
LLM distillation will become a much more common and important practice for data science teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit.
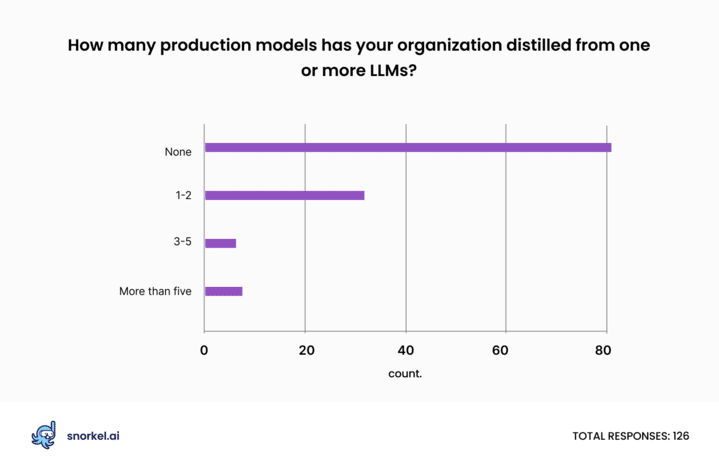
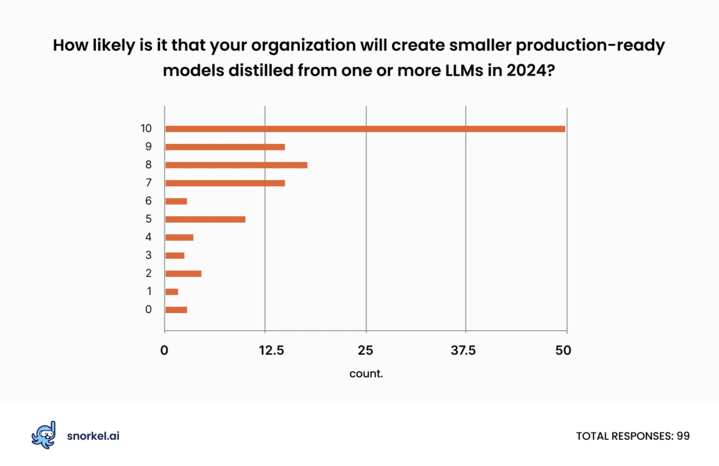
Only about a third of respondents (36%) said that their company had distilled any smaller models from LLMs so far. However, 74% said their organization would probably employ LLM distillation to create compact, production-ready models in the coming year.

These results—especially when combined with answers to other questions from our poll—suggest that previously little-noticed LLM distillation techniques are about to take a bigger role in the enterprise space. And we are not alone in seeing this trend. Clem Dalangue, Co-Founder and CEO of Hugging Face, recently predicted that 2024 will be the year when companies realize that smaller models make sense for the vast majority of use cases.
What factors make LLM distillation more important?
Generative AI and large language models stood at the “Peak of Inflated Expectations” in Gartner’s 2023 Hype Cycle report for AI, and they’re beginning to slip into the “Trough of Disillusionment.”
LLMs remain amazing. Their ability to perform competently at tasks they were not trained for is incredible. But their performance on enterprise-critical tasks falls short of accuracy benchmarks set for deployment. Even when LLMs clear those benchmarks, they’re often prohibitively expensive to run for high-throughput applications. To use an analogy, they’re like using a supercomputer to play Frogger. It will work, but you’re burning more resources than necessary.
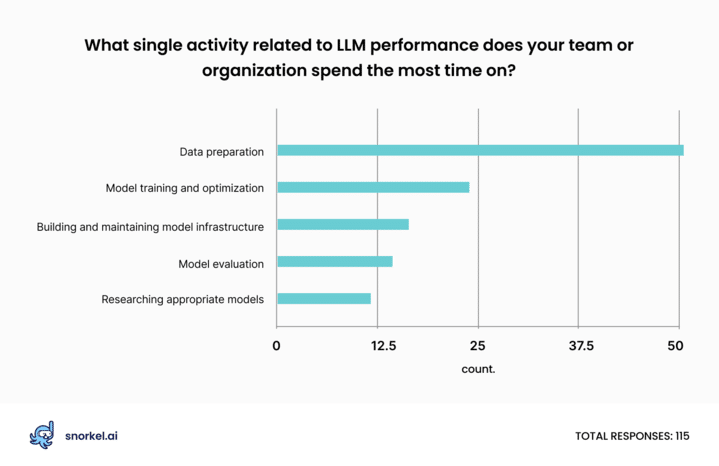
As data science teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling. According to our poll participants, data preparation still occupies more data scientists’ hours than anything else. LLM distillation creates an opportunity to shrink that burden and allow teams to ship more models, faster.
What is LLM distillation?
LLM distillation is a collection of approaches that use one or more large models to “teach” a smaller model to complete a specific task. This family of techniques allows data science teams to harness the power of models with tens or hundreds of billions of parameters in a format that’s easier to deploy and far less expensive to use at inference time.
In its simplest form, data scientists employ LLM distillation by prompting an LLM to apply labels to otherwise unlabeled data. This creates a training set used to train a smaller model, which could be a neural network or something as simple as logistic regression.
Data scientists can enhance distillation’s effectiveness by first fine-tuning the “teacher” model. They can also use more advanced approaches to distill the power of multiple LLMs through programmatic labeling or use an approach known as “distilling step-by-step,” as Snorkel researcher Jason Fries explained in his summit presentation. In addition to their size and cost reductions, these advanced approaches can yield models that achieve higher accuracy scores than their parent models.
Model safety remains a top concern; data follows closely
Respondents at organizations large and small named “model risk”—such as hallucinations, bias, and the risk of divulging intellectual property—as the biggest gap they would like to overcome when using LLMs. This is consistent with findings from our earlier event polls, though the thrust of this question was slightly different.
LLMs’ continued tendency to sometimes deliver wildly wrong or offensive responses has been a consistent theme for those who say LLMs are not ready for prime time. As Yoav Shoham, co-founder of AI21 Labs, put it at our Future of Data-Centric AI event in June: “If you’re brilliant 90% of the time and nonsensical or just wrong 10% of the time, that’s a non-starter. It kills all credibility or trust, and you can’t have that.”
Data quality and quantity closely followed model risk—and even tied model risk as a primary gap among the subset of respondents working at companies with valuations of at least a $1 billion.
These issues are closely related. Fine-tuning offers one of the best ways to reduce model risk, and fine-tuning requires meaningful quantities of high-quality hard-to-label data. Data science teams can also side-step the problems of model risk through distillation. While narrowly-trained classification models can be wrong, they’re typically not capable of hallucinating.

Will “LLM distillation” be the AI word of 2024?
Data science teams feel pressure to deliver value through LLMs in the next year, even as concerns around LLM model risk endure. Our poll results suggest that many practitioners think LLM distillation may be the answer they’ve been overlooking.
While companies have—so far—done very little model distillation, it seems that data scientists and data science leaders see its potential. If our poll results reflect reality, we expect to see enterprises deploy many more models created through distillation in 2024 than we did in 2023.
Get a demo from Snorkel AI
Advanced distillation approaches in Snorkel Flow enabled our researchers to build a model as accurate as a fine-tuned version of GPT-3 that cost 25% as much to train and 0.1% as much to run. We can deliver similar results for your organization.
With Snorkel Flow, you can:
- Label and curate data at scale in a repeatable, auditable iterative process that lets you reduce months of work to days or hours.
- Fine-tune large language models to boost their performance on your specific domain and use cases.
- Distill the power of LLMs into small models to get accurate, reliable, and affordable models into production faster.
- Sharpen your generative AI systems to meet the tone and factual accuracy your company needs.
- Curate and enrich data for retrieval augmented generation (RAG) to ensure that your application feeds your LLM the exact context it needs at minimal latency.
Contact us at info@snorkel.ai or request a demo to get started or to learn more.

Matt Casey
Data Science Content Lead
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

