
The Future of Data-Centric AI Talk Series
Background
Roshni Malani received her PhD in Software Engineering from the University of California, San Diego, and has previously worked on Siri at Apple and as a founding engineer for Google Photos. She gave a presentation at the Future of Data-Centric AI virtual conference in September 2021. Her presentation is below, lightly edited for reading clarity. If you would like to watch the full video of Roshni’s talk, we have included it below, or you can find it on YouTube.
At the Future of Data-Centric AI 2021 event, we have seen good evidence that the shift to a focus on data leads to better-performing AI systems that are also more robust and scalable. We have seen lots of evidence that improving your data also improves your model. I want to emphasize, though, that because it is subject-matter experts (SMEs) who know your data best, one of our primary goals as AI application developers should be to empower SMEs with multiple ways of sharing their expertise—not just with the label itself, but also the context and nuance behind that label. This collaboration between SMEs and data scientists accelerates AI development.
“Collaboration is one of the fundamental pillars of data-centric AI.”
Collaboration is one of the fundamental pillars of data-centric AI. It is teams that build AI applications, as we all know, and that necessarily includes SMEs with deep domain knowledge along with data scientists and machine-learning engineers. All team members work together to define the “what” and the “how” of a given application. AI applications can be developed most efficiently by collecting as much signal as possible from every member of a team. If AI is to become more dynamic and useful, it can best be done when every member of a team feels empowered to collaborate on the same platform.

You can also hand-label data points inside your training set to help you guide model development and to handle the “long tail” of data that does not generalize easily.
Blocked on data in a data-centric world
AI teams are regularly blocked on data in an increasingly data-centric world. We frequently work with customers who cannot crowdsource their data, because it must be kept in-house. Managing and labeling data requires a high degree of expertise. The data we use might have privacy concerns or other ethical restrictions tied to it, for example, medical data or financial records. And collecting and labeling data are often painfully slow and expensive. Further, once data scientists have their data, without close collaboration with SMEs, they often miss out on the context and nuance behind their labels. Such nuance is difficult or impossible to convey with simplistic labels alone, nor can it be readily understood how much confidence a given labeler had in the label applied to a given data point. This context would be hugely beneficial for scientists to have. Even our tools for collaboration are generally woefully inadequate. SME labelers, for example, are often busy copy-pasting things between cells on an Excel spreadsheet. Iterations and snapshots of such spreadsheets get emailed back and forth, and sometimes data or entire iterations get mixed up or misplaced.But we can unblock data by maximizing input from all team members on the same platform. How can data scientists, machine-learning engineers, and SMEs all best work together to deploy their respective expertise most effectively? Domain experts’ time should be maximized and efficient, not spent on hours and hours of tedious hand-labeling. We must use higher-value, more accurate labels that are able to convey more context and nuance about the data. We also need labeling to be accomplished at much higher velocities using interfaces that have less friction than emailed versions of spreadsheets can provide. So, as we as a field shift our focus from iterating on the model or code to iterating on the data, we must bring the power of modern collaboration tooling along with us.
A typical model iteration: limited collaboration
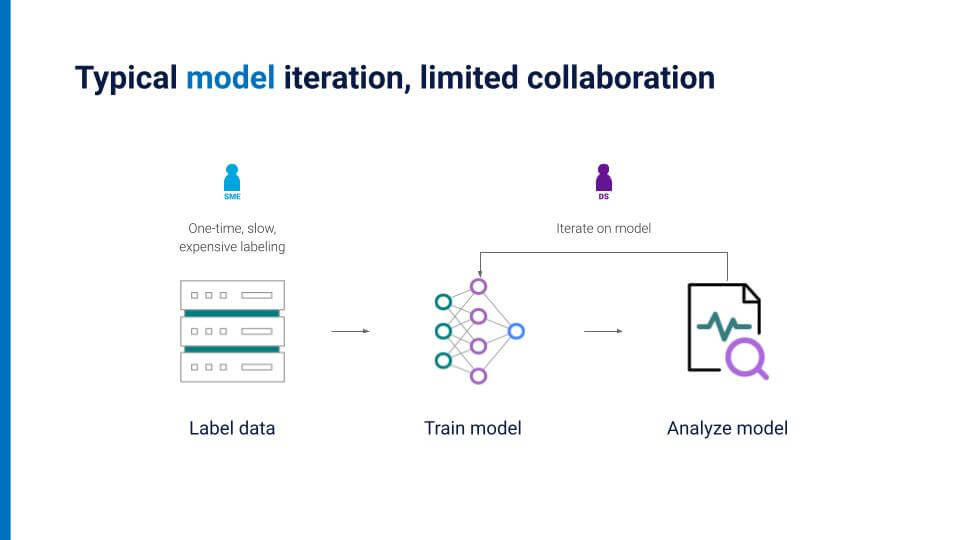
Traditionally, data scientists and SMEs often remain stuck in silos, with no common means or tools for them to collaborate in real-time. Because hand-labeling is a time-intensive and tedious process, SMEs usually do it only once. Manually labeling an entire dataset multiple times is incredibly onerous, and so hand-labeling in this way constrains data scientists to iterating only on the model, which results in increasingly marginal improvements over time. To illustrate the point simplistically, imagine each dot on the slide below represents a data point, split into a “training” set and a “validation” set.

The validation set here is hand-labeled, but the training set would also need to be painstakingly, one by one, hand-labeled as well.


No one wants to label all those data points a second time. It’s slow, expensive, and, least helpful of all, static. But in a data-centric AI world, we can use programmatic labeling and efficient collaboration between scientists and SMEs to create another iteration loop focused primarily on the data.
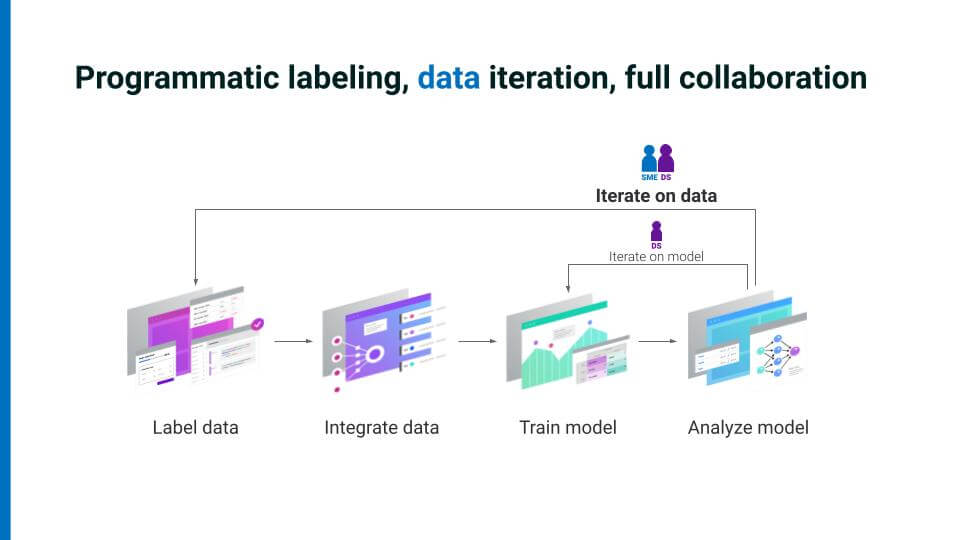
Snorkel AI introduced a new way to capture expertise by using programmatic labeling and demonstrated that it accelerates AI development. Snorkel Flow is based on weak-supervision techniques that Snorkel AI’s founders pioneered during their time at the Stanford University AI Lab. And it offers an iterative loop that maximizes collaboration.The core collaborative loop operates as follows:
- After labeling some data and training a model, users analyze the model’s performance deficits. They look for the gaps that allow you to create more targeted and relevant labeling assignments, especially for corrective/iterative work. This approach enables users to work on the data efficiently in smaller sections rather than the entire (unwieldy) set. In other words, you specifically work on places where the model is most wrong, or on particular high-value examples, or on commonly confused classes of data—it is an active learning approach that puts a human SME in the loop.
- Next, users iterate on these gaps collaboratively, gathering all the information you can to label even more data with which you can again feed into the model for analysis.
- Users repeat this same iterative loop even after deploying a model and monitoring a slice of production data.
- As a result of this fundamentally collaborative loop, focused on the data, the improvements in an AI application are often orders-of-magnitude greater than what can be accomplished with model-centric AI and hand-labeled data.
What is programmatic labeling?
Let’s try to demonstrate what programmatic labeling looks like in basic terms, using a similar dot-matrix illustration I used earlier.
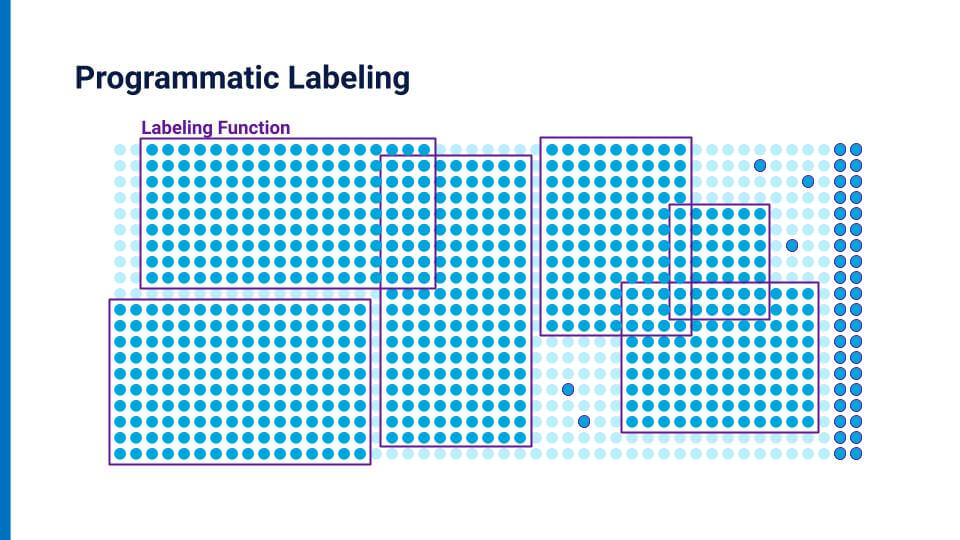
Here, SMEs work with data scientists to encode their domain expertise as labeling functions (LFs). They incorporate rules, heuristics, dictionaries, and all other available sources of information to help inform what the label for a given data point can be.Snorkel Flow does not require any ground truth. You can train your model based solely on these programmatic labels. It also allows you to add in a small amount of hand-labeled data, offering a hybrid approach. You can use as much or as little (or none) hand-labeled data as you want to grow confidence in your labeled dataset. You can also hand-label data points inside your training set to help you guide model development and to handle the “long tail” of data that does not generalize easily.Snorkel Flow automatically weights and de-noises these labels—both those generated programmatically and those that are hand-labeled—to create a higher quality training set at scale. The main idea here is to use as much signal as possible in any form factor that you have available. While the current standard and most obvious way of getting SME input is ground truth labels for training and evaluation, programmatic labels provide another opportunity to get SME input. They allow you to iterate faster and provide more insight into how to improve our end-model performance.
How does programmatic labeling enable collaboration?
Snorkel Flow provides multiple ways to capture domain expertise from within the same platform, thus unlocking data collaboration by maximizing the value and velocity of SME input. Comments provide free-form context about a data point—the “why” of a given label. Tags highlight properties about your data points, clustering them in ways that might provide insight into your machine-learning problem. Labels can be used as ground truth. You can also write low-code templates to capture patterns within the data for labeling. You can use code to encode heuristics and domain knowledge into the data as well. Using a diversity of input methods empowers SMEs to share a maximum of information about the data with data scientists, inherently multiplying their value.“Using a diversity of input methods empowers SMEs to share a maximum of information about the data with data scientists, inherently multiplying their value.”You can also maximize SME collaboration by creating a more integrated platform that reduces interface friction between SMEs and data scientists and allows for faster iteration—increasing velocity. That platform should provide every member of the team with full context, so everyone sees a consistent view of their data points. No more passing around snapshots of spreadsheets. It should include easy-share links that allow team members to request annotation quickly. It should also feature real-time labeling progress updates and version control.To show how Snorkel Flow empowers AI teams to collaborate both synchronously and asynchronously to get labels with greater value at higher velocity, let’s examine a case study.
Data-centric AI development case study

Let’s imagine we operate SnorkBank, a fictional bank that provides loans to small-to-medium-size businesses. This fictitious example demonstrates the quality and speed with which you can adapt to changing business requirements, such as: Label understanding evolving over time, label schema shifts, and data drift.SnorkBank has skilled loan officers who evaluate business loans in thousands of different industries. As you might imagine, a loan application from a boutique cupcake store is going to be quite different from one from an automobile manufacturer. The goal, then, is to build an AI application to route new loan applications to the appropriate loan officer who specializes in a particular industry.

We start with a database of about 500,000 unlabeled loan applications, and we have about 1,000 different classes. First, data scientists and SMEs can sit down together to capture expertise as heuristics. The first idea for an LF might be that if the exact text of a label is in the loan application, then likely that is the label. We could also use some keywords from a dictionary or generic ontology to help us with programmatic labeling. Or, perhaps we might use some auto-suggested labeling functions. Doing this, we generate 300,000 programmatic labels for training. How do we evaluate whether any of these heuristics are any good?
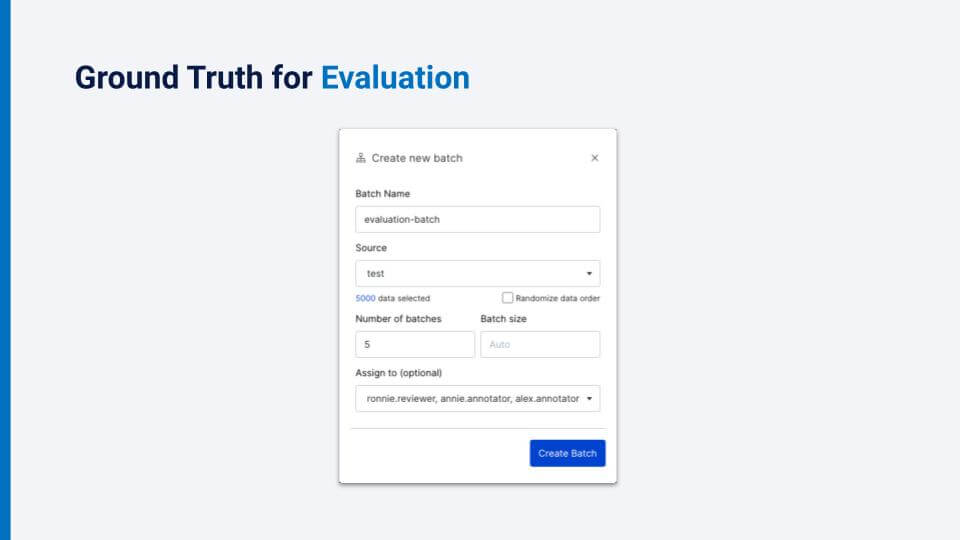
Luckily, we have already started the process of collecting some hand-labeled ground truth for evaluation. Notice that we are creating a batch that has only about 5,000 data points. This is only a tiny sample of the 500,000 data points that we have, but that is all we will need for evaluation.We want the highest quality labels that we can get for our data set, so we have asked several loan officers (SMEs) to label the same batch of data points. Now, instead of pinging for progress updates and being unable to see partial results, our senior loan officers can make sure that our junior officers, who are labeling independently within the platform, are on the right track.
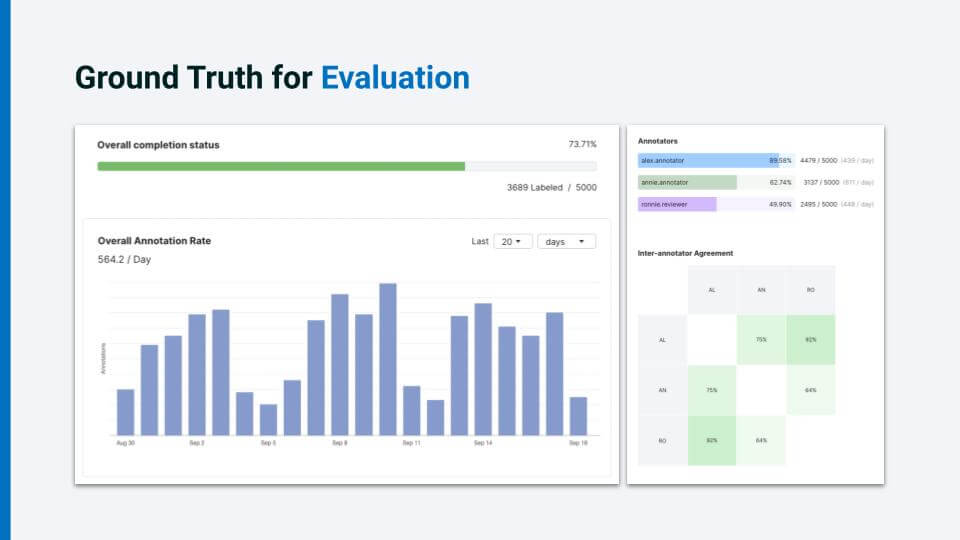
We can see overall information, such as the total completion rate and the annotation rate. And we can see individual information such as individual annotator completion status as well as inter-annotator agreements, optionally broken down by class. Further, we can denote the senior loan officer (“Annie” in this example) as an expert, and see her agreement rate with the junior officers.
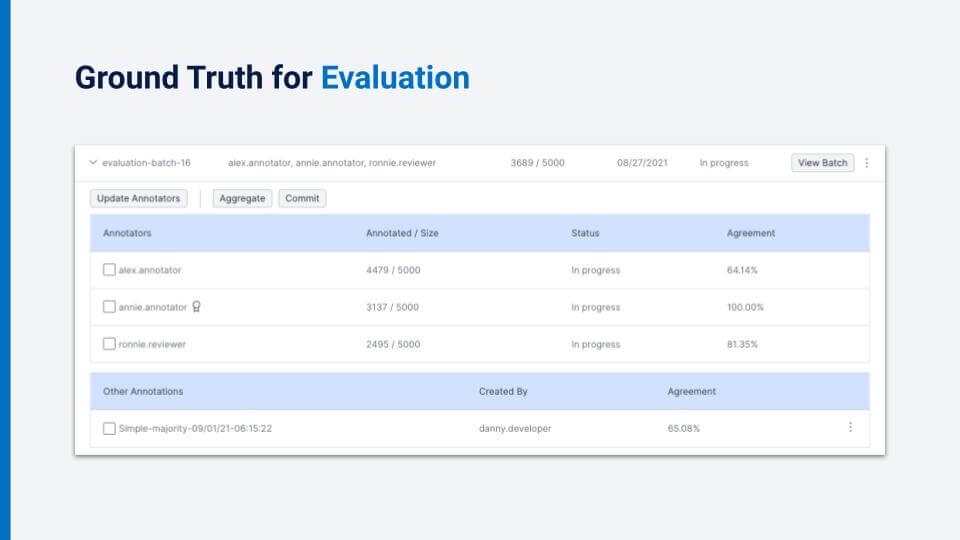
We can choose which annotators to aggregate before committing the label to ground truth. Now that we have seen the basic tools for creating batches for annotation that can be analyzed, aggregated, and committed as ground truth, we can walk through three scenarios that demonstrate the dynamic, messy environment for which long-lived AI applications tend to be developed—where the iterative loop of improving model performance requires collaboration between SMEs and data scientists in the same platform.As you will repeatedly see, collaborating on the data will increase the value of the data while also creating labels at higher velocity.

Scenario 1:
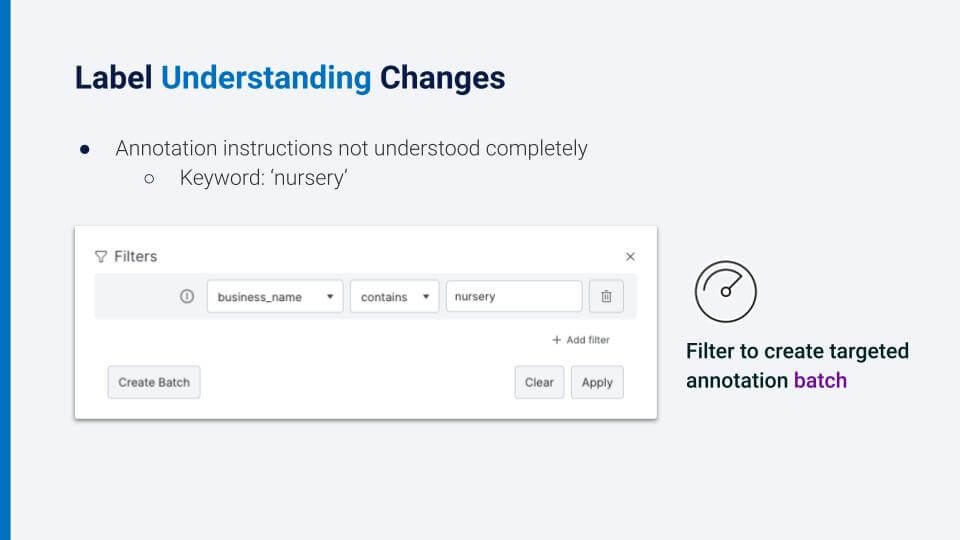
Let us assume the data scientists have trained a model, looked at the analysis, and are now digging into the analysis of each class in particular. It turns out that the annotation instructions either were not clear, or were interpreted differently. So, for example, the keyword “nursery” could be interpreted as a garden supply business or as a childcare center. What we want to do is filter data points about “nursery” and click to create a batch for annotation. After we create this batch, we can work together with the SMEs and the data scientists to refine the existing label functions, create new ones, and validate the model after we train it with the new hand labels. It’s essential to ensure that annotation guidelines are clear and aligned with both the data scientists and SMEs to avoid ambiguity in the future.
Scenario 2:
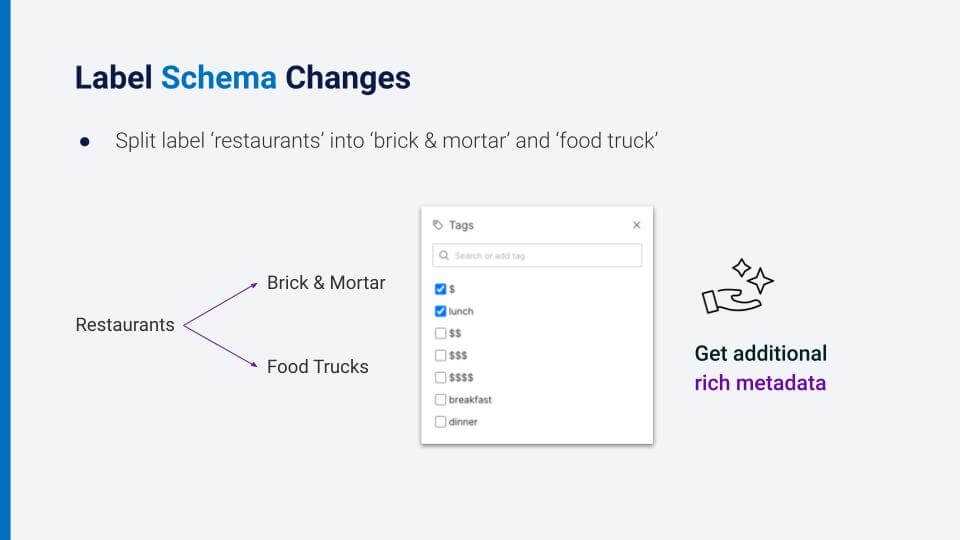
Another common problem is that the label schema changes. This includes anything from adding labels, removing labels, splitting a label into multiple labels, or combining multiple labels into one.For example, here we have split the label “restaurants” into two labels: “brick and mortar” and “food trucks.” Again, we repeat the process of incorporating SME expertise. We can either refine or add new label functions, or we can request targeted hand-labeled data to add to our ground truth for validation.Here you can see we request targeted hand-labeled data for our ground truth, and we can actually request additional tags or properties about the data that we think can inform our label functions, for example, “price” or “popular meal times.” This gives us additional rich metadata about businesses that inform our label functions.
Scenario 3:
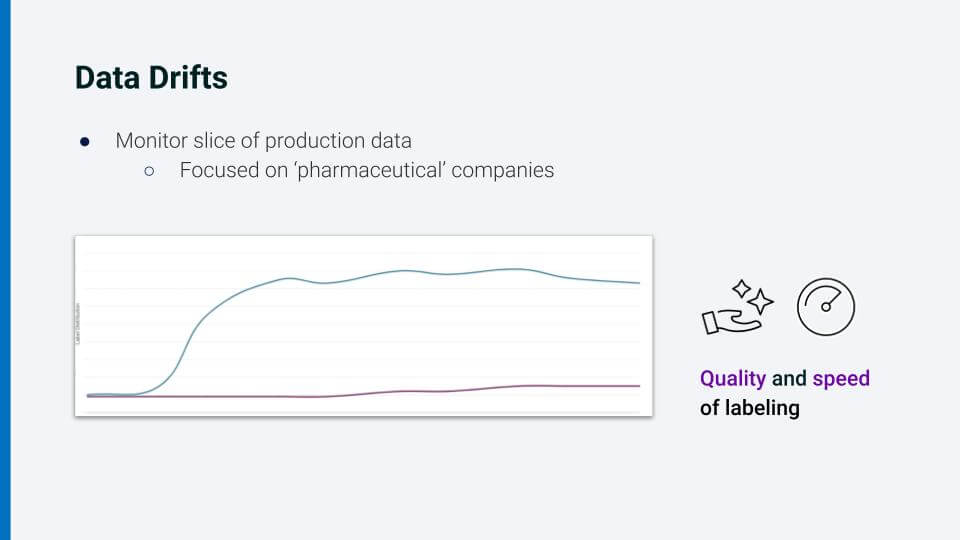
Data drift is a common problem. Let us say we have developed our model, and identified a particular slice of production data that we want to monitor—say the focus is “pharmaceutical companies.” We notice a drift in label distribution for this particular class. It turns out that lately there have been more loans for businesses involved in the vaccine manufacturing industry as well as industries involved with associated transportation infrastructure. Not only were we able to identify this trend quickly from within the Snorkel Flow platform, but we were also able to address it quickly. As a result of being embedded in the same platform as the data scientists, our SMEs have gone through the collaborative iterative loop many times by now, and are able to identify patterns in the data and encode them using low-code interfaces. Thus, you can see that the quality and speed of data labeling increases over time as you iterate on your AI application collaboratively.
Summary
“The agility needed to adapt your machine-learning model comes when subject-matter experts can encapsulate and encode their respective expertise in multiple ways that are integrated and seamless.”
With data-centric AI, machine-learning applications require iterative improvements, not just on the model, as we all know, but also on the data itself. AI applications are also built by teams—SMEs and data scientists and engineers working together. The best way to accelerate AI improvements and make applications dynamic, then, is to equip team members with more efficient ways to collaborate. Snorkel Flow is designed to create a central hub for all of the rich artifacts that are created during the process of building an AI application. Doing so empowers users to follow industry best practices that can be supported with best-in-class collaboration tools. The agility needed to adapt your machine-learning model comes when subject-matter experts can encapsulate and encode their respective expertise in multiple ways that are integrated and seamless. That is, collaborating in the same platform maximizes the value and the velocity of data-driven AI applications.
Q&A
At the conclusion of Roshni’s presentation, there was time for a brief question-and-answer period. It is summarized below.
Q: How would you integrate with external data sources to bring in external data for risk assessment during the underwriting stage of the loan approval process?
A: That’s a great question. As I said, the goal is to really maximize the possibilities and inputs we can get. So, bringing in any external data is absolutely critical and valuable. If that external data is already outsourced labels, you can bring those in. If it’s an existing model or a dictionary that informs part of your model, you can bring it in. And, of course, anything that helps with risk assessment, all of that can be incorporated into the Snorkel Flow platform.
Q: How does Snorkel Flow incorporate techniques like Active Learning?
A: Active learning is all about incorporating humans into the loop—empowering SMEs to help at any point in the cycle and to look at any slice of the data and provide as much input as possible. Whether that’s through label functions or labels or, if they don’t feel comfortable doing that directly, even providing comments that provide the context behind the data. SnorkelFlow also guides users to examine data points with low model confidence.
Q. How much hand-labeled data might you need for programmatic labeling/Snorkel approach?
A. Snorkel Flow is based on the Snorkel research project, in which we’ve proven that you don’t actually need any hand-labeled data at all. You can label your data, train your model, and it will work well in the real world. But if you want an extra level of confidence, you can also have as much hand-labeling as you want to confirm your model is performing well. We do recommend some hand-labeling in practice to really up that confidence in the model and to target any specific difficult-to-label data, and really focus on those kinds of examples.
Q. With regard to data drift and domain shift, which some other speakers have mentioned as well. Can you talk a little more about how that ties into Snorkel Flow and what Snorkel AI is working on?
A. Yes, data drift is a real problem for people in real-world applications, and Snorkel is committed to helping people through it. If you deploy your application through Snorkel Flow then we can monitor your production models. I can grab slices of data that you might care more specifically about. The example I used was pharmaceutical companies, and there is so much data that it can be helpful to really narrow down areas you want to focus on. And Snorkel Flow’s continuous iterative loop enables you to collaborate on production data. You can flip through and dig through your data at any point in the process.If you’d like to watch Roshni’s full presentation you can find it on the Snorkel AI Youtube channel. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, Facebook, or Instagram.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

