100x
All articles on
Data development

Weak supervision for non-categorical applications + superalignment
We need more labeled data than ever, so we have explored weak supervision for non-categorical applications—with notable results.


Vision language models: how LLMs boost image classification
Vision language models demonstrate impressive image classification capabilities, but LLMs can help improve their performance. Learn how.


How Bonito helps fine-tune specialized LLMs faster than ever
Fine-tuning specialized LLMs demands a lot of time and cost We developed Bonito to make this process faster, cheaper, and easier.

Accelerating AI development in manufacturing with Snorkel Flow and AWS SageMaker
The manufacturing industry has experienced a massive influx of data. Snorkel AI and AWS Sage Maker can make that data actionable.


The art of data development for Enterprise LLMs
Snorkel’s Paroma Varma and Google’s Ali Arsenjani discus the role of data in the development and implementation of LLMs.


How Snorkel topped the AlpacaEval leaderboard (and why we’re not there anymore)
Snorkel AI placed a model at the top of the AlpacaEval leaderboard. Here’s how we built it, and how it changed AlpacaEval’s metrics.


CRFM’s HELM and enterprise LLM evaluation beyond accuracy
As Snorkel AI prepares to build better enterprise LLM evaluations, we spoke with Yifan Mail from Stanford’s CRFM HELM project.


Here’s how Snorkel Flow + Google AI built an enterprise-ready model in a day
Google and Snorkel AI customized PaLM 2 using domain expertise and data development to improve performance by 38 F1 points in a matter of hours.



How Skill-it! enables faster, better LLM training
Humans learn tasks better when taught in a logical order. So do LLMs. Researchers developed a way to exploit this tendency called “Skill-it!”


Fine-tuned representation models boost LLM systems. Here’s how
Fine-tuned representation models are often the most effective way to boost the performance of AI applications. Learn why.


Enterprises must shift their focus from models to data in AI development
Snorkel AI CEO Alex Ratner explains his view on the importance of AI in data development and illustrates his position with two case studies.


Scaling human preferences in AI: Snorkel’s programmatic approach
We’ve developed new approaches to scale human preferences and align LLM output to enterprise users’ expectations by magnifying SME impact.

Building better enterprise AI: incorporating expert feedback in system development
Enterprises that aim to build valuable GenAI applications must view them from a systems-level. LLMs are just one part of an ecosystem.


“Fall in love with your data”—Snorkel AI’s Enterprise LLM Summit
Snorkel AI’s Jan. 25 Enterprise LLM Summit focused on one theme: AI data development drives enterprise AI success.

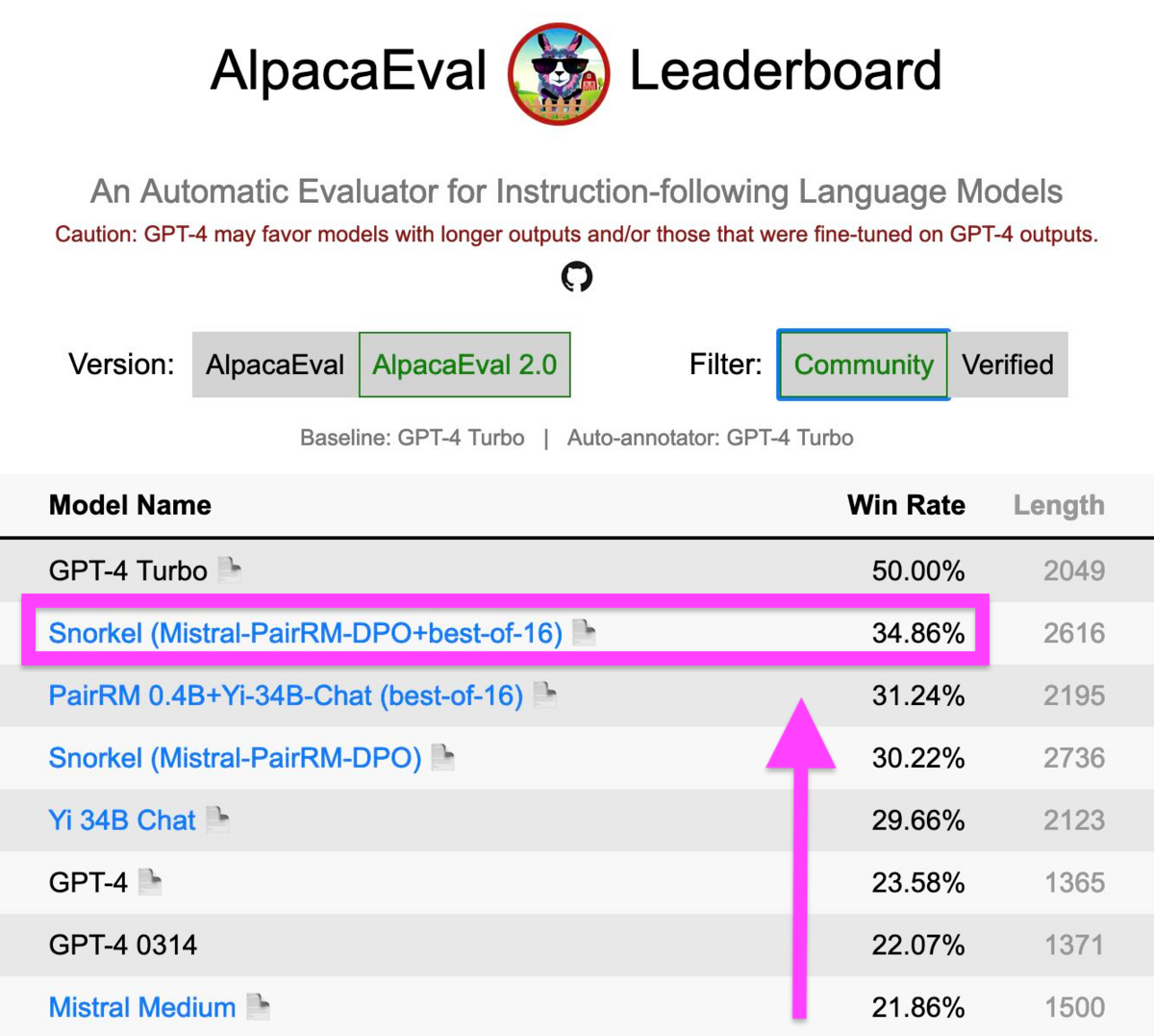
New benchmark results demonstrate value of Snorkel AI approach to LLM alignment
Snorkel researchers’ state-of-the-art methods created a 7B LLM that ranked 2nd, behind only GPT-4 Turbo, on AlpacaEval 2.0 leaderboard.


See how Snorkel can help you get up to:
Faster data curation
40x
Faster model delivery
99%
Model accuracy