
Table of contents
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production.
As foundation models, large LLMs like GPT-4 and Gemini consolidate internet-scale text datasets and excel at a wide range of tasks. While the performance of these models is impressive, so too are their computational costs. These models are expensive to run, even for inference, and can severely tax resource-constrained enterprise workloads.
Thus, it’s important to remember that the latest and greatest in LLM tech is built upon years of prior research, and many of the previous generation of models, especially Google’s BERT, still provide great performance at a lower cost.
Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound. Enterprise data science teams can adapt these BERT transformer models quickly and cleanly.
BERT origins and basics
Researchers released Google BERT in October 2018, not long after the seminal Attention is All You Need paper (which introduced the transformer building block for large language models.) This makes BERT one of the original LLM architectures. It’s also one of the simplest.
BERT’s architecture heavily utilizes transformer layers to achieve excellent performance on a range of tasks. It is an encoder-only architecture, meaning that input text is only encoded into a finite-dimensional vector representation, and never decoded back into text.
BERT can handle a variety of modeling tasks, including:
- Question answering
- Natural language understanding
- Text classification
- Sentiment analysis
- Next word prediction
- Summarization
Unlike larger natural language models, such as GPT-3, Google BERT performs poorly on machine translation. This typically requires the model to encode text from the source language and then decode it into the target language using a trained decoder module.
Still, the simplicity of BERT is a marked benefit. Popular LLMs such as PaLM 2 and GPT-4 require complex distributed systems of GPUs for inference and fine-tuning. In contrast, BERT training pipelines often fit on modern laptops, and data scientists can fine-tune a variety of BERT derivatives to adapt them to new tasks through transfer learning
BERT’s NLP advantages
BERT offers several advantages relative to other LLMs. It has achieved widespread adoption in both industry and research, which has encouraged researchers and data scientists to publish a variety of pre-trained BERT models as well as comprehensive tutorials. BERT also excels at several tasks that are common in enterprises, namely text classification, data labeling, and ranking and recommendation.
Text classification and representation
What BERT does well, it does really well. A transformer BERT model is often the go-to for text classification and representation. BERT excels at building vector representations for text, and those representations can then be used in a variety of downstream tasks.
Data labeling
BERT shines in semi-supervised data labeling. Data scientists who need data to train a complex model can use pre-trained BERT LLM architectures to predict labels for unlabelled data.
For example, a pre-trained BERT LLM equipped with a classification layer can provide sentiment analysis labels. A data scientist can then use these labels to train a smaller classification model and deploy it in an enterprise pipeline. This lets enterprise data science teams build accurate models faster, without waiting for and relying on human-annotated data.
Ranking and recommendation
Because transformer BERT LLM models produce high-quality text representations, these representations often provide a natural choice as inputs for ranking and recommendation services. By computing similarities between representations, data scientists can use BERT vectors to rank objects such as products or user reviews in e-commerce settings. Google, for example, uses BERT to rank search results, and developers have also developed BERT-based systems to recommend products in Amazon’s marketplace.
Computational efficiency
BERT models are much smaller than the current generation of LLMs, allowing them to be trained on single GPUs and sometimes even laptops. Furthermore, using a machine learning technique called knowledge distillation, researchers created smaller versions of BERT, such as DistilBERT, which retain most of BERT’s performance in a fraction of the parameter count. Some of these models can even be run on embedded devices and phones.
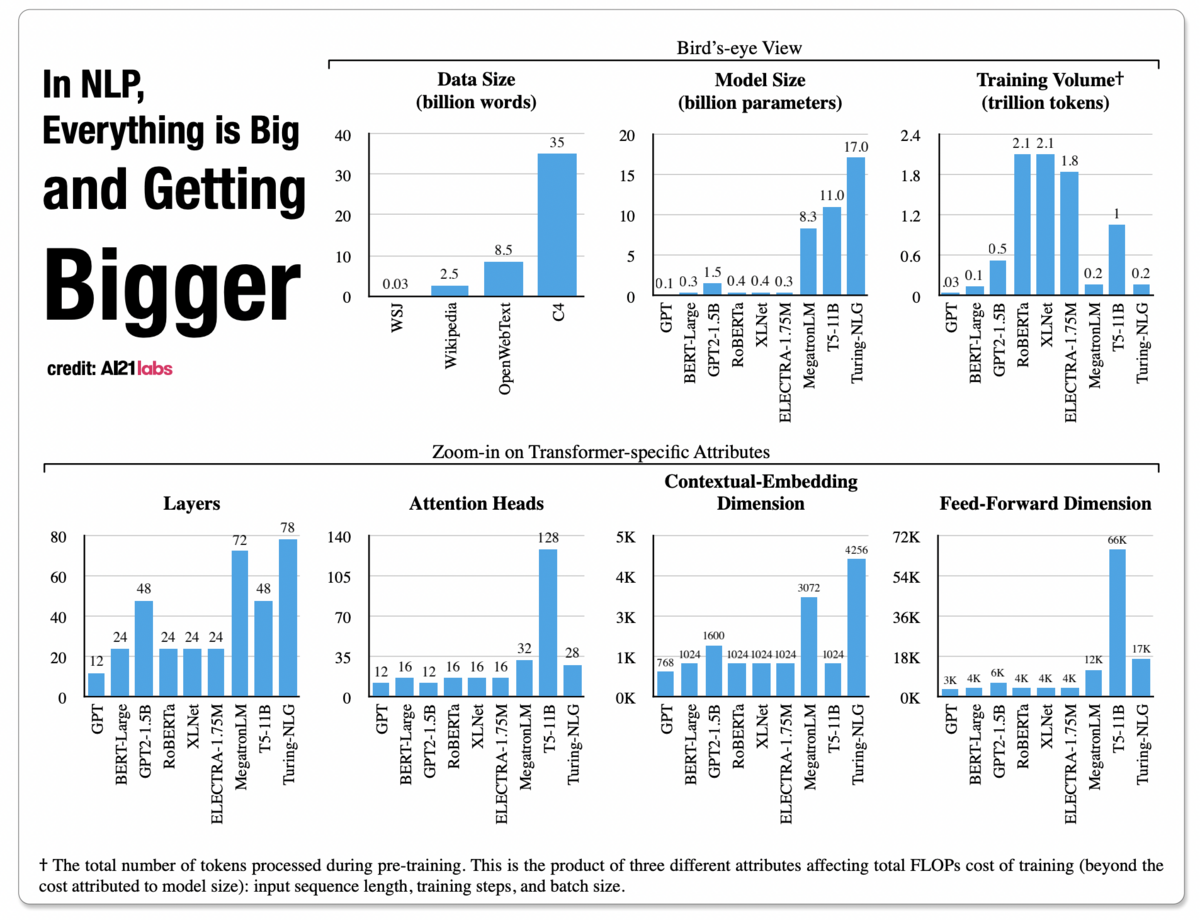
For reference, here are some popular large language models ranked according to size:
- GPT-4 (~1 trillion)
- GPT-3 (175 billion)
- Llama (65 billion)
- T5 (11 billion)
- Alpaca (7 billion)
- GPT-2 (1.5 billion)
- BERT-Large (340 million)
- BERT-Base (110 million)
- DistilBERT (66 million)
Accelerated development
BERT’s computational efficiency enables accelerated development and deployment. Data scientists can train or fine-tune DistilBERT and similarly compressed BERT models in hours rather than days or weeks. Data teams can often fine-tune distilled BERT variants using comparatively small amounts of in-house data and far exceed the performance of simpler models.
BERT language models: not built for generation
One caveat of BERT compared to other LLMs is that it is not designed to handle text generation.
While it’s not strictly impossible to generate text using BERT, it’s not straightforward due to its bidirectional architecture. Bidirectional in this context means the model is trained to predict the next word in a sentence when reading the sentence both forwards and backwards.
Generative AI LLMs typically perform language modeling only in the forward direction. Researchers and developers have built demonstrations using BERT for text generation, but doing so requires awkward software architectures and produces lower-quality output than the current generation of generative text models.
However, BERT can also be used as a “helper” when training true text generation models. For example, in this paper, researchers from Microsoft and Carnegie Mellon used BERT as the teacher in a student-teacher setup for training a sequence-to-sequence text generation model.
HuggingFace and similar libraries support using BERT for text generation, although the use of architectures designed specifically for this task, such as GPT-2, is recommended.
BERT LLM: The chameleon model
BERT is truly chameleon-like in its capabilities—adaptable as it is to a wide variety of tasks and settings.
Data scientists typically adapt BERT through what are often called neural adaptation layers or, more colloquially, heads. A task-specific head allows a user to take a BERT base model and adapt it to a given task. Each task typically has its own type of adaptation layer.
- Linear layers (with optional softmax) are often used as the head in classification settings to output raw logit scores (or probabilities) for each class.
- Sequential layers such as LSTMs are useful as heads for tasks such as summarization and translation.
- Linear layers combined with an output softmax are useful for language modeling and question answering.
The BERT documentation published by Hugging Face includes a full discussion of the variety of BERT modeling heads and their uses.
Building a classification model
Here we walk through a simplified version of using BERT’s NLP abilities to build a text classification model.
- Gather the training data, including examples of each of the text classes.
- Tokenize the data, using one of Hugging Face’s BERT-specific tokenizers.
- Download a pre-trained BERT classification model. This is the code you can use in HuggingFace:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(“bert-base-cased”, num_labels=5)
- Finetune the model on your classification data, perhaps using the HF Trainer class.
- Evaluate your model on a held-out validation set.
- Rinse and repeat as needed.
You can get a more detailed look at this process in the HuggingFace finetuning tutorial.
Google BERT Usage in the real-world
While the current generation of LLMs are gaining enterprise adoption, BERT has already achieved ubiquity in real-world contexts.
Google integrated BERT into Google Search, using it to surface highly accurate results for almost every English query. Similarly, a technical blog post from Wayfair shows how they use BERT to glean insights from unstructured text such as customer product reviews and feedback. BERT is also used to mine sentiment in financial documents, with one of the world’s largest technology investors, Prosus, using it to guide investment decisions. Additionally, variants of BERT have been fine-tuned for legal, scientific, and biomedical applications.
In fact, you’d be hard-pressed to find an enterprise domain to which the BERT language model hasn’t been applied.
BERT variants
Data scientists and researchers have built many data-and-task-specific BERT variants. Here are a few of the most popular ones:
- RoBERTa
- DistilBERT (compact, efficient, distilled version of BERT)
- SciBERT (trained on scientific texts)
- BioBERT (trained on Biomedical text)
- BigBird (designed to model longer sequences)
- FlauBERT (for French language modeling)
- SqueezeBERT (an efficient form of BERT using convolutional layers)
- MobileBERT (designed specifically to run on phones and other mobile devices)
- HerBERT (for Polish)
- BERTweet (for understanding tweets)
All of these models, and many more, are available for free download on the Hugging Face Model Hub.
BERT: the workhorse LLM
Due to its low computation requirements, easy-to-understand architecture, and the large availability of open source fine-tuned models, BERT is an excellent choice of large language model for enterprises. It can be used in a variety of niche domains and optimized for performance across a range of tasks, from text classification, to question answering, to language representation, and more!
Frequently asked questions about Google’s BERT models
Below follow some frequently asked questions about BERT models—along with their answers.
What is a BERT model?
BERT stands for Bidirectional Encoder Representations from Transformers. It’s a large language model (LLM) trained on a massive dataset of text and code. BERT excels at understanding the relationships between words and can be used for various NLP tasks.
What is the difference between BERT LLM and other LLMs?
BERT differs from some LLMs like GPT-3 in its focus on understanding existing text rather than generating new text. Additionally, BERT is known for its smaller size and faster training times compared to other cutting-edge LLMs.
What are the advantages of using BERT NLP?
BERT offers several advantages, including:
- High accuracy: Performs well on various NLP tasks like classification, sentiment analysis, and question answering.
- Efficiency: Requires fewer resources to train and run compared to larger LLMs, making it suitable for various business applications.
- Adaptability: Can be fine-tuned for specific tasks and domains through transfer learning, leveraging its pre-trained knowledge.
- Open-source availability: Numerous pre-trained models and resources are readily available for free on platforms like Hugging Face.
What are some real-world use cases of BERT models?
BERT powers applications across several domains, including:
- Search engines: Google utilizes BERT to improve search result accuracy and relevance.
- Customer service: Businesses leverage BERT for sentiment analysis in customer reviews and feedback.
- Finance: BERT can be used to analyze sentiment in financial documents and guide investment decisions.
- Legal and scientific fields: Specialized BERT variants like BioBERT and SciBERT support tasks in these domains.
How does the BERT model work?
BERT utilizes a transformer architecture, which analyzes the relationships between words in a sentence bidirectionally (both forwards and backwards). This allows it to understand the context and meaning of each word within the sentence.
What are BERT’s limitations?
While powerful, BERT has limitations. While technically possible, generating high-quality text with BERT is challenging due to its bidirectional nature. BERT’s general-purpose nature might necessitate fine tuning for optimal performance on specific tasks—though finding a useful BERT variant can reduce the amount of fine tuning necessary.
What are some popular BERT variants?
Numerous BERT variants exist, each tailored for specific tasks or domains. Here are a few examples:
- DistilBERT: A compact and efficient version of BERT.
- SciBERT: Trained on scientific text for tasks in that domain.
- BioBERT: Focused on understanding and processing biomedical text.
- MobileBERT: Designed for running on mobile devices with limited resources.
How can I use BERT models in my projects?
Several open-source libraries like Hugging Face provide pre-trained BERT models and tools for fine-tuning and integration into your projects.
Is BERT suitable for sentiment analysis?
BERT excels at sentiment analysis. You can fine-tune a pre-trained BERT model to categorize text as positive, negative, or neutral based on its sentiment.
Is Google BERT open-source?
The core BERT model is not directly open-sourced by Google. However, numerous open-source implementations and pre-trained models are available on platforms like Hugging Face.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Matt Casey
Data Science Content Lead
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

