
Ian Eisenberg is the Head of Data Science at Credo AI. At Snorkel AI’s 2022 Future of Data-Centric AI virtual conference, Eisenberg gave a short presentation on the way he and his colleagues are working to operationalize the assessment of responsible AI systems using a Credo AI tool called Lens. A transcript of his talk appears below, lightly edited for readability.
My name is Ian Eisenberg, and I head the data science team at Credo AI. Credo AI is an AI governance company, and we are creating a comprehensive governance platform to support needs, from assessing AI systems to reviewing and auditing those systems.
Today I’ll be talking about operationalizing responsible AI. By operationalization, I mean the process of turning abstract concepts into measurable observations and actions. It’s a necessary step in connecting our larger goals in AI with development practices. The most common example nowadays is fairness.

Fairness is an abstract concept. Metrics of disparate impact are a kind of operationalization. If you find that your system has a low disparate impact, according to some metrics, that’s good! But we must remember that it’s just one operationalization about the thing we really care about: that the system is fair.
The other concept is responsible AI. What is responsible AI? Many principles have been thrown around, and consensus is starting to emerge, settling on some key tenants, like fairness, robustness, explainability, et cetera. While we focus on these principles, we should remember that they too are the beginnings of operationalization and will be iterated over. In the end, what we really care about is ensuring that we know how our AI systems are behaving in a multitude of ways and directing their impact to be beneficial for all who are affected by them. This talk will cover some aspects of how we do that, and in particular, a tool that we are developing at Credo AI to support it.
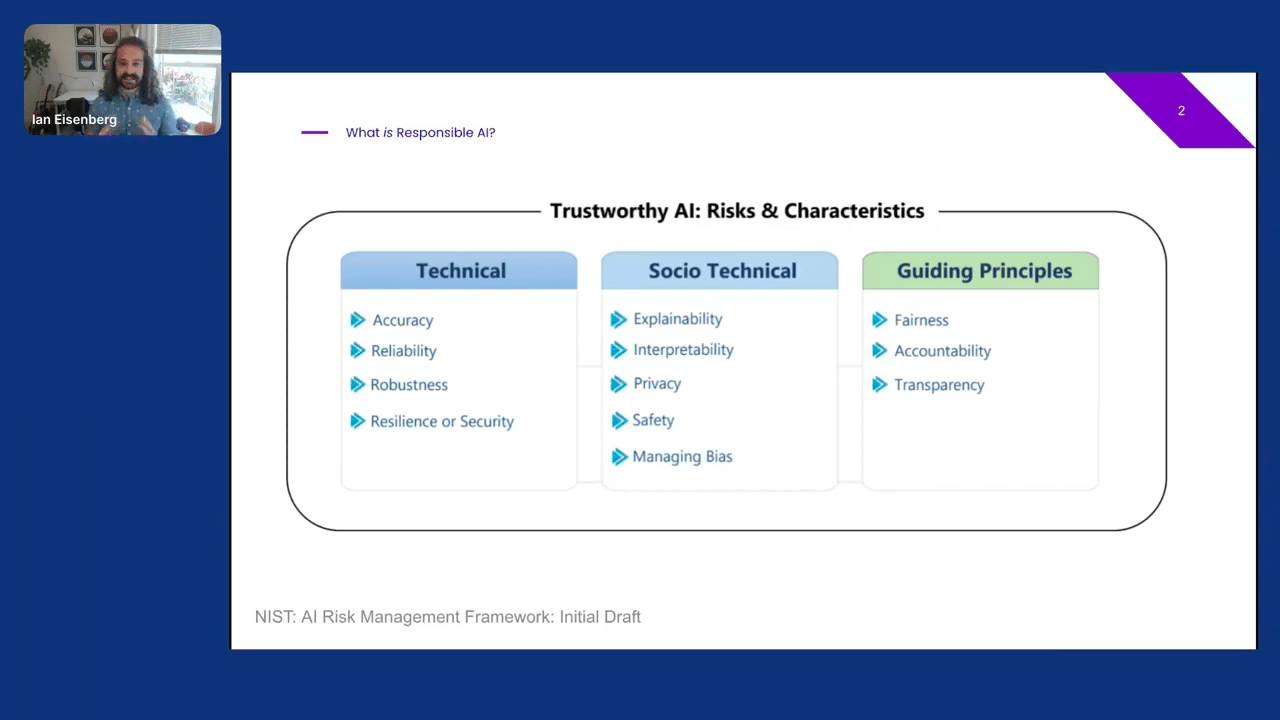
So, let’s look at a specific instantiation of responsible AI tenants. Here we see a proposal from the US standard-setting body NIST. It’s similar to many others, but one nice aspect of this taxonomy is that they separate principles into three categories: technical, socio-technical, and guiding.
Technical aspects are largely functions of the system itself. You can imagine automating them, creating safeguards and tests that reflect a robust or secure AI system. Many of us are familiar with evaluating the accuracy of our system, for instance, using specific performance metrics we all know and love. Some of us may even have in-deployment monitoring of these performance metrics.
One way to think about this area is that we are more comfortable with our operationalizations here. They’re relatively mature. Accuracy is not the same as the precision of my system, but a lot of work has already been put into understanding the relationship between these two concepts.
At the other end of the spectrum are guiding principles. Guiding principles are the highest level ethical principles that an organization aspires to, and are often disconnected from day-to-day development. Sometimes there is an AI ethics or governance team that tries to apply these principles, with varied success depending on their integration with the rest of the organization. How do you operationalize transparency? It’s not going to be as straightforward as evaluating the accuracy of the system.
In the middle, we have the socio-technical aspects of the system. Understanding these aspects requires technical expertise and assessment, but also requires a human perspective and an understanding of how the entire development process operates.
The challenge is connecting our principles with our technical approaches. How do our goals actually show up in the way that we develop our systems? A flurry of work is devoted to improving our operationalizations here.

In the governance risk and compliance space, people talk about gap analysis as the first step towards reducing risk and improving your system. Consulting wisdom states that you can’t manage what you can’t measure. Given how early we are as a field, I think we can learn from these perspectives. The first step of operationalizing responsible AI is operationalizing the measurement of responsible-AI-relevant components of an AI system. We must set up the infrastructure to actually know how our AI systems are being developed and map how they’re behaving.
In the rest of this talk, I’ll outline some aspects of the development system that should be observed, and I’ll start with some high-level points before introducing a tool for the comprehensive assessment of AI systems on a technical level.

During AI development, many aspects of the system can be made more explicit and measurable. Defining your goals through governance in a use-case-specific way is an important step. Making sure you are assessing your data sets and models comprehensively is critical. And understanding who is making the development decisions is important to make the whole process accountable.

During deployment, there are also a number of ways you can improve observability. Monitoring specific audit plans and getting user feedback are all ways to build up your in-deployment measurement infrastructure.
However, while there is more to responsible AI than just observing the state of your overall process and system, I’d argue that we need to focus here first before moving on to other aspects of improvement.
Above all the other aspects I highlighted. One aspect is foundational, and that is: assessing AI systems, both before deployment and continuously as they are operating. We have made progress on defining our societal objective function for AI systems, but now we need to ensure that we have the measurements to inform everything else. The best way the field can support here is by building tools to make more comprehensive AI assessment possible.

There’s a vibrant ecosystem of open-source responsible AI tools. I’ve listed some of the most popular on the slide, but smaller tools are being developed all the time. One issue with the open-source ecosystem is ease of use. It’s often difficult to know which responsible AI tools actually exist, let alone how to integrate them with current workflows.
Another issue is in the translation of the results into a broadly accessible language. Diverse people have a stake in and a useful perspective on how AI systems should be developed, and some will not be well-versed enough in the technical language that these tools use. Yet, we must bring them into the conversation.

Both of these issues are why we have decided to offer our own offering to the open-source ecosystem, which is Credo AI Lens. It is an open-source assessment framework that provides a single standardized point of entry to the broader responsible AI ecosystem. With Lens, developers have easy access to a curated ecosystem of assessments developed or honed by Credo AI and the broader open-source community.
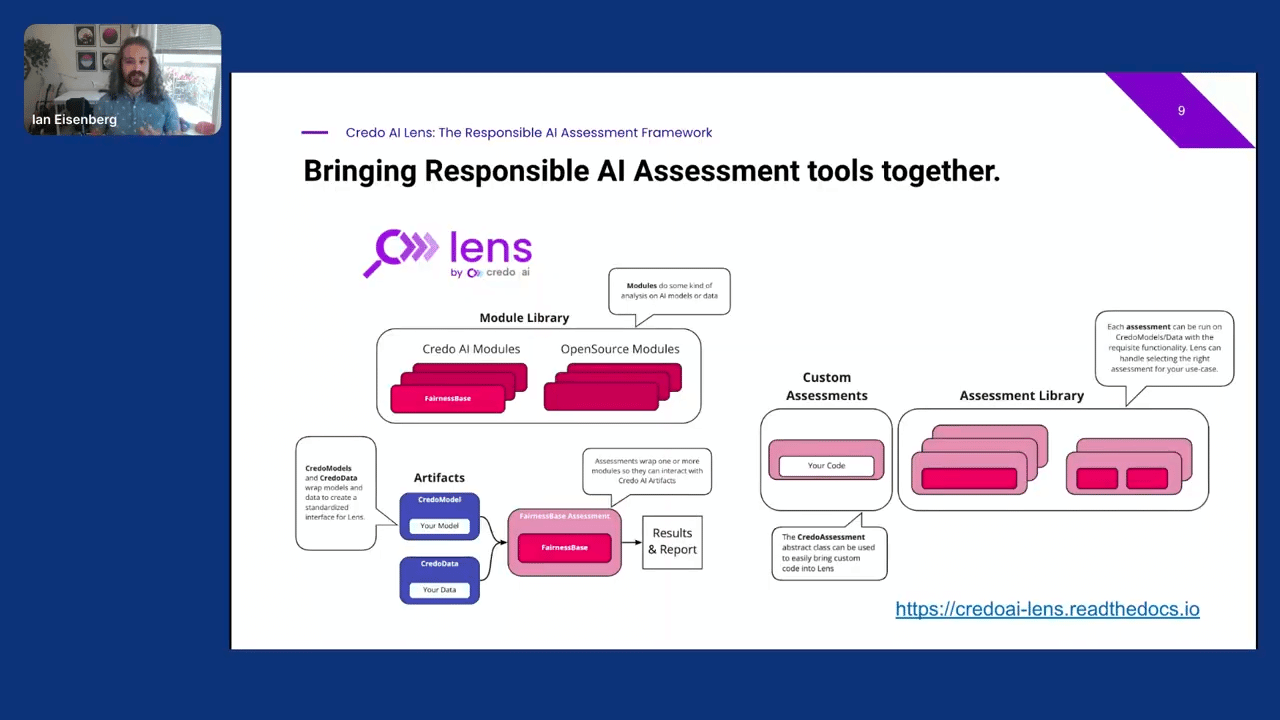
Lens starts with a module library that is composed of tools we’ve built as well as wrappers around other open-source tools like those listed on the previous page. A challenge for the ecosystem is that every model and dataset is different, and each module has its own APIs. These features make it hard to set up a generic system.
To deal with this issue, we introduced lightweight wrappers around models, datasets, and modules called Credo Models, Credo Data, and Credo Assessments. These three wrappers allow seamless integration. They also mean that Lens is extensible. New modules can be added and wrapped in Credo assessments, and you can even add your own customer assessment scripts into the general framework without incorporating them into the library as a whole.

So Lens’s capabilities are always growing, but its primary benefit is a single toolbox for a suite of responsible AI needs. This includes model and data assessments for performance, fairness, robustness, et cetera. We’re also expanding it with our own implementations. For instance, we’ve put work into the evaluation of NLP models.

To wrap up, I want to show you what this looks like in practice. An important aspect of ease of use is how easy or hard it is to incorporate the tool into your existing workflow. Lens is a Python module, and here I’m showing you all the code that you’d have to use to include it and bring responsible AI assessment into your system. Importantly, all of the data and model information is kept within your system by default.
So the first step is wrapping your model and data, so that Lens knows how to interact with them. We use Credo Data and Credo Modules for that.
The next step is to configure your assessment. We take care of a lot of sensible defaults under the hood. But some aspects, like which metrics you’ll use, are almost always going to be customized for your use.
And that’s it. The final step is just to run Lens. In this example, Lens will automatically determine which assessments it can run based on the capabilities of the model and dataset. You can choose which assessments to run if you want. We want to make sure you’ll get everything you can by default.

To conclude, I hope you’ll check this tool out on GitHub. We’re in active deployment and we appreciate any feedback, issues, or success stories. We want Lens to be practical, easy and comprehensive.
Hope to build it with you! That’s it. Thank you.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

