Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
LLM distillation demystified: a complete guide
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. This lets developers get the same results they would get from an enormous model like GPT-4 at a lower cost and higher velocity—albeit only on that specific task.
While rarely an endpoint, large language model (LLM) distillation lets data science teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches.
LLM distillation basics
Multi-billion parameter language models pre-trained on millions of documents have changed the world. Users can ask ChatGPT, Bard, or Grok any number of questions and often get useful answers.
LLMs’ flexibility dazzles, but most AI problems don’t require flexibility. They require accuracy, speed, and efficiency. LLMs, while amazing, tend to be slow and expensive. That’s where distillation comes in.
What is LLM distillation?
LLM distillation is when data scientists use LLMs to train smaller models. Data scientists can use distillation to jumpstart classification models or to align small-format generative AI (GenAI) models to produce better responses.
How does LLM distillation work?
LLM distillation positions a large generative model as a “teacher” and the smaller model as a “student.” The student model could be a simple model like logistic regression or a foundation model like BERT. In the most basic version of distillation, data scientists start with unlabeled data and ask the LLM to label it. Data scientists then use the synthetically labeled data to train the “student” model, which will mirror the “teacher” model’s performance on the task defined by the original data set.
Data scientists can also use distillation to fine-tune smaller generative models. In this case, they would feed the “teacher” model prompts and capture the responses as training targets for the “student.”
Why would you use LLM distillation?
LLMs like GPT-4, Gemini, and Llama demonstrate incredible power, but also suffer notable drawbacks:
- Cost. Multi-billion parameter LLMs are expensive to host, and even more expensive to access via API.
- Speed. Due to the quantity of calculations necessary, full-sized LLMs can be slow.
- Infrastructure headaches. Hosting private versions of the largest available LLMs means wrangling and coordinating significant resources.
By distilling an LLM, data science teams can build derivative models that are easier to host, cheaper to run, and much more responsive.
What are the drawbacks of LLM distillation?
While a powerful shortcut, LLM distillation is not a cure-all for training new models. The technique suffers from four primary challenges:
- The student is limited by the teacher. In the simplest version of distillation, the “student” model will mirror the performance of the “teacher” model. Generalized LLMs faced with specialized tasks typically fall short of production-grade accuracy.
- You still need a lot of unlabeled data. The LLM will create labels for you, but source data may be in short supply for any number of reasons.
- You may not be allowed to use your unlabeled data. For organizations that are limited from using client data, this may present a real hurdle.
- You may be limited in what LLMs you can use. While not an issue for classification tasks, the terms of service for many LLM APIs bar users from using their LLMs’ output to train potentially competitive generative models.
The first two of these can be overcome using advanced techniques, as discussed below.
Practical LLM distillation for classification challenges
Basic distillation rarely yields production-grade models. In a Snorkel case study classifying user intents for a banking chatbot, our engineers started with labels from Google’s PaLM 2 to achieve an F1 of 50 as a baseline. That’s an impressive performance for an out-of-the-box model—especially considering the case study called for 77 classes—but it would not meet any bank’s bar for deployment.
With a little prompt engineering (encouraging the LLM to behave as an expert in banking and giving one example per label), the team boosted the PaLM 2’s F1 score to 69. That’s much closer to production-grade performance, but not close enough. What, then, can a data scientist do with this not-quite-there dataset? Enrich it.
How to enrich training data with targeted human labeling
A model that achieves a 69 F1-score learned decision boundaries from broadly accurate data. That same model can help spot questionable training examples.
By turning the model back on its training data, data scientists can find where the model predicts its own training data incorrectly and where it makes predictions with low confidence. They can then isolate these points for human review and update.
While few people enjoy the tedium of manually labeling data, this approach can drastically reduce the number of individual examples humans must inspect. Data science teams that want to further reduce the need for human labeling can employ supervised or semi-supervised learning methods to relabel likely-incorrect records based on the patterns set by the high-confidence data points.
In cases where the high-confidence subset of data appears sufficiently robust, data scientists could cast aside all records tagged as likely-incorrect and train their model with the remainder.
Enriching data sets with multi-signal distillation
Data scientists can distill labels from multiple sources of signal. At the simplest level, they can send the same documents and well-engineered prompts to several publicly available LLMs. The best of the breed might achieve 69 F1 on its own, but several LLMs “voting” on the right answer typically achieve better performance than any individual model.
Data scientists can also target sections of the data set with additional, narrowly focused prompts or heuristic rules. For example, our engineer In the banking chatbot case added a rule that applied the label “card_arrival” to utterances that contained the words “card” and “track.” They also could have approached this challenge with a narrow prompt sent to an LLM, such as asking “Does this text ask about the arrival of an ATM card?”
While this approach is potent (we use it in our Snorkel Flow AI data development platform), it requires data scientists to reconcile conflicting signals. Simple voting yields diminishing returns as data scientists add more sources of signal. Snorkel Flow uses an advanced version of an approach called weak supervision.
Generative LLM distillation with prompts and responses
Generative LLM distillation with prompts and responses works similarly to LLM distillation for classification models. The main difference between the two practices is that data scientists extract responses from the teacher model instead of labels.
Once a data scientist gathers responses from the teacher model, fine-tuning the student model works the same way it would with human-generated prompts and responses.
It’s worth noting that the terms of service for the most popular LLMs available by API bar users from using their output to build potentially competitive commercial models. That means that GPT-4 and its kin are off-limits for this approach in the enterprise. Enterprise data science teams using distillation for generative purposes must limit their universe of “teacher” models to those available in the open source community.
A different approach: knowledge distillation
Knowledge distillation uses a larger “teacher” neural network model to sharpen the performance of a smaller “student’ neural network.
The concept of knowledge distillation for neural networks stretches back to a 2015 paper, and made a serious mark on data science well before the arrival of ChatGPT. In 2019, researchers introduced DistillBERT, which used knowledge distillation during pre-training “to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities.”
At the time of this writing, DistillBERT was among the 20 most downloaded models on Hugging Face.
How does knowledge distillation work?
Knowledge distillation focuses on training the student model’s probability distribution to mimic those of the teacher model. This differs from the approaches discussed above, which care only about the teacher LLM’s output. Some knowledge distillation approaches train the student model directly on the “soft target” of the teacher model’s probability distribution. Others use the teacher model’s textual output and convert it to numerical vectors.
This has had significant impacts on non-generative models through achievements like DistillBERT, but can have downsides when used to shrink to generative models; the smaller model can overfit to the teacher model’s training examples, resulting in inaccurate or repetitive responses.
Better knowledge distillation for generative models
While still an active area of study, researchers have developed a promising method for improving knowledge distillation for generative models with an approach called “MiniLLM.”
Like some previous knowledge distillation approaches, MiniLLM uses “soft targets” extracted directly from the teacher model instead of its textual output. However, previous “soft target” knowledge distillation methods encouraged the student model to mimic the entire probability distribution. MiniLLM encourages the student to focus only on high-probability outcomes.
In experiments, MiniLLM led to improvements of as much as 15 points over previous training methods and sometimes produced student models that outperformed their teachers.
Limitations of knowledge distillation
While knowledge distillation can achieve meaningful gains in the performance of smaller generative models, enterprise data scientists likely can’t use popular API-based models as knowledge distillation “teachers.” OpenAI, Google, and Meta all bar users from training potential competitors using their LLMs’ output.
Even without that limitation, data scientists would be unable to use “soft target” approaches like MiniLLM on APIs that only return text. These approaches require data scientists to have full access to the probability distributions as well as the output.
For all of these reasons, knowledge distillation efforts will be primarily limited to open source models.
LLMs distilling themselves: context distillation
Researchers and data scientists have achieved significant performance gains in language generation by cleverly engineering prompts. They may include a message that encourages the prompt to respond like a particular avatar (“you are an expert data scientist…”), to include example prompts and responses, or to use a “scratch pad” to allow the LLM to work out some logic before rendering a final answer.
However, the model does not learn from these highly-engineered prompts. The performance improvements dissipate as soon as the model responds.
Researchers at the University of California at Berkley found a way to change this, which they call “context distillation.” They built heavily-engineered prompts that ended with simple questions, such as “add these numbers.” Then, they stripped the prompt of its engineering and reduced the response to only its final answer to create a new data set that they used to fine-tune the model.
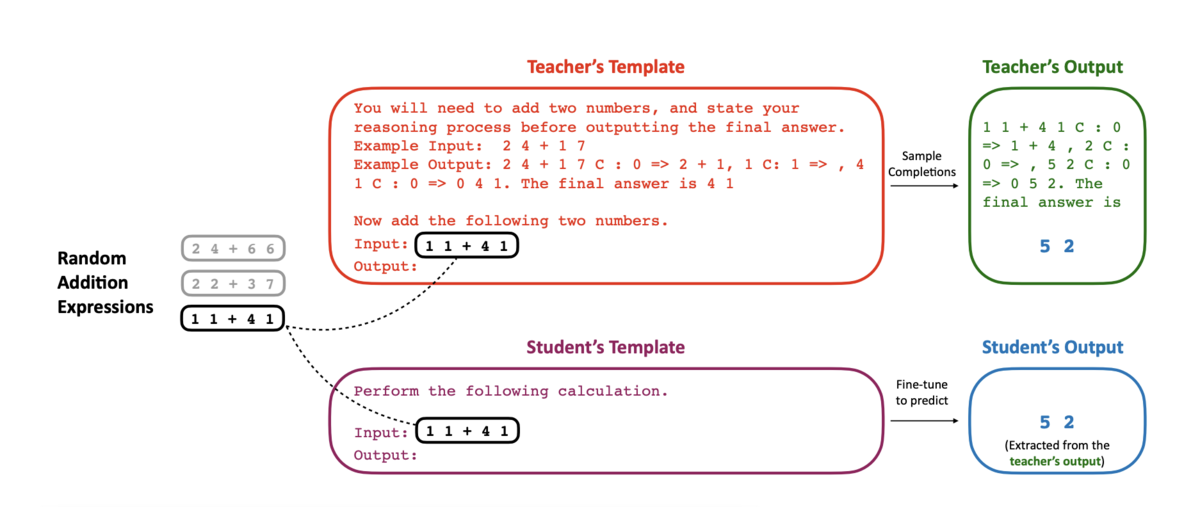
When they then asked the fine-tuned models the same questions with no added context, they found that the rate at which the model answered correctly increased.
In their research, the “teacher” and “student” models were the same size. However, this approach theoretically extends to distilling the responses to context-rich prompts generated by larger models to bolster smaller models.
Generative LLMs for predictive tasks: distilling step-by-step
While distillation has proven again and again to be useful in bootstrapping smaller models that perform nearly as well as teacher models at a tiny fraction of the inference cost, the approach comes with one minor limitation: it requires a large amount of raw data.
While a lack of labeled data bottlenecks many AI projects, distillation can be bottlenecked by a lack of unlabeled data. Imagine, for example, that you want a model to classify contract clauses into a dozen categories, but you have very few raw examples to train from. In a strict LLM to classifier model use case, you likely couldn’t get the performance you need.
However, the distilling step-by-step approach developed by researchers at Google and Snorkel AI allows data scientists to fine-tune a small generative model for classification tasks on as little as one-eighth as much data as traditional fine-tuning would require.
The approach works by asking the teacher model to return not only its answer but also the rationale behind its answer. The training pipeline then directs the student model to do the same—to yield both a final response and reasoning for that response. The pipeline updates the model’s weights according to both portions of its output.

While powerful, this approach only works when distilling to a smaller generative model. It does not allow data scientists to mirror the classification accuracy of something as powerful as GPT-4 in a footprint as small as DistillBERT. However, researchers were able to use a model up to 700 times smaller than their teacher model (PaLM, at 540 billion parameters) while achieving comparable results.
LLM distillation: get to useful, inexpensive models faster!
While LLM distillation has been the province of cutting-edge researchers, it’s poised to become a significant tool for enterprise data science teams in 2024. A poll we conducted at our October 2023 Enterprise LLM Summit found that few enterprise data science teams had used LLM distillation up until that point, but a significant majority of them likely would in the new year.
We’re not alone in this prediction. Luminaries in the data science space including Hugging Face CEO Clement Delangue said he also expected cheaper, more specialized models to rise in importance in the new year.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Matt Casey
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.