New Snorkel benchmark leaderboards. See the results.
Prompting Methods with Language Models and Their Applications to Weak Supervision
Machine Learning Whiteboard (MLW) Open-source Series
Today, Ryan Smith, machine learning research engineer at Snorkel AI, talks about prompting methods with language models and some applications they have with weak supervision. In this talk, we’re essentially going to be using this paper as a template—this paper is a great survey over some methods in prompting from the last few years from some folks over at Carnegie Mellon, and it’s called “Pre-Train Prompt and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.” On top of the paper, they also have a great resource as a nice digestible web page that you can go to at Pretrain NLPedia, which I highly recommend. It’s got a bunch of the information just distilled really well with a lot of helpful figures and sectioning for some of the more complex topics. But yeah, let’s dive right in.This machine learning whiteboard episode is part of the #MLwhiteboard video series hosted by Snorkel AI. Check out the episode here or on Youtube:
Additionally, a lightly edited transcript of the presentation is below. So, some background. I imagine most of you have heard about the recent advancements in NLP, which are basically that we now have these extremely large language models that are trained over a large amount of text, over a large amount of time, and then we can use those existing language models for tons of downstream tasks to which the language that they were trained on actually transfers really well. Some of those you know, such as BART, your BERT, your ERNIE, GPT, T5, all those types of models, if you’ve heard those names over the past couple of years.
Language Models Background
The current standard in using these language models has to do with what I described first. You take your language model and train it over a very large amount of text—think Wikipedia, or all of Reddit, or something like that-and this language model is being trained for some kind of either next-token prediction or masked-token prediction. We don’t have to get too into the weeds there, but basically, it’s just taking the text as is, and it’s learning to predict other aspects of the same text. This method doesn’t have the need for human labels to get these really robust, powerful language models that ideally are absorbing some characteristics of natural language.
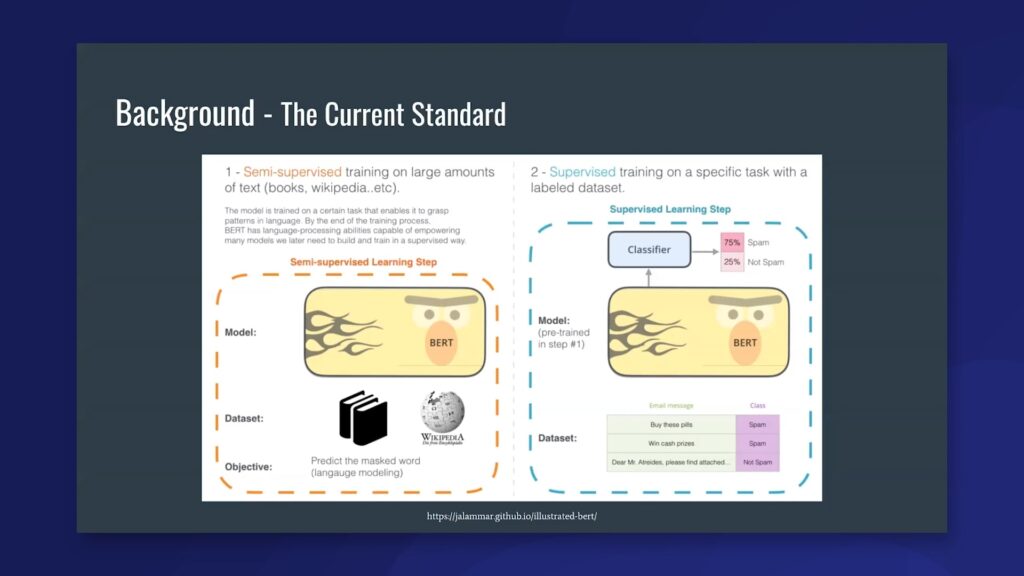
The way that a lot of people use these models in practice is that they’re able to take the language model that was trained over all that data and then attach a task-specific or task-head classifier at the end of that language model. This classifier can be something like a feed-forward neural network that classifies “spam” or “not spam,” as shown here in the example. Or, it can be something a little bit more complicated that is used to, for example, do machine translation and has a few more bells and whistles on top of that. The premise is that we take the encoder of the language model and then chop off the decoder and put our own version of a task-head specific thing at the end there. Now, this is great because, first, it enables transfer learning in a lot of downstream applications. This gives us the model knowledge—all the language characteristics that the model learned. We kind of get those for free when we apply them to a simpler or smaller task, which is known as transfer learning. We also have a pretty standardized and fairly straightforward way of doing this task head classifier work. This is largely thanks to folks over at Hugging Face. Their repository has just been incredible and really helps people move forward in implementing these models and experimenting with them as well. However, that leads us to some of the cons.

As I said before, we take the encoder of the language model, and then we just chop off whatever decoder framework that model uses. First, we actually lose out on all of the knowledge learned by that decoder or any latent space representations that it learns within its weights. Second, we also lose out on any mapping. So, if I’m applying my language model to a sentiment classification problem, we actually lose out on any knowledge about the task labels in that sentiment classification problem. Because when we slap on a new task-head-specific dense neural network, we have to reinitialize that new network with fresh weights, and it doesn’t know anything about what the class labels actually represent. We lose any semantic meaning that was in those task labels from the model. Then finally, this still has a bit of supervision cost, because we come in with fresh weights on that task-head classifier. We actually still need a good amount of data to be able to train that specific classifier, and also maybe fully re-learn the weights for some of the other parts of the model. In order to address a lot of these issues, a new kind of paradigm has popped up called prompting. Prompting is basically instead of cutting off the decoder aspect of the language model, we want to just leave that whole architecture as-is. This was really brought to light by the GPT-3 paper, which is called “Language Models or Few Shot Learners,” and I would definitely recommend [it].
Prompting Language Models

So, on the right, this is a figure lifted from that paper. The point of prompting is that instead of treating our language So, on the right, this is a figure lifted from that paper. The point of prompting is that instead of treating our language model as the input to a classifier, we’re actually going to keep it as a language model. Then, hopefully, if we give it the right natural language context, it will give us what we want to fulfill our task, whatever that may be—either classification or machine translation, or named entity recognition, and so on. On the right, you can see the input to the model in this zero-shot setting—and I’ll get into the difference between zero- and few-shot in a moment—but the input to the model is basically, we say: “okay, I want you to translate English to French,” and then we say “cheese” and give it an arrow. Hopefully, the model can pick up that it now wants to give a French translation. Now, this might not be enough, because the model might still be confused. Like, what does the arrow mean? Has it seen enough arrows in its training to know what to do? What’s helpful here is to actually give the model a few examples. So, if you see the few-shot case (this is still using GPT-3), we actually still do the prompt, “translate English to French”—we want to frame what task we’re trying to do—and then we give a few examples of English-to-French translations below before asking the model to then complete the next prompt. Hopefully, it picks up on what the next step should be. One of the really nice parts about this is that this allows us to take advantage of existing relations between our examples and any label space that we might care about when running classification tasks.
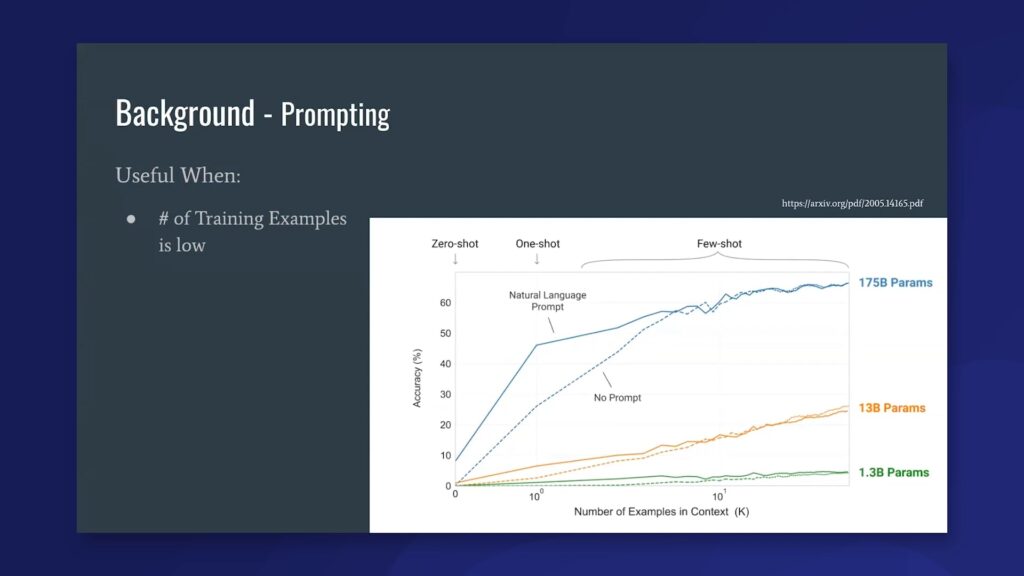
So, when is prompting useful? Prompting is actually really useful in a few key circumstances. The first main one is that when our number of training examples is low, prompting actually outperforms the task-head classification in some of these really large language models. If you look at the graph, the blue line represents the largest language model, at 175 billion parameters. The red and green both represent smaller models, but you can actually see in every case that the solid line, representing prompting, outperforms the dotted line, which represents the standard way of doing task classification, all the way up to—in GPT-3, it’s only until about eight training examples, but for the other two it’s around nine or probably 20 or 30 in the lowest one for 1.3 billion parameters. What this shows us is that prompting picks up on what the label space is trying to convey at the start and needs less labeled examples to get up to some baseline accuracy.

The other case when prompting is really useful is if your label space contains encoded information. What this means is that if you frame your classification task—the example I’m giving is if we’re classifying sentiment—if you frame that sentiment to a human, as: “I’m going to give you this quote: ‘this movie was incredible,’” and then I give you two options, “positive” or “negative,” you’re aware of which the answer should be. So we select positive, because we have the context given to that label space. However, if I give this other example to a human: “this movie was incredible,” and then ask them to choose 0 or 1, they’re not going to know right away what that means. They’ll have to probably see a few training examples to then extrapolate their decision to other examples, and even then still might not be entirely sure. This is kind of the same premise when we apply this to language models, that if our label space contains meaningful semantic information, we want to be able to encode that in the model classification task. One of the final parts about when prompting is useful is that anywhere there’s additional domain knowledge that can be imparted and make the task more successful is really key. This kind of ties into weak supervision because this is an exciting place where we can inject domain and subject-matter knowledge into a topic, and the language model can then hopefully absorb that knowledge and use it to improve its performance.
Prompting methods in NLP
I’m now going to dive into some of the methods around prompting and just give an overview of some of the things that this paper talks about, which is, I said, a survey over tons and tons of different activity in the field. So bear with me if it gets a little technical. Feel free to not pay attention too closely to some of the things, the notation. I’m just going to give an overview of a few of the properties of the paper.

First and foremost, to start your classification task you’re going to want two things: your input and output. Sentiment is a really common example here, because it explains a lot of these concepts easily, but this task would be a sentiment classification task so your input is going to be a string of text: “I love this movie.” Your output is going to be a y label that corresponds to the “++” class, which is “very positive” in semantic terms. The next thing you’re going to need is a prompting function. After that, you’re going to need the output of that prompting function, which they call x-prime. You’re going to want a “field” prompt and an “answered” prompt. And then finally you’re going to want an answer. Don’t worry about absorbing this, I won’t be adhering too closely to it, but it’s just helpful context in case some of these terms come back up in the future.

Prompting examples
Here are some examples of using prompts for classification tasks. That top one—our favorite sentiment example—is you have an input x that says, “I love this movie.” Next, you have a template, which is basically what consists of your prompt. The template has a slot for the example, denoted by the “[x],” in brackets, and it has a slot for a potential answer, which is denoted by the “[z],” in brackets. A list of answers exists on the right. So you have “great,” or “fantastic,” or probably “bad,” “terrible,” and just a bunch of options to choose from. What the prompted model will do is take the x-prime from the previous example, which is a template that has had the input x filled in. So, the template will look “I love this movie,” period, “this movie is ___,” and then still have that room for the answer. Then it’ll iterate over every single answer and choose what the language model sees as the most probable outcome. That’s kind of the typical way to do the atypical. That’s the simplest way to do it for classification tasks, but you can also extend this to some other task types. We can do this for aspect sentiment. We could have our prompts and—say we have our example fed in—and then in our prompt, we specifically ask about the aspect that we care about. So, we say, “what about service?” because that’s the aspect that we care about classifying sentiment for. We can also do this for text pair classification. In this example we actually have two input slots for x in our prompt. The first is we say we want the first part to be a question, so this will be an entailment. And then our answer is either, this does entail something, or it doesn’t entail something. That’s why the options for z are “yes” or “no.” Basically, we’re saying does x1 lead to someone saying, “yes in fact this is the case for x2,” or does it lead to someone saying “no, actually, x2,” something like that. Then named entity recognition also feeds into this, with putting two examples in the same prompt. Finally, we have text generation. These are a little bit more straightforward, in that the “[z]” in brackets represents an open-ended string that can be generated by our language model. These are probably a little bit less novel than prompting but still fall under the category of what these methods hope to do, which is: get the language model into some state where it’s ready to give us our desired output.
Design components to make prompted predictions

Now, I’m going to go over some design components for actually making a prompted prediction. Here are the key components that you need to specify in order to use language-model prompting for your prediction. First, you’re going to select a pre-trained model. We assume that you’re already starting with the basic components for conducting a standard classification task. That’s going to be a set of examples, which would be your x. These are for: inference and/or training; a label space that consists of all possible values of y; and optionally a set of labels from those y’s if you are going to be training this task. First, you select your pre-trained language model. This is going to be BERT, GPT-3, BART, [etc.], and whatever language model you select comes with some design considerations that we will go over later. But just know that this is an important part of what domain knowledge is encoded in the model already and what the predictions are going to look like from that model. Next, you’re going to define a prompting function. The prompt function is basically those templates you saw earlier and any way of combining the text with that template is going to be how your prompting function looks. You’re also going to define a way to select the best filled prompt. If you look on the right, a filled prompt is where you already give an example into your prompt, and you also give it a potential answer. Because you’re only giving it one potential answer, and there are many different answers that you can provide, you’re going to find a way to select what your language model thinks is the best filled prompt. In the simple case this just looks like an argmax function over all possible field prompts for each answer. But in some cases your answer space is really large and you need to use something such as a sampling method to find what you think are the best prompts. Next, you’re going to define an answer space. This answer space is a place where domain knowledge is actually encoded, but it’s [also] a list of all possible values for z. This is important because it allows you to have a mapping from your label space to something that the language model can understand. So, that’s number five. Once you have your answer space, you want to define a mapping from that answer space back to the label space, basically going from z to y. Finally, if you do intend on using a few-shot-prompted predictor, you also want to define a method to train your model for this.

So, these are the [six] things that you have to figure out if you want to use your model for prompting. These can be broken down slightly further into sections that correspond to chapters three, four, five, and [seven] of the paper.
Language models pre-training
First your selection of your pre-trained language model. The biggest impact here is actually how the language model was pre-trained, and what type of decoding that model does. Next, steps two and three with the prompt function and selecting the best filled prompt. This can be known as “prompt engineering” and there are a lot of different methods for investigating these open areas. Next we have answer engineering, which takes care of both defining the answer space and defining the mapping from the answer space to the label space. This more has to do with encoding your label space into a model-readable format. And finally, we have prompted training strategies, which is chapter seven in the paper. We won’t have time to go over this, but this is definitely a big design consideration if you’re interested in doing the few-shot case as opposed to just zero-shot, because you want to figure out how you either update the weights of your language model via these prompts, or how you want to provide examples in context to the language model. Also it’s important to note that prompt engineering and answer engineering are kind of the key ways that we can incorporate weak supervision into the language model prompting, so I will get a little bit more into those in a moment.

The first section is selecting the pre-trained model. Basically, the pre-training objective has a pretty significant impact on how your language model is going to be for use with prompted prediction, so there’s a few different pre-training objectives that these language models are trained with. The first one, the most simple, is next-token prediction. And when I say simple, [I mean] the most straightforward and easy-to-understand. Next-token prediction is basically: we have [as a] given all the previous words in context, [and] we just want to predict the next word. This would be in the classic case of, like, a variational auto-encoder via an LSTM from like, 2017 or 2018. What you’re doing is predicting the next token in the sequence given all the previous tokens in the sequence. With transformers it gets [to] the same place, but this is a pretty classic method of doing things. One of the reasons that these pre-training objectives are so important for prompting considerations is that they are going to affect the types of prompts that we can actually give the model and the ways that we can actually incorporate answers into those prompts.

Another pre-training objective that’s pretty popular is masked-token prediction. Instead of just predicting the next token given all the previous tokens, some language models actually predict any masked tokens within the input, given all the surrounding contexts. So, [for] example, language models that do these would be BERT or RoBERTa, and obviously the Silver as well.
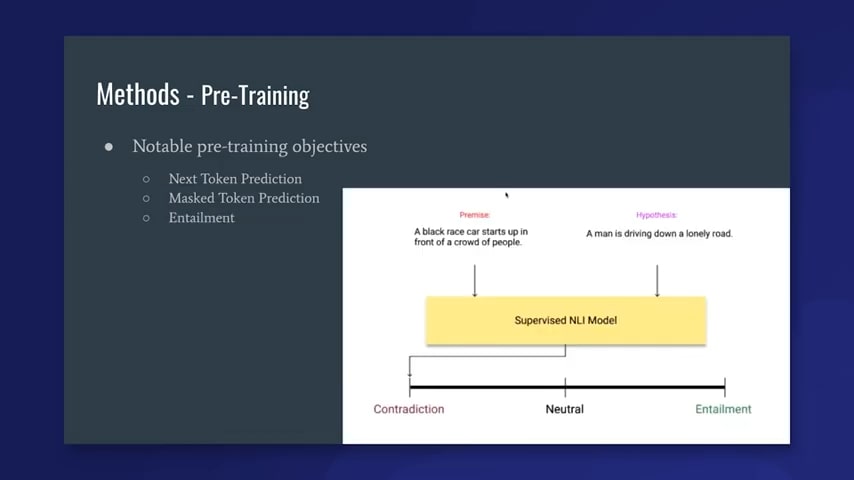
Next is a pre-training method that doesn’t necessarily pre-train a language model, but can still be helpful for prompted classification tasks. This would be training an entailment model. Entailment is, given two statements, you want to classify whether these statements entail each other, contradict each other, or are neutral, which means they have no relation to each other. The example given right here is: “a black race car starts up in front of a crowd of people,” is the premise, so the hypothesis is either entailed, contradicted, or neutral given the premise. The hypothesis is that “a man is driving down a lonely road.” Since we saw a crowd of people in the premise, we actually know this is a contradiction. A natural language inference model, which is basically learning to classify these entailment functions, will say that this will hopefully learn enough of these pairwise examples to know in general what entails something and what doesn’t. What’s helpful here, when we use it with prompted prediction, is that I can give an entailment model something an example, x—so in the sentiment case, “I love the movie, period”—and then I can give it an entailment prompt, which would be something like, “the movie was: ___,” and then my possible answers could be “good,” “bad,” or “okay.” Ideally, I run the premise as the example, I run the hypothesis as “this movie was good, bad, or okay.” I run it once for each of those in conjunction with the premise, and then the model should give me an entailment, contradiction, or neutral score. I [then] look at the answer that achieves the highest entailment score out of those three, and that tells me what the model thinks to be the best answer. So these entailment models may seem a little tangential, but they actually have shown better performance in the zero-shot setting and they are actually what Hugging Face uses as the default for zero-shot classification.
Prompt engineering

There are a lot of other things that go into model selection, but in the interest of time I just showed the pre-training objective. If you want a deeper look, [take a] look at chapter three of the paper.Next I’ll get into prompt engineering. Prompt engineering outlines those two steps of: 1. define a prompt function and, 2. define the best way to select the prompts given a bunch of filled prompts. Prompt engineering has a couple of different ways to go about it. The most straightforward way is to simply have humans craft manual templates for your prompts. While this does inject research or bias into evaluations, it’s also a great launching point for integrating prompting methods into weak supervision. In the example I just showed, if we have two manual templates for a certain task, we’d have a generic one, which is just your example, period. “This example is about [potential answer].” Now, if we have a subject-matter expert instead say something like, “given our example, a patient is likely to experience [answer],”—and I realize this isn’t actually a subject-matter expert because I’m sure a doctor would know more things to put in that prompt, but in general tailoring the prompt to be more task-specific has been shown to help performance in classification tasks. This would be an area that is definitely actively being researched but is also an area that weak supervision can really slot in here to help improve with the prompting process. Another thing to note here is that one of the popular strategies right now that people are using with prompting is to ensemble a bunch of different prompts together, and that’s something that kind of has direct ties to weak supervision. So that, instead of ensembling a bunch of problems, you could treat a bunch of prompts as labeling functions and share the weak supervision aspect of it and improve performance that way. I won’t dive too far into that because that could be a whole talk on its own. So, that was the manual templates approach. There’s also been a push for automated templates. Since the area is very new, there’s definitely a lot of interesting ideas about how to automatically generate these prompt templates. The paper covers a lot of them, and I’m not going to dive into the specifics, but I’d recommend checking it out. These range from things prompt mining, [in] which you’re given a training set of x and y pairs. It will discover prompts within a really large corpus, wikitext, by finding connector words between that x and y. What that would look is [….] if the example input pairs were something like: “I love this movie” and then your example label is “great,” then you would find some kind of connector words between “I love this movie” [and] “this movie was great” in your corpus. That could be one way to automatically generate prompt templates.

Another form of automated templates are actually things continuous or soft prompts, which don’t involve actually learning the natural language representation of the prompts at all. They actually just embed them directly in the latent space of the model and then combine them with each example in turn, and each potential answer. So there’s definitely a lot of fun and exciting research in this area. And it has a lot of potential for people to find new ways to use these prompts better.
Answer engineering

That takes us to answer engineering, which is the third of the four “big buckets” that I showed you. Answer engineering has to do with defining the answer space and defining a mapping from the answer space to the label space. The first thing that you want for your answer space is to figure out what shape that space is, and what I mean by “shape” is: how does the answer look? Is it the form of a single token, in our sentiment example? Is it the form of a span of tokens, where we could have multi-word answers? Or is it the form of open-ended text, in our TLDR or machine-translation examples? These are all important design considerations that, based on your task, you’re going to want to make sure you figure out. The single token example works the best for kind of simplicity of implementation and also constrains your search space a lot. If you do a span of tokens, you’ll either need a language model that can input or can predict a span of tokens in a single mask location, or you need to do something like a Markov chain prediction in a certain spot at the end of your prompt, so that can get a lot more complicated than just the single token space. Open-ended text is also a little straightforward in that a lot of language models right now just support encoder-to-decoder strategies, and this open-ended text is also another common answer shape.

Aside from the shape, you also want to consider the answer space. This one actually is pretty important for how the prompting methods work with the language model. In my own experience, I’ve found this to be actually the most critical step in mapping the label space to something the language model can understand, so mapping between the answer space and the label space. This is definitely where I see the biggest difference between performance in prompting methods from my own experimentation. The answer space can be found via manual design, so you could just make it a one-to-one mapping. So, for a sentiment example, you could have five classes. You could either call these classes “0, 1, 2, 3, 4,” or you could call them “++, +, 0, -, – -.” That would be your label space, and then you want to map it into the answer space of: “excellent,” “good,” “okay,” “bad,” “terrible.” This one-to-one mapping means that each answer maps up with one label, and this, definitely as far as implementation goes, is pretty straightforward to implement. We can also make things a little bit more complicated, but also hopefully more performant, if we actually do a one-to-many mapping. So first, with size, I just condensed the sentiment example, but if we have three classes—positive, neutral, negative—in our label space, this can map to where we have sets of answers for each class. The positive class could map to “good,” “excellent,” “great.” Neutral could map to “okay,” “fine.” And the negative could map to “terrible,” “bad,” etc. What this then opens up is: how do we map the best answer chosen from our prompt back into the label space? There are a bunch of different methods for doing that. One of the most common is just finding the best answer out of all of the potential candidates and then map that back to the label that it corresponds to. But I said, this is definitely an open area of research and it’s kind of “anything goes” at this point, so if you find something that works, good for you, just keep doing it. There are actually also ways to automatedly search over the answer space, just there are for the prompt engineering. These can be things like, starting with either your existing label space or some initial manually generated answer space and then paraphrasing it into a bunch of different answers. Or, you could do something else a prune-then-search approach where you basically have a ton of potential answer candidates, and then you prune them into ones that the model thinks are possible via the weights of the model. So there’s a lot of work going on in just narrowing down what these techniques are, and which ones work and which don’t. But it’s definitely a really fun area of research, honestly, because you can see a lot of crazy things happen that you weren’t expecting.One thing I forgot to note here is that the manual design of the answer space is also another great place to encode subject-matter knowledge. This is a really good tie-in to weak supervision, in that if you choose a one-to-one mapping or a one-to-many mapping, manually encoding what the mappings should be for those answer keys is something that would greatly work with weak supervision in being able to encode domain knowledge to weakly supervise the end model.
Conclusion

My first point is that prompting is a really fun new paradigm. What’s nice is that if you are interested, I wouldn’t say [it’s] fairly easy to get going, but it’s definitely not super inhibited to get started. You can just download a model from Hugging Face and start using either the masked LM or the entailment zero-shot models or pipeline, and that will let you get going from there. There are definitely a lot of certain conditions where prompting improves over the current task-head practice, and it’s really exciting to see these conditions either growing or that improvement margin expanding based on people digging into this and seeing what works and what doesn’t. Also, just the fact that there’s so much to explore makes it really open-ended and really fun. And then domain knowledge can be injected in a couple of places in both prompt engineering and answer engineering, and this is huge for applying weak supervision to prompting and vice-versa, in that we can hopefully get a signal boost from using those methods.
Q & A
Q: How would I figure out the best way to format a timestamp?
A: That is a great question. I think right now what you would do is try a few different formats and then see which one gives you the best performance on a validation set. I actually haven’t read anything that’s timestamp-specific yet, so I might not be the best (I’m definitely not the best) person to answer that question. But as far as a lot of these prompts and answer engineering strategies, it seems to be that the best thing people are doing in the research field is just kind of trying a bunch of things and seeing what sticks.
Q: Any thoughts on filtering out really bad answers? I.e. ‘ham’ versus ‘spam,’ compared to putting all answers, for example, in your training split and applying labeling functions to it?
A: That’s a really good question. That’s actually something we’ve run into on the research side, and I would say right now it looks like the best way to do it is to pull out the bad answers first, because even with pruning methods there still might be a bit of a performance hit. It seems your intuition is definitely right, in the fact that you’re thinking about it, so I would say not including them in the first place is definitely better. But if you get a good pruning method it might not matter. Or also thresholding matters a lot too, because these prompting functions will give you a logit as the output, and so you can threshold that logit based on how confident you’re feeling about your answers.
Q: [Please] give us an] idea of the influence that formatting your prompts will have on the quality of the output. For example, carriage returns.
A: That’s a great question, [it] definitely depends on the language model. Some of the stronger ones seem to ignore some of that, but that is definitely an ongoing area of research—one that I don’t have a ton of familiarity with. But hopefully, that answers your question, that it’s definitely something people are considering, and it seems a lot of language-specific things actually affect these language models. Although I will say that some special characters are filtered out just in the pre-processing step, so your tokenizer also will play a role in what happens there.
Q: Can you speak more about how weak supervision can be used in answer engineering? I’ve read that null prompts can be just as effective as manually written prompts, so is it worth it to even spend time engineering prompts?
A: Honestly, in my experience I haven’t found prompts to be that effective. I’m sure for prompt engineering to have that much of a performance toggle…. Actually, okay, let me backtrack. I found [that with] prompt engineering there’s ways that you can get it into bigger error modes. So your choice of prompt could have a bad effect, but it seems the average is kind of the upper bar as well. So hopefully that wasn’t too confusing, but basically I’m agreeing that I don’t think it’s worth spending too much time engineering the prompts in the simple cases. That’s not saying that [given] really domain-specific datasets, engineering the prompt won’t have a really high effect, but it definitely feels to me answer engineering is where the domain knowledge matters the most, and really helps out the most. I guess [the] short answer to your question, in my opinion, it’s not worth it to spend time engineering prompts.
Q: Similar to training subject-matter experts to write labeling functions, how do you feel about training them to write prompts?
A: That’s a great question. I think if prompts are shown to be effective, in that they actually have a measurable performance impact, I think it could be worth it. But the previous question kind of alluded to, if they don’t have a performance impact I don’t think it’s worth it and we can just focus on the answer engineering side, which can be a lot more SME friendly.
Where to connect with Ryan: Linkedin, Github.If you are interested in learning with us, consider joining us at our biweekly ML whiteboard.Stay in touch with Snorkel AI, follow us on Twitter, LinkedIn, Facebook, Youtube, or Instagram, and if you’re interested in joining the Snorkel team, we’re hiring! Please apply on our careers page.

Team Snorkel