
Enabling iterative development workflows with Snorkel Flow’s Application Studio
Consider this scenario— we’re AI engineers, and we’re building a social media monitoring application to track the sentiment of Fortune 500 company mentions in the news. Following the advice we saw on Twitter this morning, we start with an end-to-end multi-billion parameter language model to extract mentions of companies and classify each one as positive, neutral, or negative.After training our model, we’re disappointed to find that our end-to-end score is much lower than expected. What should we do from here? (Twitter didn’t prepare us for this…) To fix the errors our model is making, we need to understand where the errors are coming from. Are they due to missing company mentions? Confusing companies with similar names? Misclassifying the sentiments? If we do identify the kinds of errors our model is making, is there any way to use that information to improve our monolithic model in specific ways? And if we have other related resources (e.g. our teammate scraped a list of Fortune 500 company aliases for a separate project), how should we integrate those?Watch this video for a full deep dive into Application Studio by Founding Engineer and MLE Lead, Vincent Sunn Chen:
Through years of supporting complex AI/ML application deployments at Snorkel AI, we’ve seen customers face these (and many other) challenges firsthand, and we’re not alone:
We build AI/ML applications with the following principles in mind:
- Down with the end-to-end mega model!: While some problems can be solved with a single, end-to-end model that goes from raw inputs to end outputs, our customers often find that these approaches don’t replace the engineering advantages of a modular, composable pipeline of individual building blocks— including custom models, preprocessing steps, and business logic. Like any other piece of production infrastructure or code, it’s critical for practitioners to inspect, test, modify, and swap the modular components in an end-to-end system.
- Long live end-to-end (evaluation and iteration): At the same time, while modularity is key to the development process, end-to-end evaluation and iteration over the full application is just as important. A global application view (beyond individual models or preprocessing steps) should be a first-class citizen to support a practitioner’s development workflow.
- ML should not be the universal default: Once we break down a complex task into its modular components, an equally important principle is to avoid assuming every component is a deep learning model–no matter what Twitter tells us! The key is to start with sensible defaults—often heuristics—and then swap in learned (ML) components based on empirical and iterative error analysis.
- Adaptability through programmatic labeling: Real-world applications are built over custom data distributions and problem definitions, where we can’t rely solely on models that were pre-trained on in different datasets or problem settings. While pre-trained model components will often play a key role, we need a way to flexibly develop and adapt our models— as with Snorkel’s programmatic labeling approach.

To help practitioners apply these principles, we introduced Application Studio, a new interface for AI/ML practitioners to iteratively develop end-to-end AI applications. In the next sections of this post, we’ll share the key concepts behind Application Studio and walk through how they can help us build the social media monitoring application alluded to earlier.
Key Concepts
In Snorkel Flow, users build and deploy end-to-end AI applications to address specific product or business needs. Under the hood, applications are implemented as directed-acyclic graphs (DAGs) over atomic building blocks, called operators. Each operator is a function that performs a transformation over one or more dataframes. For example, a data cleaning operator can remove all extraneous whitespace from a text column, and a classification operator adds a predictions column with the model’s prediction for each row in the dataframe. In Application Studio, users can compose arbitrary operators by manipulating the DAG (adding or deleting nodes) in the visual builder. As long as the type signature matches (e.g. documents in, per-document predictions out), an operator is modular — it’s very straightforward to replace an operator with a different version. For instance, a classification operator might take in a dataframe where each row represents an email with columns subject and body, and append a predictions column — this can be implemented using rules or a learned model. We can easily build and experiment with different operators, taking advantage of the data exploration, labeling, and model development interfaces in Snorkel Flow.

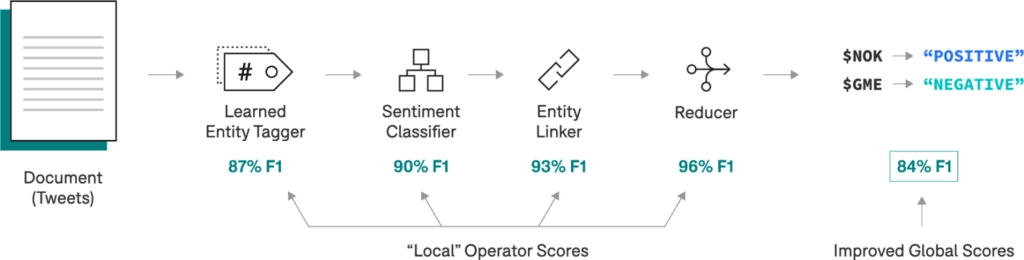
In addition to providing flexible interfaces for building applications from operators, Application Studio enables fine-grained introspection into each operator’s outputs and associated metrics. We can view “local” scores associated with each operator in addition to “global” scores corresponding to the application. This way, it’s very straightforward to diagnose and quickly prioritize where we should spend time making improvements.To help us move even faster, Snorkel Flow provides application templates, which specify operators and recommended resources, including domain-specific labeling functions, models, and visualization tools. Whether it’s sentiment analysis over news articles, or information extraction from PDF documents, each template provides scaffolding based on best-practice approaches and the flexibility to customize any subcomponent.Building a Social Media Monitoring Application
As a running example, we’ll walk through the process of building and improving an AI application for social media monitoring. Recall that our goal is to perform sentiment analysis for Fortune 500 companies mentioned in a stream of Tweets.

In Application Studio, we have the flexibility to build applications based on custom compositions of operators—in this case, to help us hit the ground running, we’ll take advantage of a “Social Media Monitoring” template:
- Entity Tagger: Identifies “spans” (defined by character offsets) for every company mentioned in the Tweet.
- Classifier: Classifies the sentiment for a specific span of text 1.
- Entity Linker: Links all company mentions to a canonical form (e.g., company stock ticker symbols).
- Entity-level Reducer: For each document, groups span-level predictions by canonical entity to infer an entity-level prediction (e.g., the overall sentiment per company).
We note that this operator DAG provides one way—not the way—to formulate the problem (based on a specific customer configuration). Different approaches are possible with Application Studio, and it’s easy to swap between them based on an empirical error analysis!
Entity Tagger
Let’s consider the entity tagger in the context of our original requirements.
Perform sentiment analysis for any Fortune 500 companies mentioned in a stream of Tweets.We only need to pull out Fortune 500 companies and not all companies, and as it turns out, our teammate had collected an internal dictionary mapping each company to a list of known aliases for a separate project. As a result, we can start simple— we’ll perform a fuzzy lookup against the aliases to tag company mentions in our text. Down the road, we’re flexible to replace this heuristic with a different approach, like a state-of-the-art NER model custom trained on programmatic supervision in Snorkel Flow—and because our application is modular by design, we don’t need to worry about the overhead of re-architecting our system!

Classifier
We’ve now tagged Fortune 500 companies in each of our Tweets, and we’d like to classify the sentiment of each company. We’ll start with a simple baseline that’s fast to run and easy to interpret—we can swap in a more complex model later if necessary. To develop this model, we double-click into this node in the operator DAG, which takes us to the model development interface in Snorkel Flow. Here, we write labeling functions to bootstrap a training dataset and select a simple logistic regression from the Snorkel Model Zoo to classify each mention based on simple bag-of-words features.
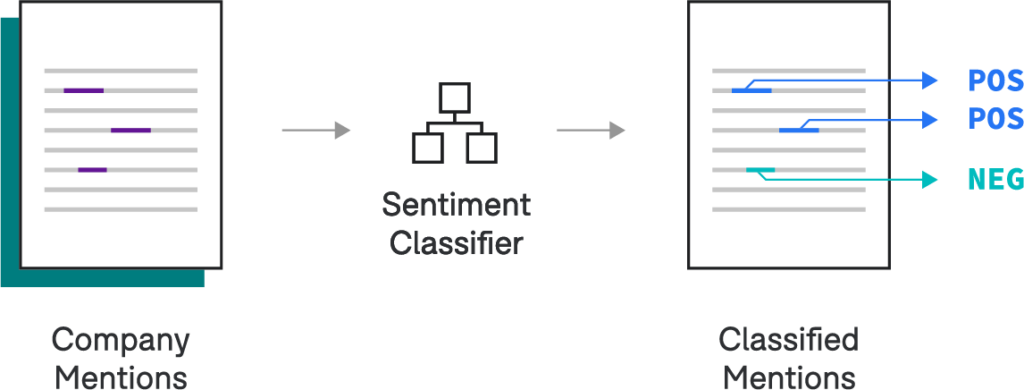
Entity Linker
We now have the classified sentiments of all companies mentions within each Tweet. However, rather than a prediction per mention, what we really want is a prediction per entity, or unique company.Consider this example:Had a horrible experience at Gringotts this morning… I don’t recommend Gringotts Wizarding Bank to anyone!Gringotts and Gringotts Wizarding Bank have different underlying spans, but they are referring to the same entity. In order to make our system robust to different text strings, we’d like to link both mentions of Gringotts to a canonical ID: the (fictional) stock ticker symbol $GRING. Given we’re still operating over Fortune 500 companies, we can leverage another practical solution: let’s create a lookup table mapping each company in our existing alias dictionary to its stock ticker symbol. Then, if based on error analysis, we see that this is one of the dominant sources of downstream errors, we can replace it with a state-of-the-art, neural entity linking model trained in Snorkel Flow!
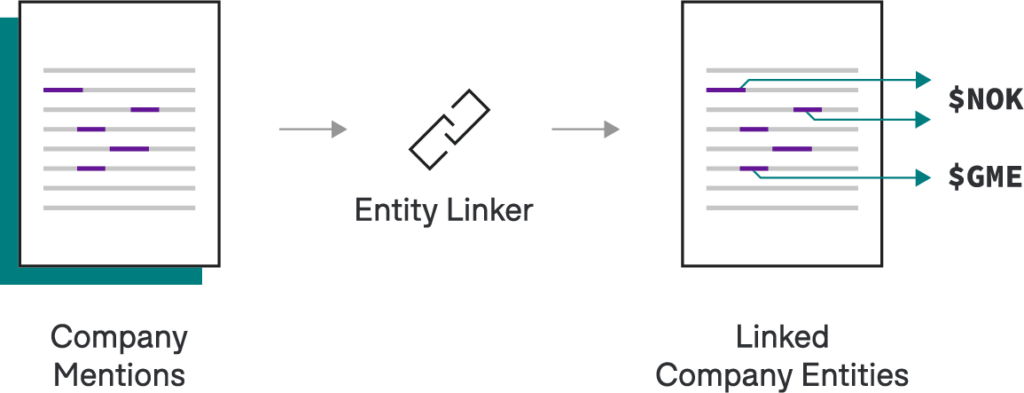
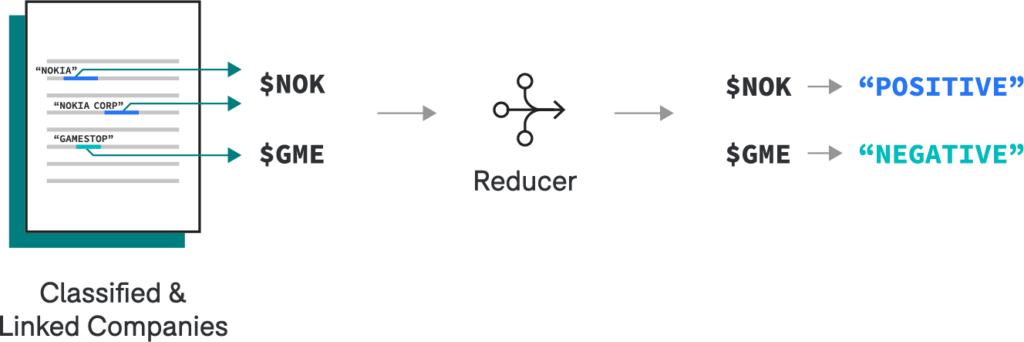
Entity-Level Reducer
Once we’ve linked all company mentions to their stock ticker symbols, we can use a reducer to heuristically infer predictions at the entity-level. In other words, for each Tweet, we want one sentiment per company, even if that company was mentioned more than once. In this case, we’ll apply simple business logic to take the most common mention-level prediction as the entity-level prediction.
Introspecting Operator Metrics
If we had trained one monolithic model with 74% F1 at this point, what would we do next? Would we have any idea what the actual problem was? Contrast this with the view in Application Studio: we’ve broken our application into several simpler components, and now, we can inspect component-wise metrics to prioritize the next steps empirically.
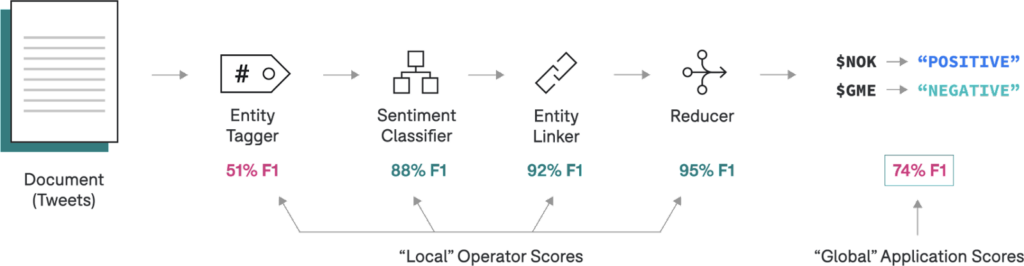
It looks like the extractor is underperforming. We can improve this by replacing the heuristic extractor with a sequence-model-based extractor that we supervise and train using programmatic labeling workflows in Snorkel Flow.After building and committing the improved model, Application Studio will notify us to refresh the “stale” downstream operators. On refresh, we see new and improved end-to-end scores for our application based on improvements from our upstream entity tagger!
Takeaways
We’ve seen an end-to-end development loop for our social media monitoring application. Let’s recap what we just saw and how this relates to the key design principles we discussed earlier.
- By decomposing a relatively complex application into simpler subcomponents, we were able to easily take advantage of existing resources and map more closely to the product requirements.
- When we saw that the performance was insufficient, it was very easy to replace a heuristic operator for a more complex “learned” counterpart.
- By looking at the operator-level metrics, we quickly prioritized which step in the pipeline required improvements.
Practitioners need new workflows that support component-wise evaluation, rapidly adaptable components, fine-grained debuggability, and the flexibility to combine learned models with business logic. To address these needs, Application Studio introduces a new, iterative approach to building end-to-end applications. We’re excited for you to try it. Request a demo of Snorkel Flow.If you’re interested in staying in touch with Snorkel AI, follow us on Twitter, LinkedIn, Facebook, Youtube, or Instagram.And if you’re interested in joining the Snorkel team, we’re hiring! Apply on our careers page.
1 Note that steps (1) Entity Tagger and (2) Classifier can be seen as a decomposed NER task.

Vincent Sunn Chen
Research Fellow & Founding Team
Vincent Sunn Chen is a Research Fellow on the founding team at Snorkel AI. His work centers on systems for high quality AI evaluation & data development with experts in the loop. He currently leads the Open Benchmarks Grants, a $3M commitment to funding benchmarks and infrastructure for frontier agents. Prior to Snorkel, Vincent was a researcher at the Stanford AI Lab, where he studied the foundations of data-centric AI systems.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

