Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Beyond prompting: getting production quality LLM performance with Snorkel Flow
Large Language Models (LLMs) have grown increasingly capable in recent years across a wide variety of tasks. The leap forward has been astonishing—even for those who have built AI systems for years.
However, as enterprises begin to look beyond proof-of-concept demos and toward deploying LLM-powered applications on business-critical use cases, they’re learning that these models (often appropriately called “foundation models”) are truly foundations, rather than the entire house.
Building upon these foundations to create production-quality applications requires further development.
In this blog post, we walk through an anonymized real-world use case comparing a variety of state-of-the-art LLMs (GPT 4, GPT 3.5, and Llama 2) and techniques, ultimately showing that a simple DistilBERT model developed with Snorkel Flow outperforms GPT-4 by 34 points out-of-the-box and by 15 points even after advanced prompt engineering.

The task: extracting attributes from product descriptions
Our customer sells products through an online platform and wants to make it easier for their customers to understand what “resistances” available products have—for example, odor-resistance or burn-resistance. The catalog owner wants to automatically extract these attributes from unstructured product descriptions uploaded by vendors and use them to facilitate search, personalized recommendations, and other customer experiences.
In this blog post, we’ll look specifically at the task of extracting “product resistances” for rugs. The presence of these “resistances” can be advertised in a large variety of ways, making this a challenging NLP problem.
Example product descriptions with target extractions:
DESCRIPTION: A distressed brushed effect with high low pile to brighten up any room. Serged on all sides for durability. Extremely durable and very easy to clean. An artful weaving of this area rug creates vintage-style patterns woven with yarns that feature a dual a high-low pile effect for a truly unique texture. The 0.3″ high, 100% polyester yarn is stain resistant, easy to clean, and doesn’t shed or fade over time. A jute backing is safe for wood floors and all four sides of the rug are serged for improved durability.
DESCRIPTION: Kimberlin Handmade Beige Rug. This rug is a wonderful alternative when you want only safe, organic materials in your home. Made from the sisal plant that originated in southern Mexico but now grows in Tanzania, Kenya, and other regions around the world. They’re durable and anti-static, making them ideal for high traffic areas such as a living room or foyer. In addition to being practical, they also create a beautiful, natural appearance when placed on a hardwood floor. Sisal is anti-static, sound-absorbing, naturally resilient and fire-retardant. Made in the USA. Handcrafted. Non-slip latex backing included.
Starting with simple prompting
The simplest way to get an LLM to extract information is to use a simple prompt—tell the model what you’re looking for and what format you want the response in. For example, your input to the model may look something like this, with the description of each individual product listing slotted between the curly brackets:
Product Description: “{product_description}”
Extract all the phrases from Product Description describing the water, stain, fade, or other resistances that the product has. Output the results as a json with key "resistance" and a list of phrases for the value. If none are described, provide an empty list.We tried this prompt with GPT-4, which—while 30x as expensive and 3x as slow as GPT-3.5—is currently the state-of-the-art LLM. Our validation and test splits are annotated on a per-token basis, identifying all “true positive” tokens (~300 total in each split) describing a product resistance. This model and prompt ended up with a token-level score of 49.2 F1. Not bad for a model with no task-specific training, but clearly not production-ready. We needed to iterate!
Improving with data-centric prompt engineering
To improve our performance, we began by applying some of the easy “prompting hacks” that have been shown to yield better results from current leading LLMs on a variety of tasks. For example, we began the instructions portion of our prompt with the phrase “You are an expert in furniture” and encourage the model to “think step by step.”
From there, we used Snorkel Flow to help identify and correct the model’s error modes in a data-centric development process. We corrected these via prompt where possible and then later via additional labeled data for llm fine-tuning.
In some cases, we corrected error modes by updating the instructions in the prompt. For example, after observing that our model rephrased some resistances (versus extracting direct span), we added the instruction to “only extract phrases found in the text and do not create new text.” In an attempt to reduce false positives, we added a final check before responding, such as “For each extracted phrase, if the text is NOT about being ‘resistant’ to something, remove it.”
We corrected other error modes by including specific examples as part of the prompt—a technique called few-shot learning or in-context learning. After observing that our model consistently missed alternate ways of expressing resistance, we found and included an example of a product description with attributes such as “anti-static,” “sound-absorbing,” and “fire-retardant” to demonstrate that these were acceptable. This approach, however, can bump into both hard constraints (maximum supported context length for that model) and soft constraints (the longer your model input, the slower and more expensive the response). In this case, we were limited to three examples due to limits on GPT-4 context length.
Unfortunately, prompt engineering remains a somewhat ad hoc process. LLMs are prone to significant swings in behavior due to seemingly innocuous changes, such as giving the same instruction in different words, or swapping the order of examples. We tried a variety of combinations. After a dozen hours of prompt engineering, the best score we were able to obtain with GPT-4 was 68.4 F1—a clear improvement over our initial 49.2, but still not production quality.
Achieving best results with fine-tuning
For most tasks, fine-tuned specialist models achieve better results than modifying the input prompt for a generic model. We found that to be true for this task as well.
Specialized models can also be significantly smaller than their generalist counterparts without sacrificing quality; far less model capacity is required to perform well at one specific task.
We started by fine-tuning a DistilBERT model using the labels from our best prompted GPT model. This yielded a score of 74.7 F1—a boost of 6.3 points, despite being over 1000x smaller than GPT-3 and over 10,000x smaller than GPT-4!
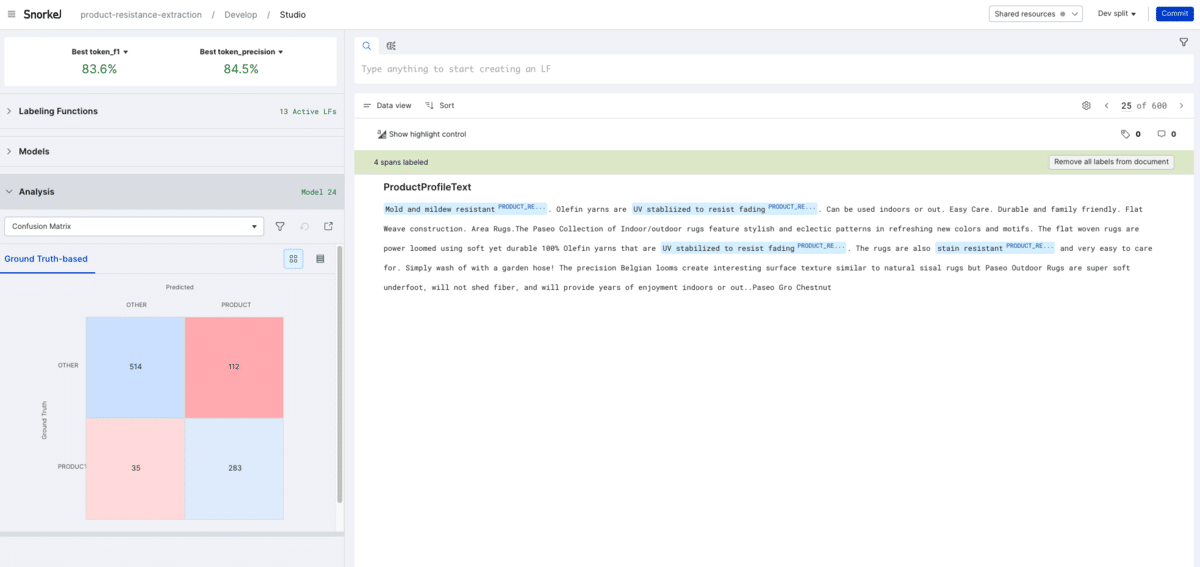
We then transitioned away from prompt-engineering to continue the data-centric iteration process that began in the prompt engineering phase. Using Snorkel Flow, we inspected our best performing model’s errors, then systematically corrected them by creating labeling functions to improve the quality of our training labels (for more information on how programmatic labeling works, check out our primer or blog post). We created seven labeling functions in total—three using simple regular expressions to identify high-precision phrases (e.g. “(mildew|odor|stain|dust|fade|UV|weather|moisture|water).{,30}resistant”); three using additional targeted prompts (e.g. “Is it water resistant?”) with an extractive QA model trained on the Squad dataset; and one using the built-in spaCy part-of-speech tagger to remove extraneous adverbs causing misses between model responses and ground truth (e.g. “incredibly stain-resistant” vs “stain-resistant”).
Using Snorkel to intelligently aggregate these labeling functions’ proposed labels, we obtained an even higher quality training set and our best performing model: a fine-tuned DistilBERT model with a score of 83.6 F1.
Interestingly, fine-tuning GPT-3 (the largest model available for fine-tuning via the OpenAI API) with the same labels actually performed slightly worse (82.5 F1). With maximum performance and significantly reduced inference speed and cost, our specialized DistilBERT model was ready for deployment.
| Model | F1 Score | Improvement | |
| Zero-Shot | GPT 4.0 | 49.2 | +0.0 |
| Prompt-Engineered | GPT 4.0 | 68.4 | +19.2 |
| Fine-Tuned | DistilBERT (GPT labels) | 74.7 | +25.5 |
| Fine-Tuned | DistilBERT (Snorkel labels) | 83.6 | +34.4 |
We repeated this same exercise—comparing zero-shot, prompt engineered, and fine-tuned performance with Llama 2 (13B) and GPT-3.5 and observed the same trends—52.5 and 40.9 zero-shot, 58.9 and 70.7 prompt-engineered, and 60.4 and 82.5 (GPT-3) fine-tuned.
LLMs: specialists beat generalists for narrow tasks
Foundation models such as LLMs are an exciting development that will accelerate many valuable applications of AI to real-world problems—but they’re not enough on their own.
In this case study, we used Snorkel Flow to demonstrate what the data-centric development process looks like on a real-world task, and how intentional, iterative identification and correction of errors (via the prompt or labeled data for fine-tuning) can lead to significantly more capable specialist models than what’s available from even state-of-the-art LLMs “out-of-the-box.”
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Hoang Tran
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor's degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.

Fait Poms