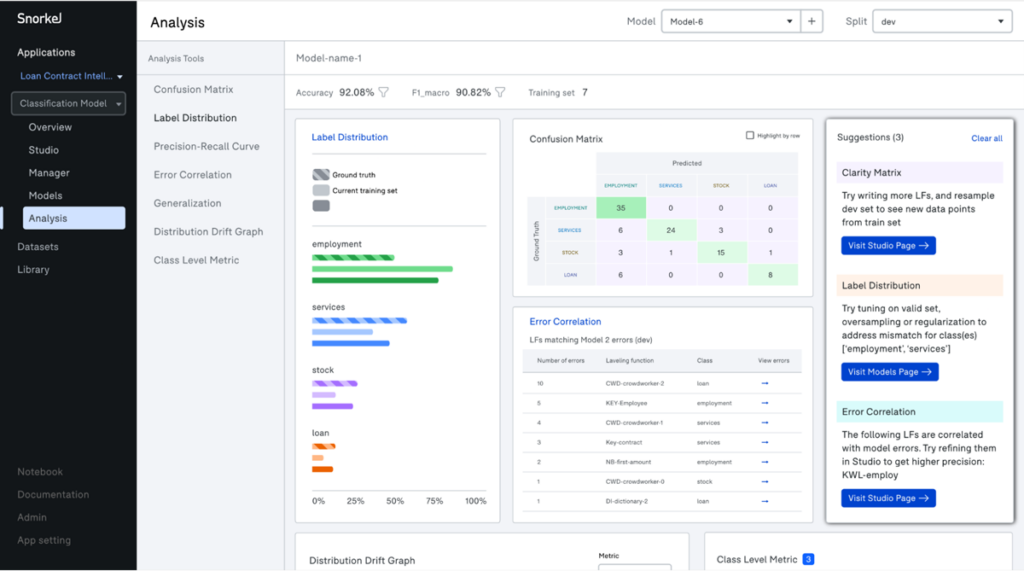
Importantly, with the Snorkel approach, you can update a large training set and retrain a powerful model in minutes, in one sitting, by one individual or small team, rather than over weeks or months of coordination for large manual labeling jobs. The result is a more rapid, iterative, and adaptive process for creating and maintaining high-quality AI applications.
What Else?
What we’ve described above is the core iteration loop inside a Snorkel application. While not reviewed in this article, Snorkel Flow has many other features that elevate it from a training set or model creation tool to a complete enterprise platform for building AI applications. Some of those features include:
- Application studio: Support for multiple data modalities (unstructured text, structured text, time series, etc.), problem types (NER, info extraction, multi-label classification, etc.), and custom application graphs combining multiple models, pre-/post-processors, and custom business logic
- Programmatic labeling IDE: no-code LF templates, auto-suggest and auto-tuning of LFs, interactive data visualization, automated management and versioning of LFs, etc.
- Training data management: advanced label model algorithms, automated parallelization, and hyperparameter selection, dataset versioning and comparisons, etc.
- Model training and serving: one-click model training or fine-tuning, hyperparameter search, endpoint creation for mode/application serving, export for serving at scale, etc.
- Deployment and security: REST API, monitoring services, and managed workers for job execution; encryption, authentication, and role-based access control (RBAC), managed SSO integration; support for hosted, hybrid, or on-premises deployments, etc.
If you’re interested in staying in touch with Snorkel AI, follow us on Twitter, LinkedIn, Facebook, Youtube, or Instagram.
If you’re interested in becoming a user of Snorkel Flow, reach out to us at info@snorkel.ai.
And if you’re interested in joining the Snorkel team, we’re hiring! Apply on our careers page.
1 Programmatic labeling is a kind of weak supervision, or using higher-level and/or noisier inputs than ground truth labels to train a supervised ML model. With programmatic labeling, labels are assigned via user-generated programs or functions, rather than by hand.
2 Ground truth labels are entirely optional, but if they exist we can use them.

Braden Hancock
Co-founder
Braden is a co-founder and Head of Technology at Snorkel AI. Before Snorkel, Braden spent four years developing new programmatic approaches for efficiently labeling, augmenting, and structuring training data with the Stanford AI Lab, Facebook, and Google. Prior to that, he performed NLP and ML research at Johns Hopkins University and MIT Lincoln Laboratory and earned a B.S. in Mechanical Engineering from Brigham Young University.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

