
While a majority of Natural Language Processing (NLP) models focus on English, the real world requires solutions that work with languages across the globe.
A U.S. business may create a model for classifying customer support tickets in English, but then need French and German versions of that model when they open affiliates in Europe. Labeling data from scratch for every new language would not scale, even if the final architecture remained the same. Performant machine learning systems need to support this demand.

While Snorkel Flow offers the ability to iterate and adapt to changes in business requirements or datasets, we tested and confirmed that this extends to expanding models to different languages. In this article, we discuss key Snorkel Flow features and capabilities that help data science and machine learning teams to adapt NLP models to non-English languages. We dive into two specific examples: a Chinese entity extraction problem and a broader multilingual tweet dataset to see how Snorkel Flow is used to develop high-quality NLP applications.
Challenges in adapting NLP models to non-English languages
There are several challenges that can arise when adapting natural language processing (NLP) models to non-English languages. Here are three common challenges:
- Lack of resources: It can be difficult to find large, high-quality datasets in non-English languages, which is often necessary for training effective NLP models. Additionally, there may be fewer pre-trained models or language-specific resources available for use.
- Language complexity: Some languages, such as Chinese and Arabic, have complex characters and scripts that can make them more difficult to process using NLP algorithms.
- Cultural differences: NLP models are heavily influenced by the language and culture of the people who use them. As a result, it can be challenging to adapt models developed for one language and culture to work effectively in another language and culture. This may require extensive customization and fine-tuning of the model.
NLP’s Resilience
Human languages differ from each other in many ways, including their alphabets, grammatical structure, and syntax. For text classification, however, there are many similarities. Machine learning models trained on labeled datasets generally learn from features in the available data to predict specific classes. These features are words, word-parts, or groups of words. Any group of contiguous Unicode characters may be considered a useful feature.
There are exceptions to this!
A linguist would rightfully point out that Chinese does not use whitespace tokenization, and that Turkish, Finish, and other languages can combine a whole sentence’s worth of morphemes into a single word. We won’t ignore those and will revisit these exceptions later on.
Snorkel Flow capabilities supporting multi-lingual NLP
The Snorkel Flow data-centric development loop, centered on programmatic labeling, rapid model and training data iteration, and performance analysis, applies across any language with minor adjustments.
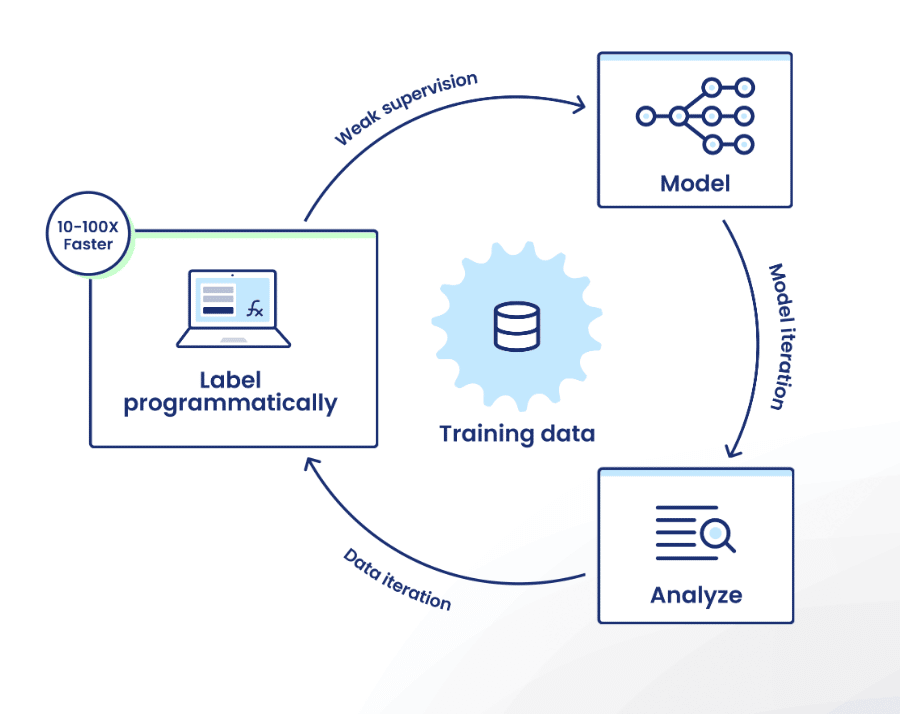
Programmatic Labeling
Programmatic labeling is a method for generating data labels in an automated or semi-automated manner. Users create a collection of labeling functions (LFs), which are rules for labeling collections of data points. Snorkel Flow then uses weak supervision to combine the rules and label enough of the to train a model.
The primary LFs for text-based data find character sequences using regex and work out-of-the-box across languages.
Snorkel Flow’s “Auto-Suggest Key Terms” feature works on any language with “white-space” tokenization. The following image shows an auto-suggestion from a Spanish Sentiment dataset (“mucha suerte” translates to “good luck”).

While users can accomplish a lot with regex functions, Snorkel AI recently announced new capabilities around Foundation Models and large language models. While GPT-3 trained primarily on English data, experiments found that it can be adapted quickly to other languages. Furthermore, Hugging Face hosts language-specific models that can be used in a similar capacity—including bert-base-multilingual, which was trained on over 100 different languages.
After users create these LFs, Snorkel Flow applies Label Models (weak supervision algorithms) on the class labels without taking the text directly into account.
Modeling
Snorkel Flow offers two ways to train models: in-app or via the Python SDK. Using Python, any custom model that includes language-specific functionality can be trained in the platform. Alternatively, you can quickly iterate on application development fully within the UI when using the models available natively in Snorkel Flow. Currently, we support two approaches that apply to non-English languages:
- Vectorizer + Classify: In this case, the platform applies the Count/TFIDF Vectorizer from Sci-Kit learn on text fields to produce a numeric vector, followed by Logistic-Regression or XGBoost. The scikit-learn vectorizer depends on English-like word boundaries but can be easily modified in code (see this example for Japanese)
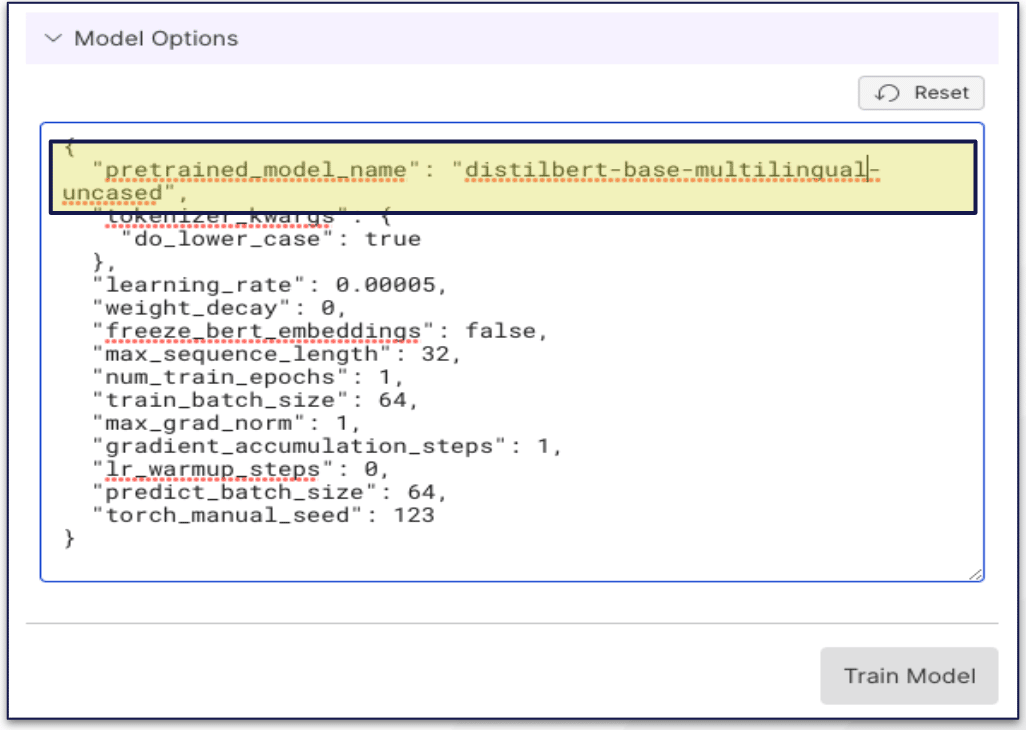
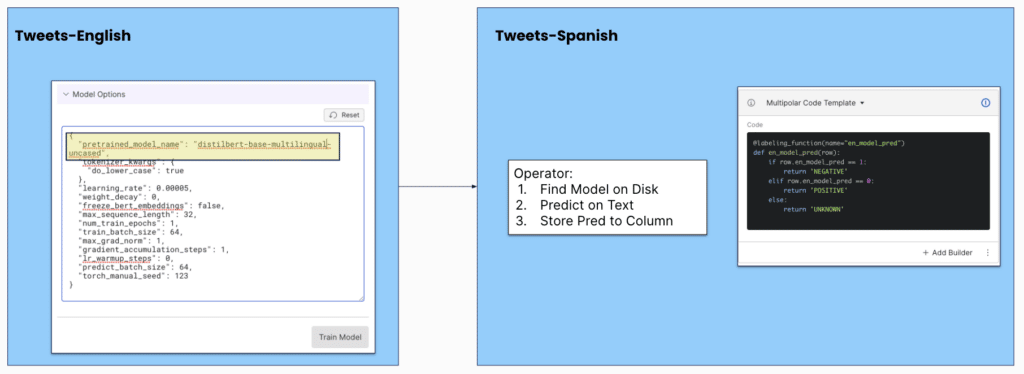
- Running a transformers model: In this case, the user can substitute a different model in the Hugging Face repository by modifying the Model Options JSON. In the example below, I swapped ‘distilbert-base-uncased’ from English for the multi-lingual model with no additional coding.
Analysis
The analysis tools within Snorkel Flow focus on differences between the Label Model and the End ML Model. It supports any language and modality, so you can take advantage of the guided error analysis regardless of which language you’re classifying.
Overall, the goal of the Snorkel Flow platform is to maximize flexibility.
Next, we will show how these abilities were applied to two use cases.
Chinese Named Entity Recognition (NER) Study
Named entity recognition has been a well-researched topic in the field of Natural Language Processing, but NER research in Chinese has received less attention than other languages even though over 16% of the world’s population speaks and reads Chinese. Chinese-language NER research lags other languages primarily due to the lack of widely available Chinese NLP datasets—though characteristics of the Chinese language, such as a lack of delineation between characters and words as well as the special radicals, strokes, and glyphs, also complicate standard NER techniques.
For this task, we used a Chinese NER dataset drawn from the social media website Sina Weibo. This dataset comes with several types of entity types labeled, such as “person,” “location,” etc., and we used a random sample of these labels as the hold-out dataset.
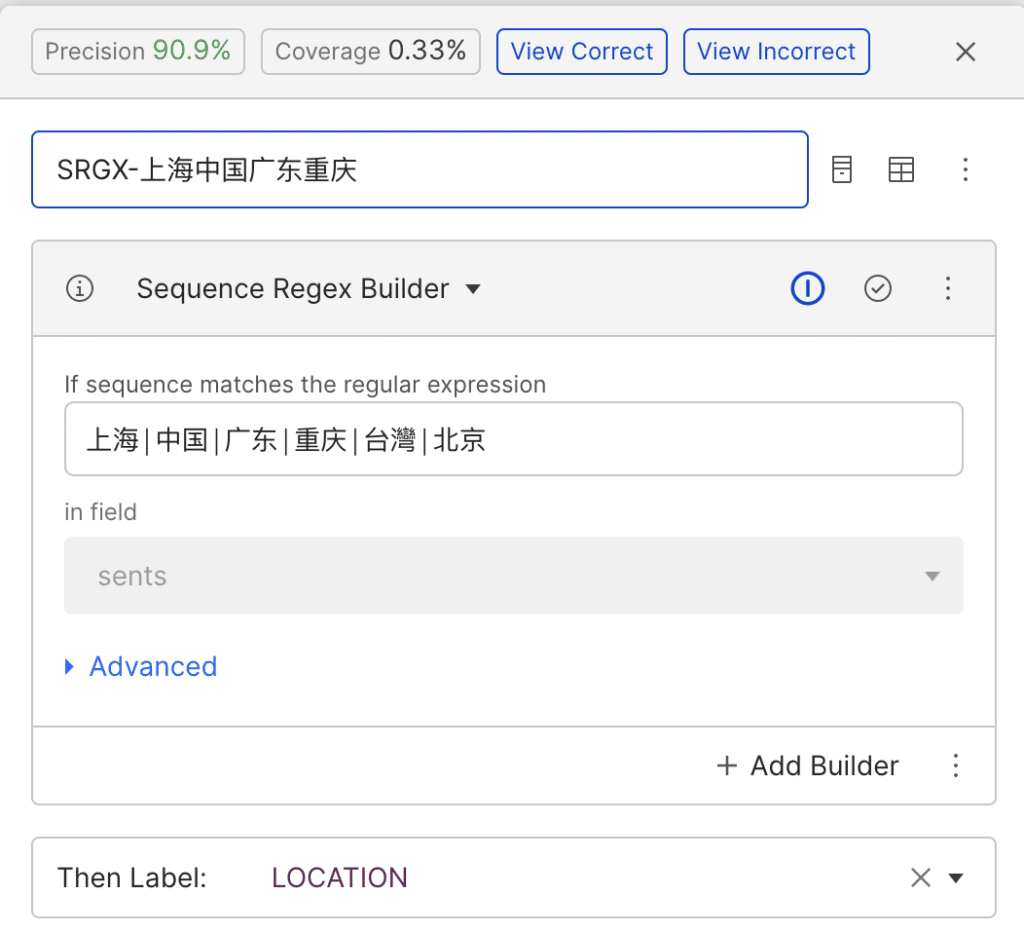
Because Chinese is not space-delimited, we customized the preprocessor within Snorkel Flow to consider each character as its individual entity and calculated end-model metrics based on that.
We used several different labeling functions to quickly generate labels for these entities. One, a regex-based labeling function, extracted a span based on its context. For example, if someone says “my name is”, then the three Chinese characters after that are most likely to be a person since most Chinese names are made of three characters. We also imported a list of popular Chinese cities and districts to quickly label entities that are related to Location.
We then fine-tuned a language model with multilingual capabilities (bert-base-multilingual-cased on Hugging Face) with the labels we created from Snorkel Flow. This language model achieved the benchmarked results below after a single iteration, which exceeded the dataset benchmark of 72.77% across all entities.
| Entity Type | F1 (Token-Level) |
| PERSON | 79.8% |
| LOCATION | 74.2% |
In this case, the ability to customize how the data is preprocessed and embedded allows Snorkel Flow to handle other languages that don’t use the same tokenization mechanism as English. After that, programmatic labeling and the flexibility to import multilingual language models directly on the platform accelerates this workflow and makes iteration much faster and easier.
Multilingual Tweets
Next, we wanted to understand how Snorkel Flow could be used to scale across multiple languages. If a user develops a model for English, what can be reused to solve the same problem in Spanish?
For this task, we used this dataset of tweets related to soccer in English, Spanish, and German. The dataset has binary sentiment labels that were originally generated by Amazon Comprehend.
We first trained a model on English and then tested its performance on a second language with no fine-tuning. In order to make this possible, we needed to use a Language Model with multilingual capabilities. Note that a model based on “Bag-of-Words” would not work since the vocabulary is different in every language.
We chose two modeling approaches:
- Multilingual BERT (MBERT): As discussed previously, this is a language model with the BERT architecture that was trained on 104 languages.
- Multilingual Universal Sentence Encoder (MUSE) + Logistic Regression: The MUSE model produces an embedding given a sentence from 16 languages. Logistic Regression is the simplest strategy for turning it into a classifier (a deeper neutral network could be substituted instead).
Without any fine-tuning, the results were as follows:
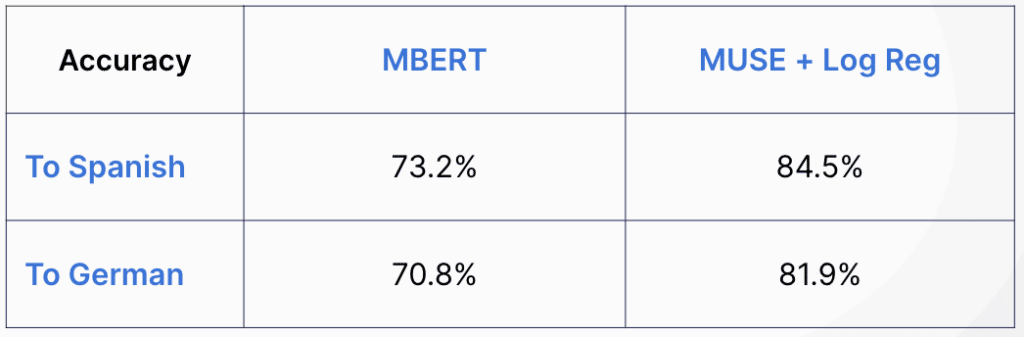
For both language pairs, the MUSE model outperformed MBERT. This could happen for many reasons, including:
- MUSE only includes 16 languages, not 104, so it has a better ability to encode the signal specific to those languages.
- MBERT became too fine-tuned to English (the first language). In the second model, only the weights of LogReg were changed, so it was less likely to overfit.
In any case, the advantage of Snorkel Flow is that these results can be used among other signals. Both of the English models can be incorporated as LFs and their signals can be combined. With Snorkel Flow’s analysis tools, we can discover where these models are failing and write language-specific rules to complement them.
Conclusion
These examples showcase a few capabilities that help data science and machine learning teams to adapt NLP models to a wide variety of languages.
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!


