
Curtis Northcutt, CEO and co-founder of Cleanlab, presented the tools his company developed for cleansing data sets prior to model training at the 2022 Future of Data-Centric AI conference. Below follows a transcript of his presentation, lightly edited for readability.
So let’s just jump in. The talk should be pretty fun. First I’ll chat a bit about millions of label errors and the 10 most common machine learning benchmark data sets. And that should be a surprise if folks haven’t seen the work.
We’ve been benchmarking the field of machine learning on test sets. It turns out that those test sets, the ones that the entire field has benchmarked on, actually have millions of errors in them. This is shocking, and it means that some of the rankings of benchmark models are actually off, and we’ll go more into that.
We had some work in NeurIPS, which you can check out. This is built on a theory that we developed at MIT called Confident Learning, which is a subfield of machine learning for learning with noisy labels, finding errors in data, and estimating uncertainty in data. We’ll chat a bit about that.

And then we’ll chat about why this is important. Why do we wanna have AI for data correction? I think everyone has seen by now in the talks that data-centric AI is useful. You’re in a Future of Data-Centric AI conference, you’re probably on board. But we’ll focus specifically on data correction, and then I’ll chat a bit about what we’re open-sourcing and what we’re giving away and hoping that people will use more and more.
We have an open-source package called Cleanlab that’s growing pretty quickly. Our goal is to make this a foundational general standard tool for data-centric AI everywhere. We’re just adding a lot to it. You can check it out. And finally, I’ll share something called Cleanlab Studio, which allows you to do all this stuff with no code, automatically.
Let’s just jump right in. This is an image I took when I was working at FAIR (Facebook AI Research) in New York, in Yann LeCun’s group. Jeff Hinton was visiting, and I’m sharing this because a lot of people know these two folks in the screenshot. Jeff Hinton was giving a talk on capsule networks, and at the end of the talk he wanted to share his big result—which was that he found a label error in MNIST.

At this time, that was a big deal. His culminating result—and he is like one of the biggest minds in the field—was that there is one label error in MNIST. I share this because it shows where things were in 2016; it was exciting to find one label error. And today we’re finding millions and we’re doing it automatically at scale.
The big idea here is that it shows where the progress is over time and that some of the biggest minds in our field are focused on this problem. This image is an example of an MNIST image that was actually labeled “3” in Yann’s dataset. They’re old friends, so he’s like giving him a hard time.
At the time, back in 2016, the MNIST dataset had been cited 30,000 times. And so I was like, hang on a minute. If the field has been citing this 30,000 times as being error-free, what if it actually has errors? What is the implication for the field of machine learning as a whole and what can we do about that?

In the beginning, we looked at the binary classification problem of how do you find label errors in data and how do you learn? How do you train machine learning algorithms generally for any data set? And for any model for binary classification? Then we generalized that for the entire field of supervised learning. Then we open-sourced this and asked the question: “what if we just took MNIST and we just ran it through the Cleanlab open source?”
What would we get? I’ll show you, everyone can check this out. It’s free. It’s at labelerrors.com.
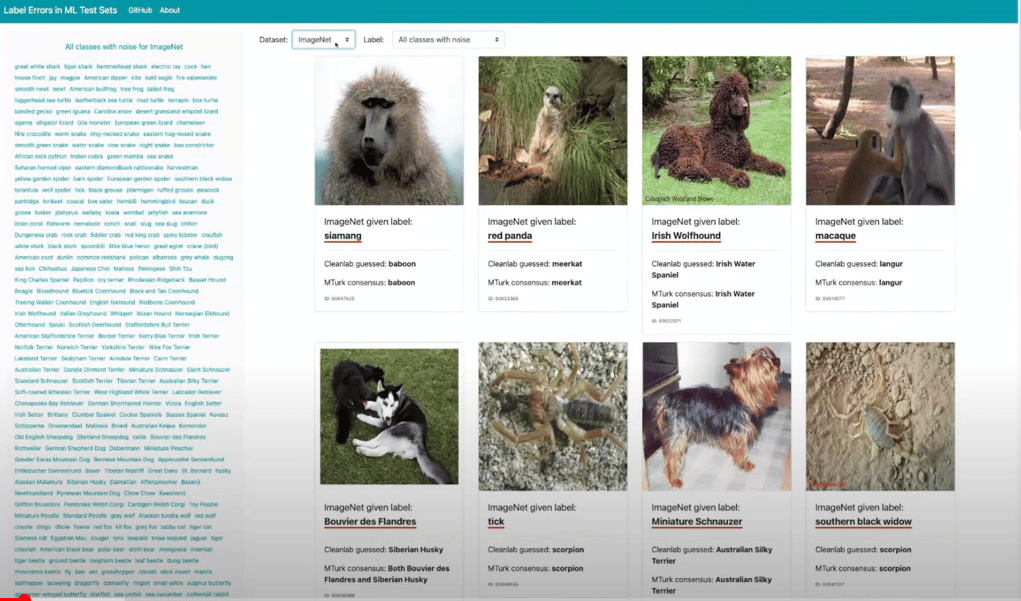
There’s ImageNet, we have all 10 of the most commonly cited benchmark data sets. You can see, for example, this top left image is a baboon, but it’s called siaming. Next to it, is a meerkat, but like it’s labeled a red panda. We can look at ones that are really easy to see. ImageNet is well known to be a tricky and messed up data set, but let’s look at Google QuickDraw.
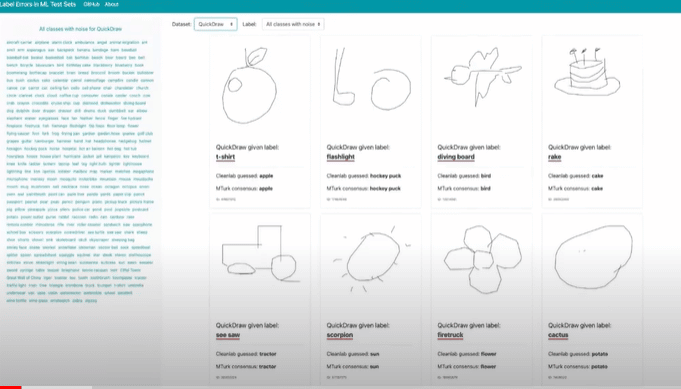
These are a bunch of drawings and the one at the top left is labeled t-shirt. It’s clearly an apple. Another is labeled scorpion. It’s clearly a sun. And there are millions of these. You can just scroll through them. It’s pretty fun. You can check out any type of dataset. Cleanlab is a general tool for any modality.
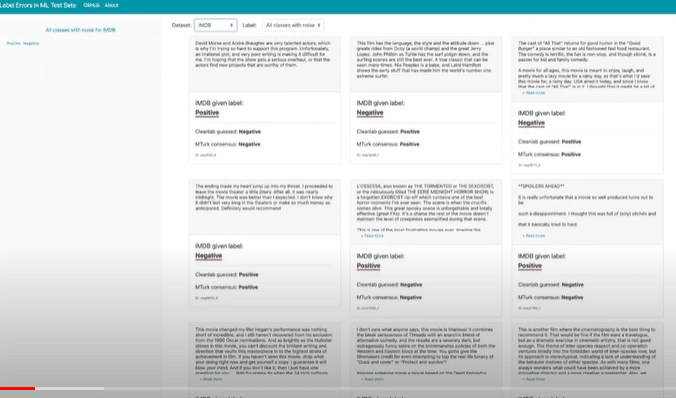
For example, these are text data sets where it says “They’re very talented. But unfortunately, it’s an irrational plot and it’s a bad movie.” The label that was given was positive. You can see we correct that to negative.
Going back to the slides, these were some of the original errors that we found in MNIST in the early days:
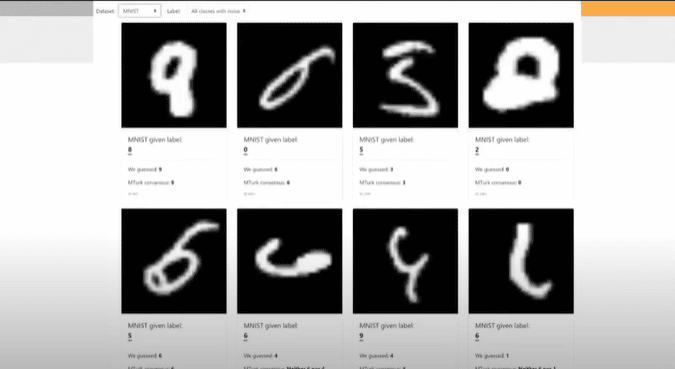
You can see, for example, in the top left the nine was labeled eight, and next to it the weird six-looking thing is labeled zero. They’re borderline out of distribution, but they’re definitely errors that shouldn’t be in the dataset.
That is a statement, by the way, that gets confusing whenever you’re thinking about labelers. The question is: does an example even have a true label? Often that’s actually not true. Most examples are somewhat ambiguous. But when we train machine learning algorithms, especially in supervised learning with a single class, we make the assumption that it has a single label.
The idea is: can we actually provide good training data? And most importantly, can we provide good benchmarking data? And the folks who are doing the annotations for that data, can we identify what’re the most high-quality annotations, low-quality annotations, and annotators? This is a general framework to achieve that.
So, some quick summary of the results and why it’s important for the field. We looked at six image data sets, three text data sets, and one audio dataset (not included in this presentation). It turned out that—across these—there were millions of errors. Some of them had more or fewer errors, and I’ll show a table on that in a second. But first I want to say how we actually found this.
The idea behind finding label errors is that we first have an automated step. Then there’s a way to do human verification.
For the research side of things, we used Mechanical Turk to verify, and nowadays we use Cleanlab Studio. How do we find these errors? In confident learning, the idea is that this is theoretically grounded.
What we can do is we can actually prove—this is pretty cool—realistic sufficient conditions where there’s actually error in every single predicted probability in a model’s output for exactly finding label errors. And that’s pretty cool. We can do that for any dataset, for any model, and what it requires is that the models’ predicted probabilities are within some range of perfect, but they can all have errors.
I’ll go into that briefly in a bit. The neat thing about this is it provides practical algorithms, so they can work on large data sets, unbalanced data sets, for any model and any dataset. I’ll show you just generally how it works. The idea is that there are systematic errors, so it’s actually pretty easy to find random errors.

You’ll notice a lot of works will focus on random label flipping. If you have a thousand classes and you have say, a thousand errors in ImageNet, that would mean there’s only one error in every class if you had uniformly random labels. That’s pretty easy, right? What’s more realistic and more problematic, and real-world, is systematic error.
For example, a fox is much more likely to be labeled a dog than it is a cow. Or a keyboard is more likely to be mislabeled as a computer than it is a banana. And so what you see in real-world datasets is most of the error is actually just in a few classes. Can you still find all the errors, even in that case, when you’re confusing the model a lot more versus uniformly random?
The answer is yes. And we’ll show how to do that. (See equation in slide above.) The key idea is that you make the assumption that the data itself has no implication on the flipping rate, which is not true, but it is reasonable.
For example, if you know that person is, say, a doctor, then you have some probability that they’re interested in medicine. And so knowing more information about the person is helpful. But if you do know this is sort of a true label white star, then it gives you a lot of information about your noisy label.
Another way to think about this is just say you have an image, that you have dogs and cats. What this is saying is we don’t care what the exact image is of a dog, there’s just generally a flipping rate probability that a dog image is mislabeled as a cat image. The notion this captures is that there’s definitely a clearer difference between the probability of a keyboard being flipped to a typewriter than there is a keyboard being flipped to a banana or the wind or a tree.
These are definitely very different numbers and so we’ll estimate all of these. If you have K classes, this would give you a K by K matrix and that’s what you want to estimate. So that’s the thing on the right, and this is the full joint distribution of label noise.
This is how we find errors. If you have this thing, you’ve pretty much solved your problem. So let me just be clear. This point zero eight down here is saying that if you have a hundred examples in your data set, this would mean that eight of your cow-labeled images actually should have been labeled “dog.”
And it would say, for example here, that you have 20 cow-labeled images that are correctly labeled cow. So this fully specifies, or you can say fully characterizes, label noise in a data set. That’s what we want to estimate. We use this method, these are the results on those 10 data sets, by the way.

You can see percentage errors are much higher in QuickDraw, for example, than MNIST, which would have had very few errors, but the errors that were in there were surprising. And some of these have more or fewer errors and the amount of error definitely impacts the benchmarks.
I’ll show you briefly how. We ask this question: Okay, there are a lot of label errors and test sets, but what is the implication for us as a field and as a society, as a bunch of practitioners who are trying to benchmark and understand machine learning models? Because when a new model comes out, we’re going to benchmark it on these data sets.
Can we actually trust that it’s better than the other ones, given that there’s all this noise? And so we looked into that. This is a paper that was nominated for best paper at NeurIPS last year in the Date Sec Datasets and Benchmarks track and I encourage you to check it out if you’re interested.
This is where we looked at all the label errors in the top 10 most commonly cited datasets. And here’s the key idea.
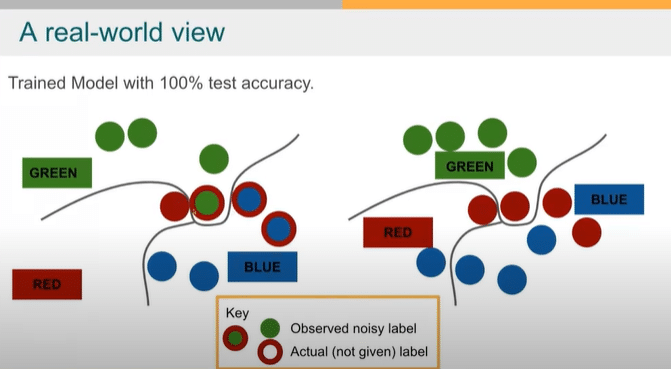
On the left, you have some trained model that has 100 percent test accuracy, but your test set has noisy labels. So these things that are circled red—red is the true label, but you don’t know that—you don’t get that right. You have a test set that has errors in it. Instead, this thing looks like green, this thing looks like blue, cause that’s what it’s labeled. So as far as you know, your test accuracy is 100 percent. Now, in the real world, the true label of that is red. So the real-world test accuracy is 67 percent.
Now, imagine that this is a self-driving car. The difference now is the car drives off the cliff 0 percent of the time, or it drives off the cliff 33 percent of the time. You can see how this can be a pretty serious issue if we don’t have the real-world test performance calibrated to what we observe when we’re doing our research papers or doing our benchmarks. And that’s the thing that we want to solve.
So, a key takeaway is that you need a corrected test set, or you’re going to have this difference between real-world performance and what you’re measuring.
We wanted to know if practitioners are unknowingly benchmarking ML using erroneous test sets. The answer is yes. It turned out—which was a very surprising result that you can see more in the paper—that with just a six percent increase in noise prevalence in datasets like ImageNet and CFAR, you would have something like RESNET 50 actually underperforming RESNET 18. But in the benchmarks, it will look like RESNET 50 is outperforming RESNET 18. Actually what’s happening is it’s overfitting to the noise.
I don’t know if that makes sense, I’ll just repeat it very quickly. If you have just six percent more noise in ImageNet, CFAR, any of these data sets, and then in, QuickDraw the benchmarks are already broken, but in some of the more stable ones that have a little bit less error if you just bump up the error by six percent, then what you’ll observe is that RESNET 18, if you corrected the test set, RESNET 18 actually is outperforming RESNET 50. But you’ll never know that. As far as you’ll know using the noisy test data, RESNET 50 will continue to outperform RESNET 18. And that’s just because your model has fit to the noise. There’s noise in the test set, so it does well on the test set.
The second thing that we were really surprised about is that these test sets are actually a lot noisier than folks thought.
At this point, I want to jump into a bit more about the theory and how we found this thing.
That was confident learning. I’m gonna jump into my PhD defense slides because there’s just a really nice example here.

The idea here is that it’s actually really easy to prove with the confident learning approach. Let me quickly show the confident learning approach. Let’s go back to our example; a fox is more likely to be labeled “dog” than “bathtub.”

This was our joint distribution. And the question is: “how do we estimate this thing, right?” So this idea is 3 percent of your cow images are actually labeled “fox.” We’ll look at how we estimate this. We only need two things to estimate it. One is the predicted probabilities, and two, is the noisy labels.

This is just your output of your softmax of some model. It doesn’t matter what the model is or the data set, and these are just the labels that you have. Then we compute these thresholds. And this is a really simple thing. This is actually just a mean and you just take the predicted probabilities for everything that is in Class J.

So it’s labeled J. These are labeled “dogs” and these are dogs, and you get the probability of being a dog. You just take the average. That’s it. This threshold is the threshold for a class “dog.” The reason why this is useful is that models are not consistent. They’re heteroscedastic, meaning that they have different performance for different classes, and most label-fixing approaches don’t consider this.
It’s very problematic because you might have some model that’s 10 percent accurate on some class and 90 percent on another. It just tends to have very high probabilities for the class that it’s more accurate on. So you want to keep track of a notion of how confident the model is in each class.
This is a simplified version of the equation for how we can build that joint.
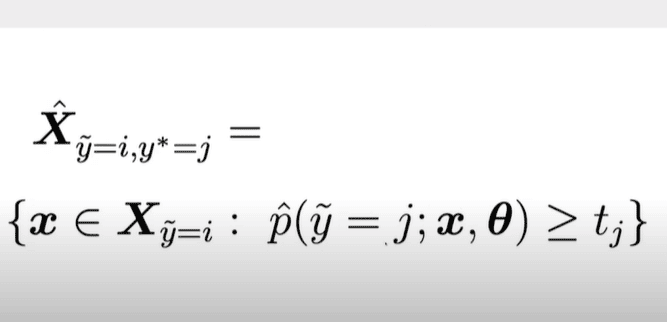
So all we’re going to do is look at, for example, what is the probability that it’s Class J that could be “dog.” And is that greater than the threshold for the class dog? And if it’s greater than the threshold, but it’s actually labeled class I, then we’re gonna count it as noisily labeled Class I and actually labeled Class J.
If the probability is greater than some threshold, and we actually proved that’s the correct threshold in the confident learning paper, then you can count up the things that are probably labeled, a dog, but they’re actually given the label cat, for example.
You do that for the entire matrix and that’s how you get the joint. At this point, I’ll just show really briefly some of the theory side of things and why you can have a little faith that this is working correctly. That’s what we should be asking, right? You show a formulation, it looks pretty simple. It seems like it should work. Let’s get some intuition into why it should.
Here’s the sort of formulation at the top, and I’ll go through this really slowly because it’s actually really simple and it’s really clean. You’ll have to take this for granted, but it’s pretty easy to prove.

If you have perfect probabilities, meaning you have a model that has no error, then you’ll exactly find label errors. So just take that for granted. What we’re going to see is if you add error to every predicted probability for each class. So for every class you add some error terms.
So the models are overconfident in some class or underconfident in another. What happens? Is it robust to that? If you have a model that’s overconfident in certain classes, will confident learning still exactly find label errors? That’s what we’re going to check right now. Remember: this is the threshold formulation, and we’re gonna add an error term, this “plus ej”.
For every class, we’re going to add error. That could be a plus or minus, right? The error can be negative or positive. It can be overconfident or underconfident for that class. And we’re going to recompute our thresholds. So when you compute a sum with a something added that addition drops out, inside of the average, right?
This is gonna average out, and you’re gonna have your threshold just plus the error, that’s your new threshold term for these erroneous predicted probabilities. Now if we look at the Cleanlab formulation, we have the predicted probability, which has an error term, and we check: is it greater than the threshold which also has the error term? And you see the error term drops out. You actually get your original formulation.
This here is exactly identical to this here. It’s just the predicted probability greater than the threshold, and we’ve already proven that this exactly finds label errors for this predicted probability, the correct predicted probability.
So we’ve shown that the error term drops out and you still exactly find label errors even with error in each class. So that’s a very simple way to show there’s some intuition here in terms of why you should trust this. In the paper, we go more general and show how this works for error in any predictive probability.
Hopefully, that gives some motivation why you can trust a formulation like this versus just, hey, check out some math and trust that it’s intuitive.
I wanted to show the sort of obligatory table of these confident learning methods with recent work in learning with noisy labels.
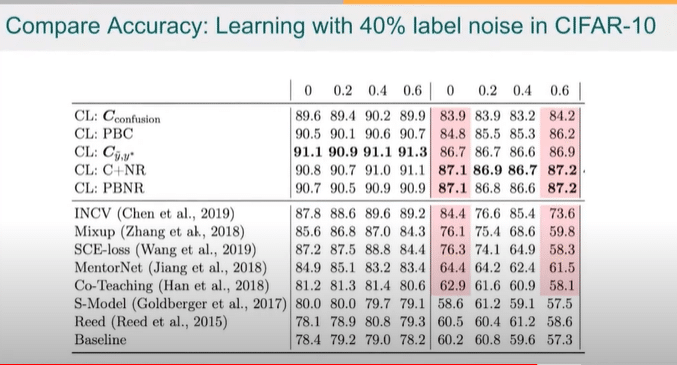
There’s really two things I want to emphasize here for the data-centric AI community, specifically. The first one is that, on the right here, what I’m showing is the fraction of the off-diagonals in that confident joint.

So remember this guy:

So the fraction of these that are actually zero, we call this sparsity and it means that the noise is just in a few classes.
That’s realistic. Because, in the real world, it’s very unusual for a bathtub to be mislabeled “keyboard” or “banana,” right? Most of the error rates are actually zero. Tthis is saying is that 60 percent of the error rates are zero [see 0.6 at the top right of the image above].
And what you’ll see is that the confident learning approach gives you the same performance regardless of how many fractions of zeroes there are in the off-diagonal, meaning how realistic the noise is. But if you look at some of the previous approaches, you’ll see that there’s a massive drop off in performance when you make the noise more realistic and less academic in nature. So that’s one point.
The second point—and this is for the folks who are really pro data-centric AI—is if you look at the ranking and the way things fall out, all the models on the bottom are actually model-centric. The way that you know, if you’re familiar with these methods at a high level, these are the methods that adjust the loss function in order to learn with noisy labels.

But these that perform the best are the ones that actually modify the training data. This is a very clear indication that there is something to this data-centric AI from an actual benchmarking perspective. You can show that data-centric AI methods tend to outperform. For folks who are interested in data-centric AI, this is a motivating result that you can check into and see, hey there’s something behind this besides the hype.
I’ll just show two more things. You can check out some of the use cases for AI for data correction in this blog post and see how Google uses Cleanlab, how we use it at Facebook for various things, and how it’s used for cheating detection at MIT and Harvard.

We also used it at Andrew Ng’s data-centric AI competition where you can find really clear errors. There are a bunch of other use cases, but in general, check out the open source.

These algorithms are all freely available.
While I was doing my PhD at MIT, I put everything online and shared it so that I could get feedback. The real reason why we open-sourced this was that people had trouble believing that you could actually just find errors in any dataset. So we open-sourced it, which addressed those questions.
The final two things: One, this is a general framework that you can use if you want to find errors in your own dataset.

You import Cleanlab, and then one line of code. It’s a clean learning module. You pass in whatever classifier you like, and then call dot find label issues with whatever your data is. It can be a data frame and just like a list of labels.
The final thing I want to show briefly is Cleanlab Studio. The idea behind Studio was: can we make AI for data correction accessible to everyone?
If you build something, you say, hey, this is practical. Let’s actually have a tool where, with no code, entirely automatically, you can drop a dataset and you can find all the errors and correct them in an actual SaaS automated way. That’s what we built at Cleanlab.
Here’s Cleanlab Studio. This is a real-world data set from Amazon.
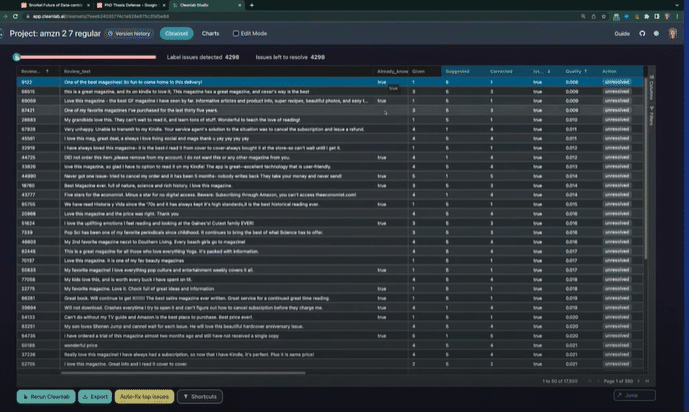
It’s showing a one-star rating for this movie, and we checked and we know this is an error.

We dropped the dataset in and all of these things are computed automatically for you. So you get a ranking over every example, whether it’s true and or whether it’s an error or not. And then we give the corrected label for you. We just dropped this data set and it’s done.
And the beautiful thing is Studio works with any dataset from any model.
So, that’s it. If you want to contact me, you can do so. Here are the main contributions and how to contact me. Thank you.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

