Join our inaugural Reading Group in San Francisco on April 29. Register now
Latest posts

Research roundup: dive into the latest foundation model research
Snorkel AI CEO and co-founder Alex Ratner recently spoke with five Snorkel researchers about their foundation model research.


McKinsey QuantumBlack experts: exciting foundation model future
McKinsey’s Carlo Giovine and David Harvey present “Trends in Enterprise ML and the potential impact of Foundation Models” at Snorkel’s Foundation Model Summit.


LandingLens: the struggle for and value of democratized AI
Dillon Laird, engineering manager at Landing AI, presents on LandingLens and democratizing AI at Snorkel AI’s 2022 FDCAI Conference.

Cohere’s Alammar encourages effective strategy for Generative AI
Jay Alammar, director and engineering fellow at Cohere, presents strategies to enhance the value of Generative AI.

Snorkel AI Teams with Google Cloud and Vertex AI to speed AI deployment
Snorkel AI, Google Cloud and Vertex AI partner to help organizations transform data into AI-powered systems faster than ever.


Introduction to Kubernetes
This introduction to Kubernetes explains why it became such a popular framework to run applications over the past few years.


HuggingFace research lead on unified foundation models
Amanpreet Singh, Lead Researcher at Hugging Face gave a presentation entitled Towards Unified Foundation Models for Vision and Language Alignment a Snorkel AI’s Foundation Model Summit in January.

Foundation Model Summit Sessions Show Challenges and Promise
Twelve speakers shared their insights into the present and future of foundation models January event; see what they had to say.

Google’s Dr. Arsanjani on Enterprise Foundation Model Promise and Challenges
Ali Arsanjani, director of cloud partner engineering at Google Cloud, presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit.

Foundation Models 101: a guide with essential FAQs
Foundation Models (FMs), such as GPT-3 and Stable Diffusion, mark the beginning of a new era in machine learning and artificial intelligence. What are they and how will they impact your business? Find out in our guide.

Combining foundation models with weak supervision
Combining foundation model outputs with weak supervision yields faster model development and requires fewer ground truth labels.


Operationalizing knowledge for data-centric AI
Snorkel AI CEO and Co-Founder Alex Ratner’s introduction to data-centric AI from the 2022 Future of Data-Centric AI virtual conference.

Credo AI DS head on operationalizing responsible AI
Credo AI’s head of data science explains at Snorkel’s FDCAI 2022 how his team works to operationalize responsible AI assessment tools.
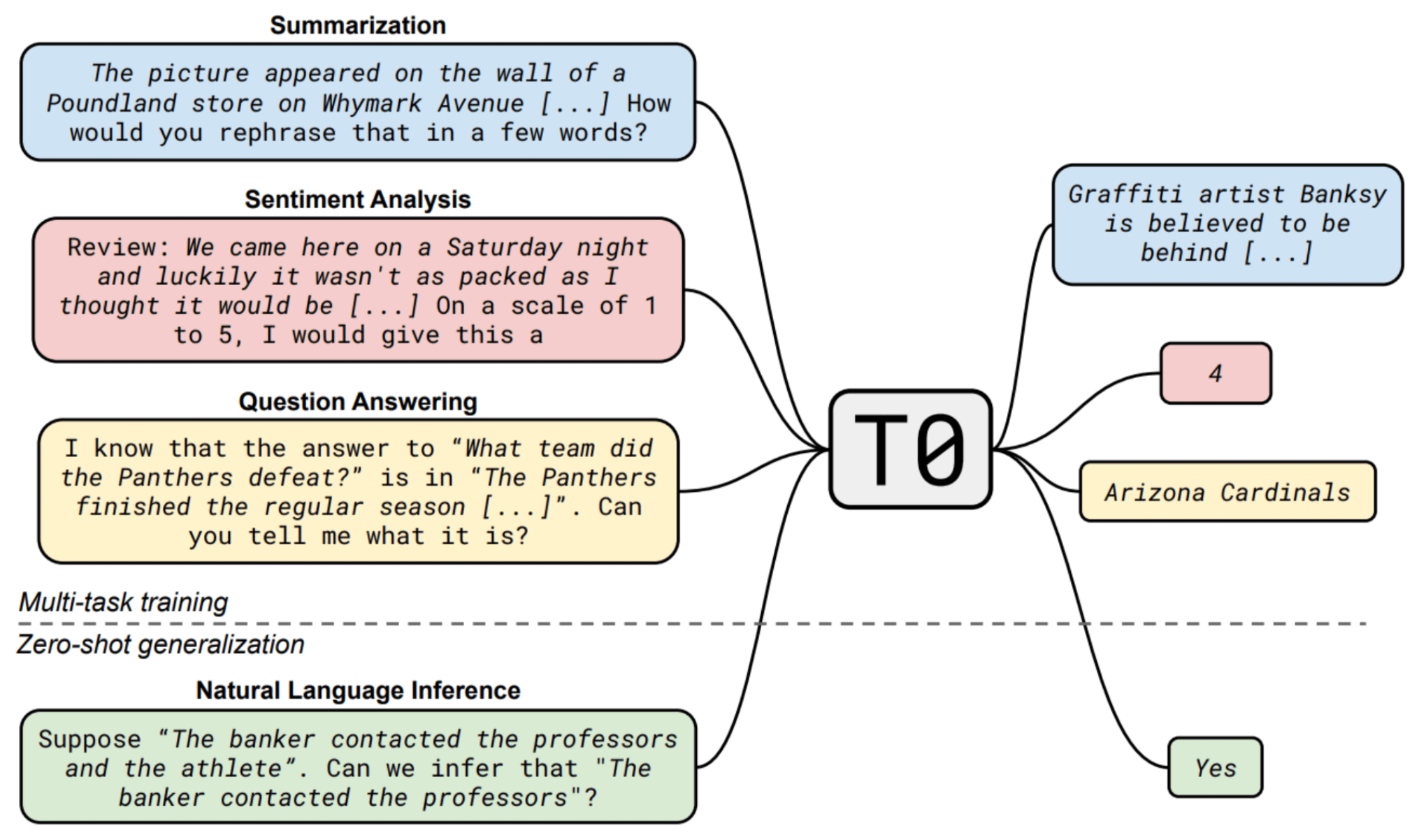
How a Brown professor sharpened and shrunk GPT-3
Brown professor Stephen Bach tells Snorkel CEO Alex Ratner about his research into improving foundation models like GPT-3 with curated data.

Cleanlab CEO shows automatic data-cleansing tools
Cleanlab Co-Founder and CEO Curtis Northcutt presents his company’s automatic, universal and open-source tools to quickly clean data sets.

Aspect-based sentiment analysis in Snorkel Flow
Understanding and quantifying people’s opinions has become increasingly important to businesses, but the way people can express multiple thoughts in the same sentence has frustrated practitioners’ efforts to extract those opinions cleanly—a problem we can solve through aspect-based sentiment analysis (ABSA).


Comcast’s data-centric approach to speech interfaces
Jan Neumann, Vice President of Machine Learning for Comcast Applied AI and Discovery, describes Comcast’s data-centric AI approach to speech.
Meta research manager talks speech and search
Meta senior applied research manager Anoop Sinha and Snorkel AI co-founder Braden Hancock discuss mastering speech and search with TWIML host Sam Charrington.

Using Snowflake Connector in Snorkel Flow
As part of Snorkel AI’s partnership with Snowflake, users can now upload millions of rows of data seamlessly from their Snowflake warehouse into Snorkel Flow via the natively-integrated Snowflake connector. With a few clicks, a user can upload massive amounts of Snowflake data and quickly develop high-quality ML models using Snorkel Flow’s Data-Centric AI platform.

NASA ML Lead on its WorldView citizen scientist no-code tool
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference.
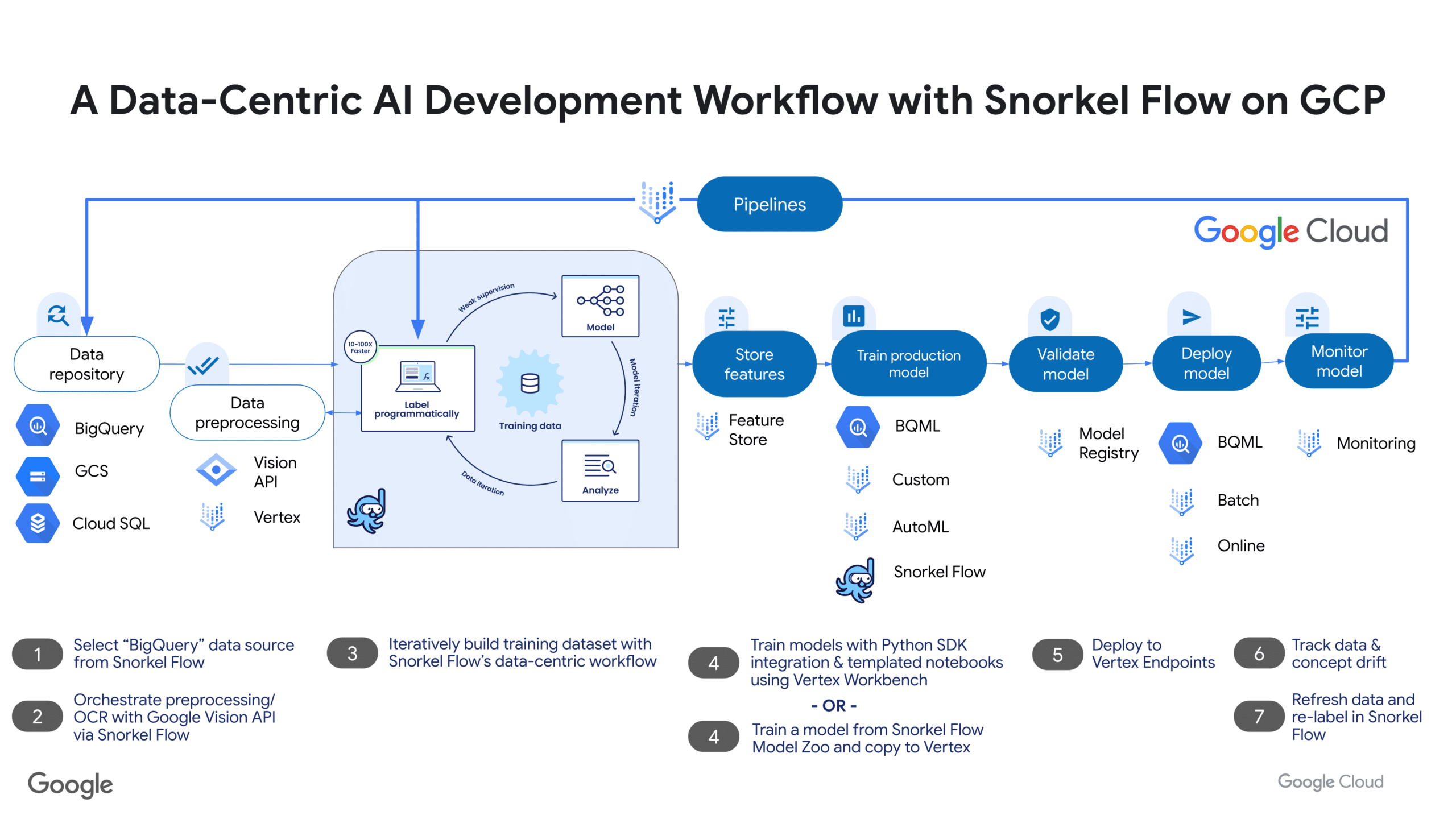
Snorkel AI and Google Cloud accelerate AI innovation
Snorkel AI is teaming up with Google Cloud to help F500 companies and AI innovators solve their most difficult problems.

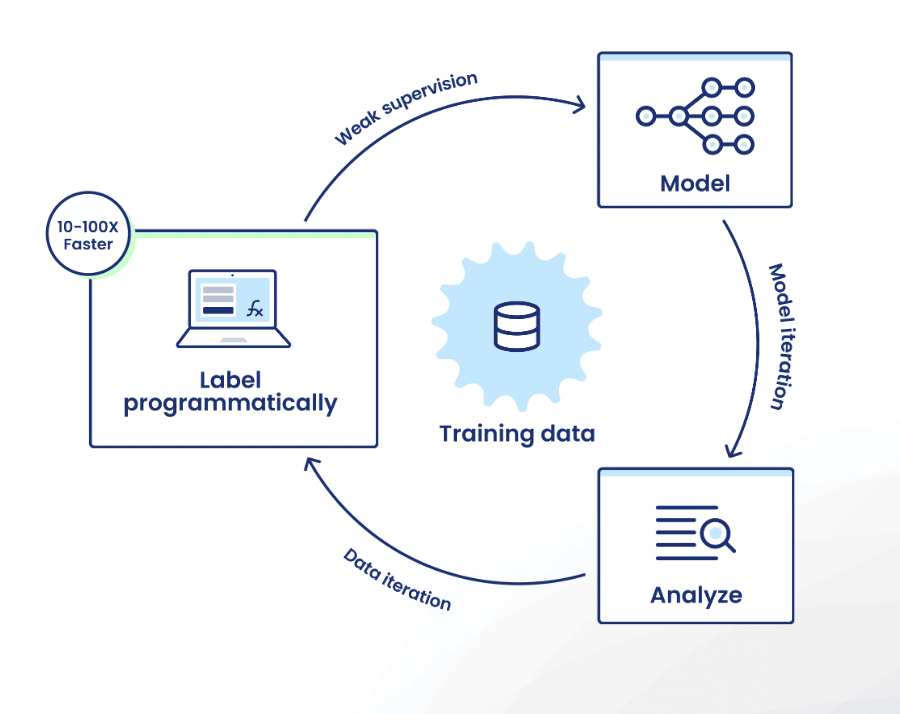
Building better datasets with Snorkel Flow error analysis
As machine learning practitioners, few of us would expect the first version of a new model to achieve our objective. We plan for multiple rounds of iteration to address errors and improve performance, and the Snorkel Flow platform provides tools to enable this kind of iteration within the data-centric AI framework.


Seldon and Snorkel AI partner to advance data-centric AI
Together, Snorkel AI and Seldon enable enterprises to adopt AI across the business at scale by dramatically accelerating development and deployment and tightening the feedback loop to rapidly respond to data drift or changing business requirements.
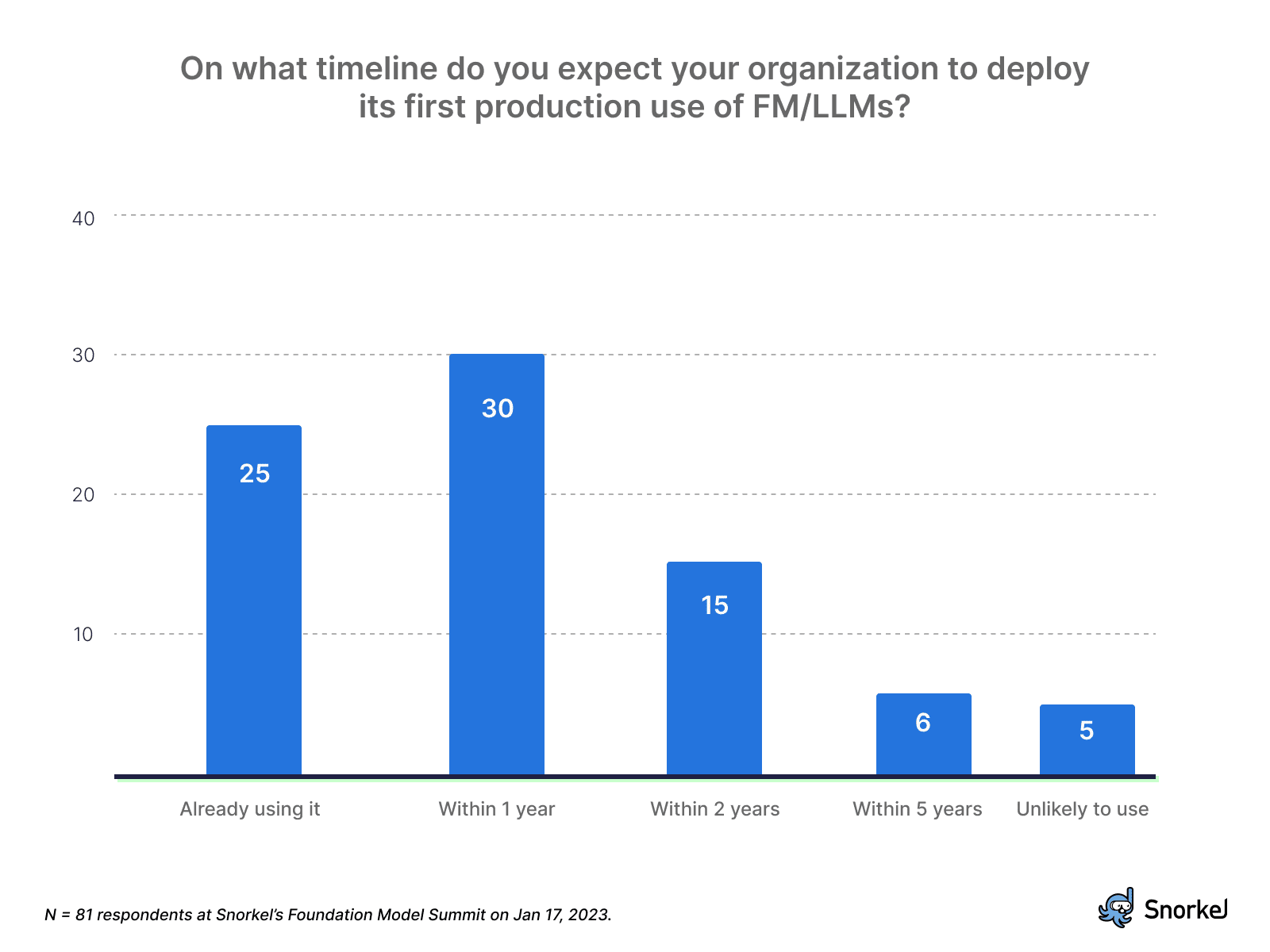
Accuracy top concern for Foundation Model adoption—Poll
Most poll respondents at Snorkel AI’s recent Foundation Model Virtual Summit named questionable accuracy as the biggest barrier preventing them from getting organizational value from Foundation Models.
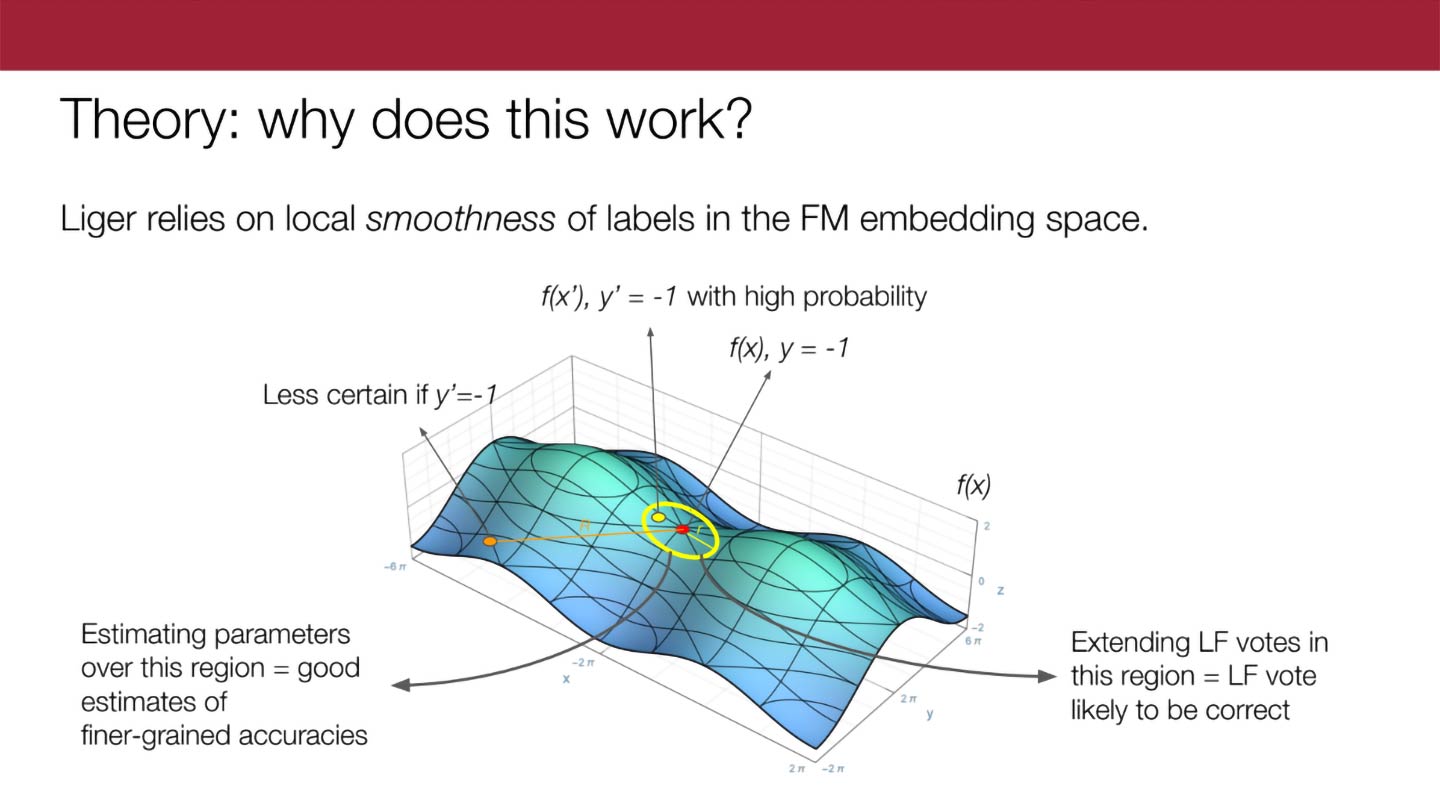
How Foundation Models bolster programmatic labeling
Snorkel CEO Alex Ratner interviews Mayee Chen about how Liger improves the effectiveness of programmatic labeling through foundation model embeddings.

Snorkel AI partners with Snowflake to bring data-centric AI to the Snowflake Data Cloud
Snorkel AI has teamed with Snowflake to help our shared customers transform raw, unstructured data into actionable, AI-powered insights.
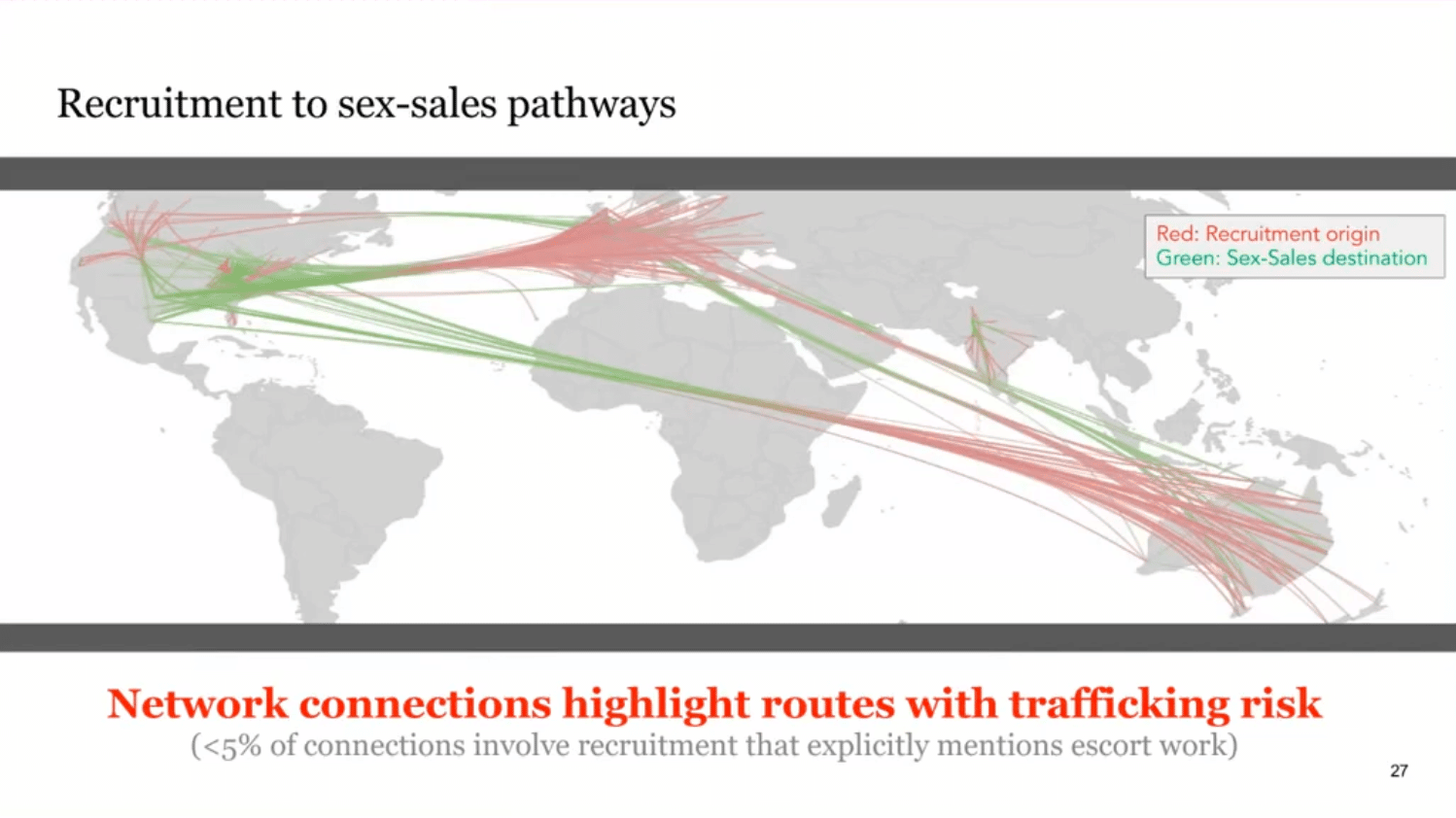
Unmasking Trafficking Risk in Commercial Sex Supply Chains with Machine Learning
Hamsa Bastani presented a summary of her and her co-authors’ ongoing work using machine learning and Snorkel AI’s tools to detect and track activities that are associated with a high risk for global sex trafficking.

Prompting and weak supervision to build better, smaller models
Snorkel AI co-founder and CEO Alex Ratner recently interviewed several Snorkel researchers about their published academic papers. In this video, Alex talks with Ryan Smith, Senior Applied Scientist at Snorkel, about the work he did on using foundation models to build compact, deployable, and effective models.
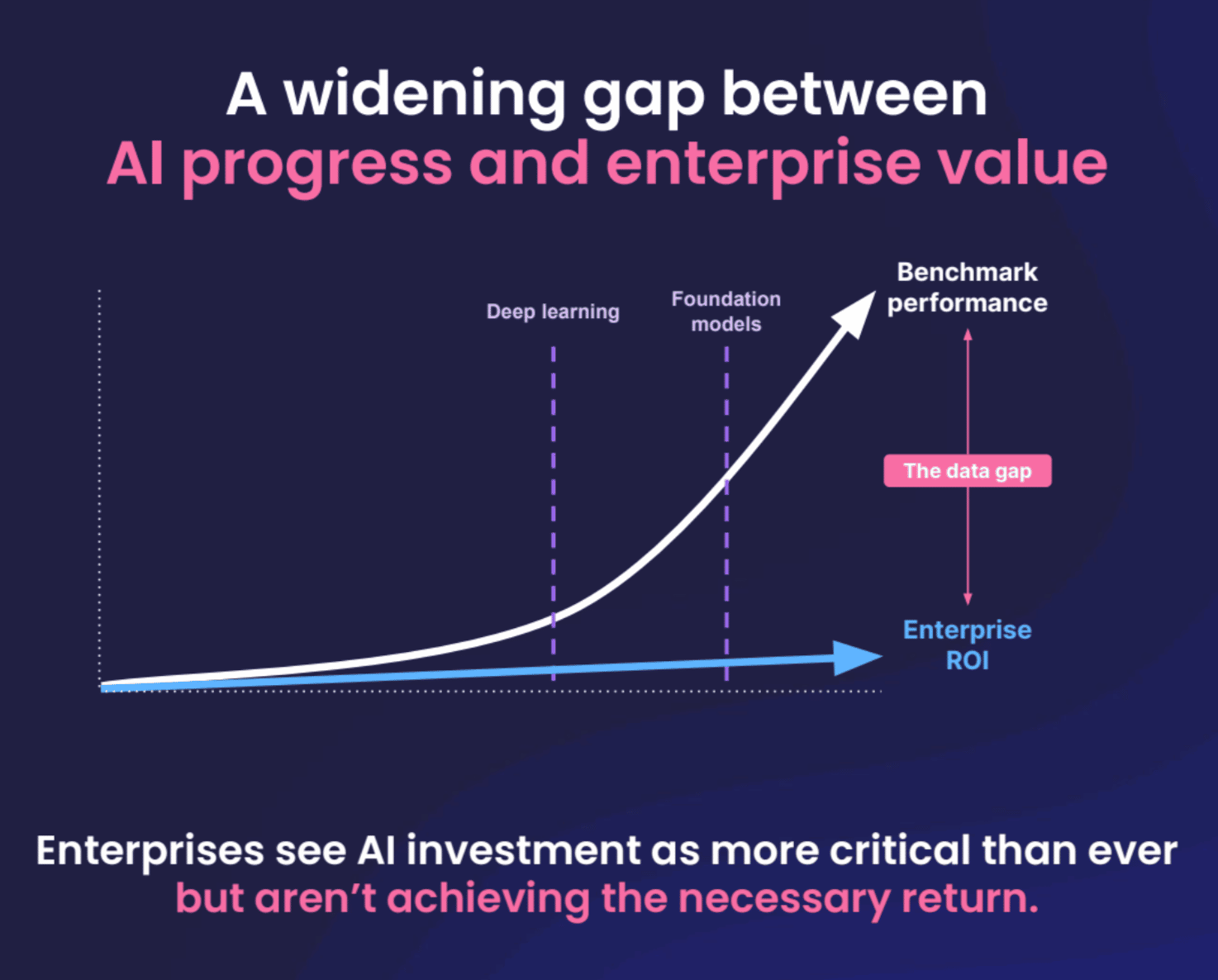
FM Summit shows Foundation Model hurdles and potential
Snorkel AI held its Foundation Model Summit Jan 17, bringing together 12 presenters and over 600 attendees at 10 virtual sessions. The event drew registrants from across many sectors, including the tech industry, healthcare, and financial services.

Contrastive Learning boosts Foundation Model specialization
Snorkel AI co-founder and CEO Alex Ratner talks with Ananya Kumar about the work he did on improving the effectiveness of foundation models by using contrastive learning, image augmentations, and labeled subsamples.
Join our newsletter for expert advice, the latest research, and exclusive events.
By submitting this form, I acknowledge I will receive email updates from Snorkel AI, and I agree to the Terms of Use and acknowledge that my information will be used in accordance with the Privacy Policy.