Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Resilient enterprise AI application development
Using a data-centric approach to capture the best of rule-based systems and ML models for enterprise AI
One of the biggest challenges to making AI practical for the enterprise is keeping the AI application relevant (and therefore valuable) in the face of ever-changing input data and evolving business objectives. Practitioners typically use one of two approaches to build these AI applications: rule-based systems or machine learning models, each of which come with their own strengths and weaknesses. In this article, we’ll outline these tradeoffs and introduce a data-centric approach that allows enterprises to capture the best of both worlds while overcoming their shortcomings.
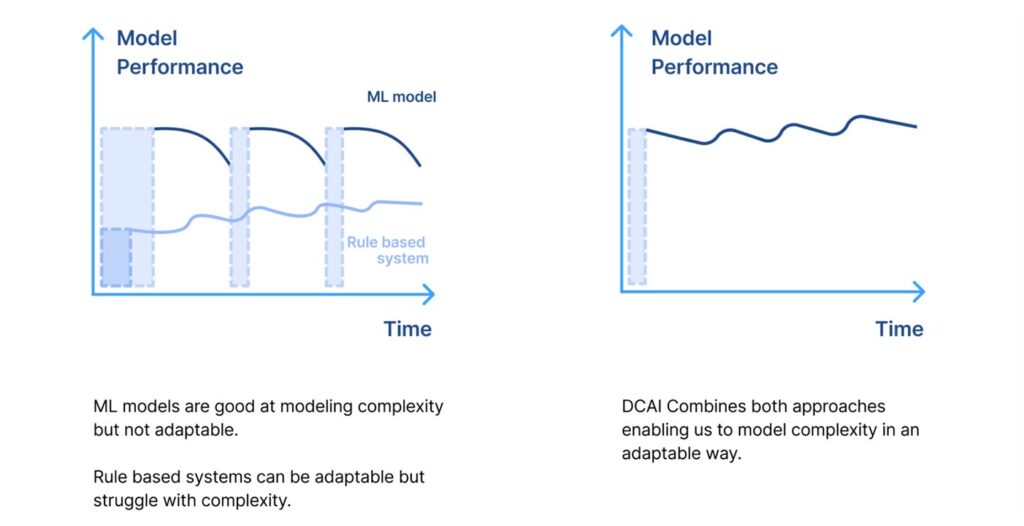
- Rule-based systems are good at modeling simple processes, and allow practitioners to intervene directly to account for occasional explicit changes. However, because they need prescriptive guidance on every decision, they’re brittle (unable to handle much complexity without falling apart).
- Machine learning models, in contrast, are very good at managing complexity. Machines, through training data, learn complex and layered relationships, making them more resilient (able to handle conflicts and coverage issues). However, vast amounts of training data are needed both for initial learning as well as for responding to real-world changes, which can make them impractical to build and maintain for most enterprise AI use cases.
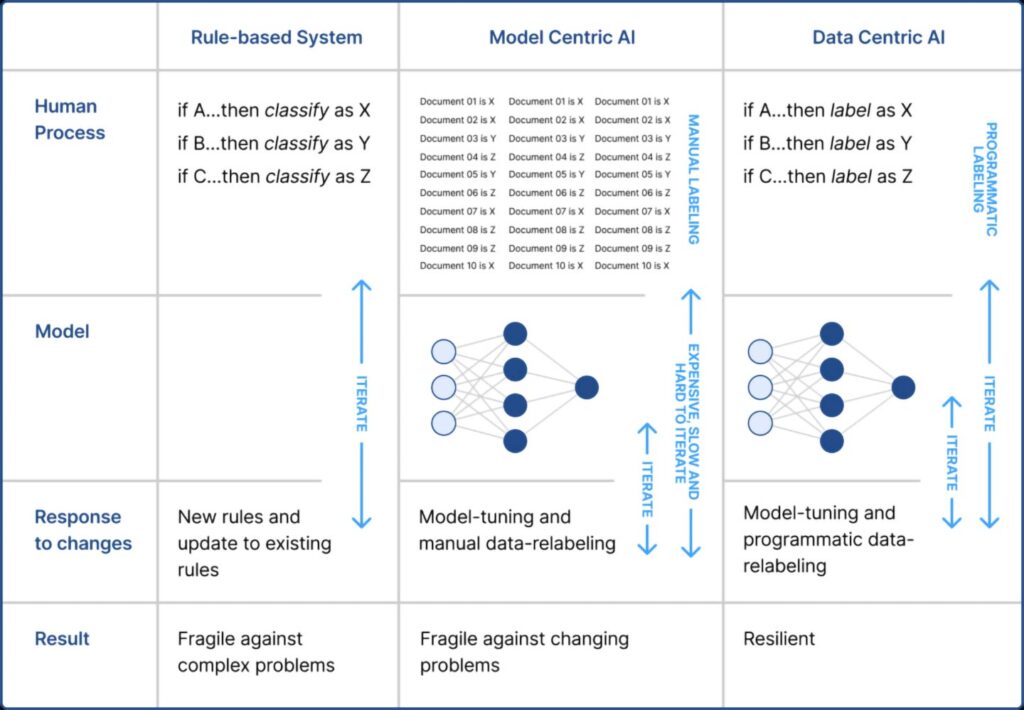
Data-centric AI is an AI development approach that makes it possible for enterprises to maintain the approachability and efficiency of rule-based systems and access the power of machine learning models to address complex problems. The key to unlocking the best of each of these approaches lies in a new, programmatic approach to labeling training data that makes rapid, guided iteration possible. This approach not only makes AI development faster but the resulting AI applications more accurate and adaptable.
Rule-based systems
Some problems or processes can be solved with straightforward rule-based systems. Data scientists capture the rules that a domain expert would use to make a decision or to take an action, and build an application to scale the process.
Rule-based systems were among the first methods developed to efficiently apply a subject matter expert’s insight and intuition across an organization’s data. They are technically approachable, making development relatively easy. When applicable, rule-based systems allow an organization to rapidly apply a set of human-understandable heuristics across a large amount of data, saving enterprises both time and expense.Because these systems are explicitly coded by humans, they’re easy to understand, audit, and iterate—as long as the problem they’re solving is simple enough. The business process causes and conditions must be well understood, and the consequences must be relatively deterministic.When the problem at hand isn’t straightforward or well understood, rule-based systems can’t cope. Their biggest challenge is that they’re overly brittle, meaning they can only make decisions when they have explicit instructions to do so. If faced with complex processes that have layers of dependencies that aren’t fully understood, they’ll break down. As an example, diabetes has three labels (Diabetes, Type I, Type II), but the choice of labels depends on nuanced dependencies of the features (BMI, glucose, insulin, etc.) about which we are learning more every year. Rule-based that are intended to capture complexity can become prohibitive to develop, update, and maintain.
Machine learning models
This need to model complex problems led to the growth of deep learning models that are incredibly good at learning complicated layers of dependencies.This power comes at a cost. Modern deep learning models are extremely data-hungry, requiring vast amounts of training data to learn from. With the increasing commoditization of model-architectures and of compute (with cloud services), creating these training sets has quickly become the largest bottleneck to AI development as enterprises have to manually label each data point one-by-one.This has resulted in an ever-growing need for expensive data labeling services and tools to amass enough data to train these models. Some companies can outsource their data labeling to vendors who will crowd-source labels, but many enterprises don’t have this option due to data complexity and/or privacy constraints. They are limited to building or investing in tooling to help make their internal labelers more efficient.While these solutions will provide some relief in terms of the time required to label, they’re extremely costly and still require weeks to months to complete. This investment may be acceptable if the nature of the problem is relatively static and the data only needs to be labeled once or semi-regularly, but that’s rarely the case.Most real-world processes don’t live in isolation, but rather operate against complex and ever-changing realities. These changes are driven both externally (new patterns in production input data) as well as internally (new label schemas or business goals impacting output data). Either way, labeling new training data and relabeling existing training data becomes a significant cost of maintaining the application’s value.

| Input data is ever changing. As sociological factors (people behavior) and operational realities (products, technologies, improved knowledge) evolve, the inputs of an AI application are ever-changing. For example: • Adversarial agents in fraud are constantly evolving new ways of evading detection in response to the rules of the day, necessitating the need to evolve the rules. • Changing epidemiologic factors necessitate the labeling and relabeling of real-world evidence (RWE) data to ensure pharma, providers, and payers are responsive in delivering the right care to the patients in need. Output data is ever changing. In response to the changing inputs, businesses and governments are constantly evolving their objectives, necessitating the output metrics of processes to adapt as well. For example: • COVID-19 necessitated businesses to move operations online, requiring conversational AI applications supporting banking institutions to rapidly expand to an entirely new set of requests and intents. • A retailer adds a new product category, necessitating the relabeling of data and retraining of search-relevance models, so customers are able to find the right products. |
| Case study: Fortune 500 online bank To keep up with rapidly changing customer intent and sentiment, a leading online bank needed to find a scalable way to train and retrain conversational AI models to adapt to a dynamic and large set of intents (goal a customer has when initiating a question) on account of changing customer behavior and bank offerings. Their existing model development workflow did not allow them to iterate quickly enough on their intent classification models for their chatbot. Their bottleneck was hand labeling — it would have taken them 21 days to label their training set. Their chatbot’s accuracy suffered and left customer service inquiries unresolved. As a result, their customers used different support channels and reported low satisfaction with their chatbot. |
Given the cost to label (and relabel) training data, enterprises often don’t see a return on their AI investments. Either they never get to production in the first place, or they ship an AI application that posts excellent results on day one in production but is extremely fragile to the realities of changing input data and evolving business objectives and quickly becomes obsolete.
Enterprise AI applications with data-centric AI
The dynamic and complex nature of enterprises necessitates AI applications that accommodate both the complexity of models and the accessibility of heuristics, while still being cost and time efficient for the enterprise.Data-centric AI application development encompasses a set of capabilities that make it possible to deliver on these requirements,
- Programmatic labeling which involves writing understandable heuristics, or labeling functions, to intelligently capture human rationale and other sources of signal in an efficient and scalable way.
- Model-guided iterative development which involves multiple and frequent iterations of the labeling functions and model training to account for complexities of the problem.
- Monitoring and adaptability of the developed AI application with guided, efficient response to changes as they’re observed and monitored.
The result is a development process that allows humans to engage on the inputs that require expertise and iteration (labeling functions and model iterations), in order to enable programmatic labeling to scale training dataset creation at computer speed. The net impact of this accelerated and efficient development process is an AI application that can manage complexity, is adaptable, and more resilient.
Through years of research on data-centric AI at Stanford AI Lab and in production at leading organizations, the Snorkel AI team developed Snorkel Flow, our end-to-end data-centric AI platform that encompasses multiple capabilities and workspaces to develop and productionalize AI applications.
These include:
- Integrations with an ever-expanding set of enterprise resources to seamlessly use the most timely and relevant data to develop AI applications.
- Programmatic labeling to collaboratively develop human-understandable heuristics (labeling functions) used to intelligently auto-label vast amounts of data and to maintain the labeled data in response to continuously changing input data and output objectives.
- Analysis studio to train, analyze, and iterate on the models with actionable guidance.
- Application studio to turn models into applications and easily package them to serve and integrate into the enterprise’s operational stack.
- Monitoring to monitor and explain model performance that provide actionable insights into keeping the training data and model relevant.
| Case study: Fortune 500 online bank Over the course of a week, the same bank built a high cardinality utterance classifier with Snorkel Flow. They trained the classifier over 30,000 programmatically labeled conversations. The team at this Fortune 500 bank were able to unlock: Faster iteration: It took under 8 hours for the team to achieve >80 F1 macro on their model. Increased resilience: Adding new intents and re-labeling their data took hours, not days. Meaningful collaboration: SMEs and data scientists could collaborate in one unified platform to build better models. Seamless integration: The team was able to quickly integrate the model they built in Snorkel Flow with Rasa. |
Enterprises not only use Snorkel Flow to build AI applications, but also to keep their applications relevant and value-creative over time. You can read more about some of the outcomes we’ve enabled in our case studies.To learn more about Snorkel Flow and how it can take your enterprise AI development to the next level, request a demo or visit our platform. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, or Youtube.

Arjun Prakash