
The recent debut of ChatGPT astounded the public with the power and speed of foundation models, but their enterprise use remains hampered by adaptation and deployment challenges. In the past year, Snorkel AI has researched several ways to overcome those challenges.
In 2022, Snorkel researchers and our academic partners published seven papers on foundation models, including a 161-page deep dive into the promise and peril presented by these incredibly potent, but poorly understood, tools. Other papers devised strategies to coax greater performance from foundation models – sometimes while simultaneously decreasing their size and cost.
Join us for a free virtual foundation model summit that will bring together speakers from Google, Cohere, Stability AI, Stanford, and more to discuss enterprise applications, best practices, and the latest research in the field of foundation models (FMs) and large language models (LLMs).
As the development of AI progresses, so too does the sophistication of its underlying models, which can be applied to a variety of tasks. While these individual research efforts are important in their own right, understanding how they unlock new, data-centric workflows is key to unlocking the true potential of AI and foundation models for enterprises.
As an object lesson in the potency of large language models such as GPT-3, portions of this article – including most of the preceding paragraph – have been generated in whole or in part through their use.
Below follows a summary of each of the seven papers. To learn more about Snorkel’s research efforts, check out our index of Snorkel research papers.
Ask Me Anything: A Simple Strategy for Prompting Language Models
Simran Arora, Avanika Narayan, Mayee F. Chen, Laurel Orr, Neel Guha, Kush Bhatia, Ines Chami, Frederic Sala, and Christopher Ré

Researchers at Stanford, University of Wisconsin-Madison and Numbers Station AI (under the supervision of Snorkel co-founder Christopher Ré) found that Ask Me Anything (AMA) Prompting enables open-source large language models to exceed the few-shot performance of models 30 times their size. Their paper identifies effective prompt formats, finds a strategy for scalably reformatting task inputs, and proposes the use of weak supervision to reliably aggregate predictions.
The researchers applied AMA across open-source model families and sizes, demonstrating an average performance lift of 10.2 percent over the few-shot baseline. This strategy enabled the open-source GPT-J model (with 6 billion parameters) to match and exceed the performance of few-shot GPT-3 (with 175 billion parameters) on 15 of 20 popular benchmarks.
Learning to Compose Soft Prompts for Compositional Zero-Shot Learning
Nihal V. Nayak, Peilin Yu, Stephen H. Bach
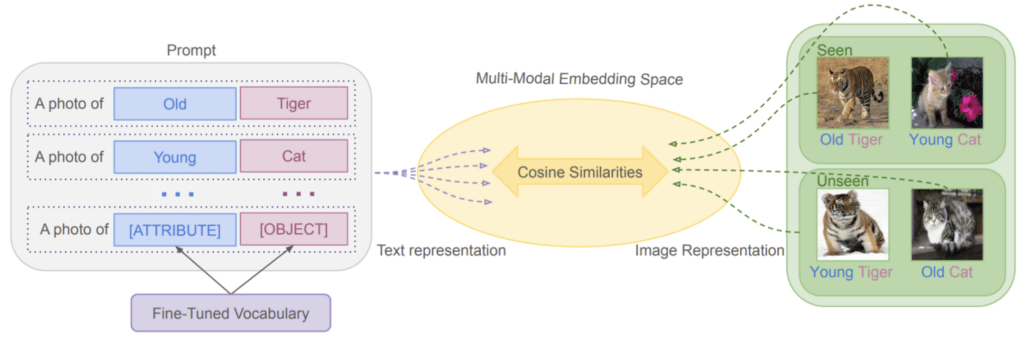
Researchers at Brown, including Snorkel researcher Stephen Bach, explored a novel form of prompting called compositional soft prompting (CSP) to improve the compositionality of vision-language models (VLMs). CSP treats the attributes and objects that are composed to define classes as learnable tokens of vocabulary. The researchers tuned on multiple [attribute] and [object] prompt compositions and recomposed them into new prompts for zero-shot inference.
The paper’s results found that CSP outperforms the original VLM on benchmark datasets by an average of 10.9 percent. The researchers also performed additional experiments to show that CSP improves generalization to attribute-only classification, higher-order attribute-attribute-object compositions, and combinations of pretrained attributes and fine-tuned objects.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach et al.
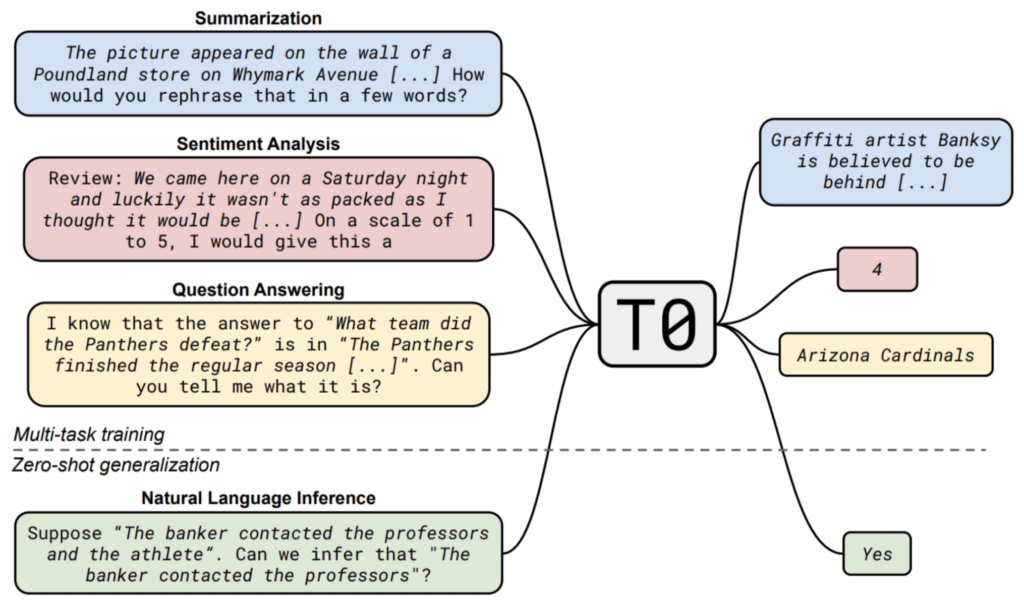
A team of more than 40 researchers from many universities and companies, including Snorkel’s Stephen Bach and Jason Alan Fries, found that explicit multitask-prompted training can enable strong zero-shot generalization abilities in language models. The researchers trained a T5 encoder-decoder model on a large set of datasets with multiple natural language prompts and evaluated the model’s performance on held-out tasks.
This approach yielded substantial gains over a non-prompted version of the same model, often outperforming models up to 16 times its size. The researchers found that training on more prompts per dataset consistently improved the median and decreased the variability of performance on held-out tasks. The results provide an effective alternative to unsupervised language model pretraining and suggest potential opportunities for improving zero-shot generalization through prompted training.
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Percy Liang, et al.
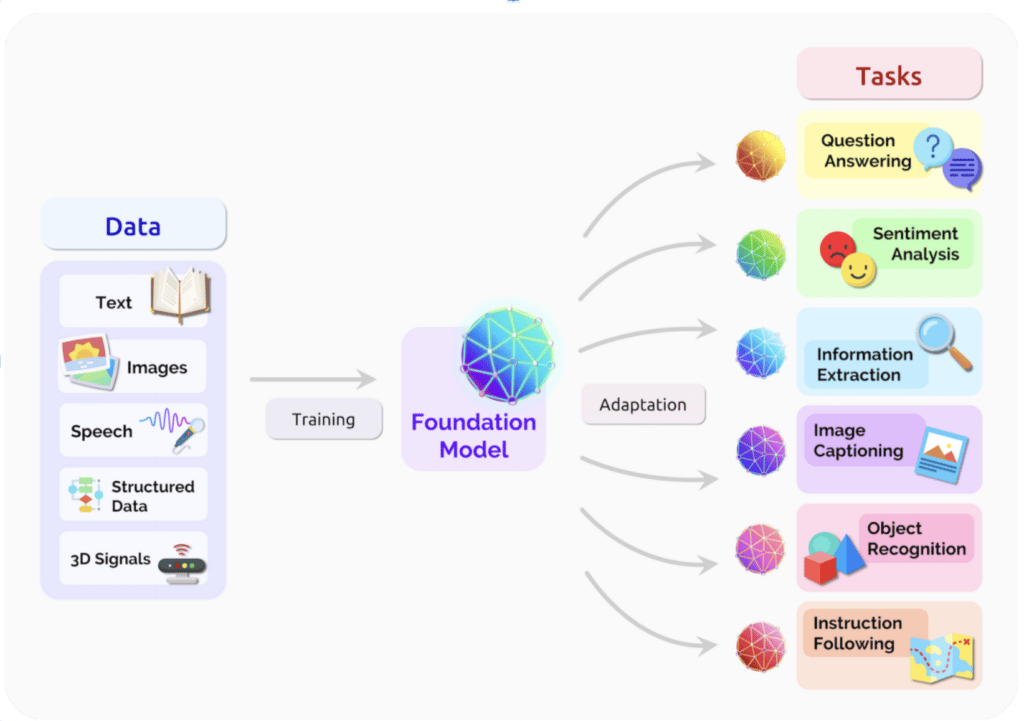
A large team of researchers at Stanford, including Snorkel co-foudner Christopher Ré, surveyed more than a thousand academic papers to produce this robust, 161-page report that investigates what the current wave of new, larger and more powerful foundation models could mean to the future of AI and society. The researchers concluded that these new developments represent a paradigm shift in AI which enables transfer learning and scale to be used to create powerful models capable of adapting to many downstream tasks.
The report provides an overview of the opportunities and risks of these models, including their capabilities, technical principles, applications, and societal impact. Homogenization is both a source of leverage and a potential risk, as the flaws of the foundation model can be inherited by all adapted models. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. The researchers concluded that deep interdisciplinary collaboration is needed to tackle these questions.
Contrastive Adapters for Foundation Model Group Robustness
Michael Zhang and Christopher Ré

Michael Zhang and Christopher Ré found that popular foundation models’ zero-shot classification abilities may not be robust to some group shifts “out-of-the-box,” and establishes that baseline linear probe and adapter strategies do not reliably improve that robustness. To solve this problem, the researchers propose a simple adapter training strategy called “contrastive adapting” to improve robustness without additional retraining.
Pretrained foundation models may not classify all groups correctly, but the information to classify groups frequently resides in their pretrained embeddings. Rather than training additional separate models, the researchers trained adapters with contrastive learning to nudge sample embeddings close to both their ground-truth class embeddings and others in the same class. This approach consistently improved robustness across nine benchmarks.
Language Models in the Loop: Incorporating Prompting into Weak Supervision
Ryan Smith, Jason A. Fries, Braden Hancock, Stephen H. Bach
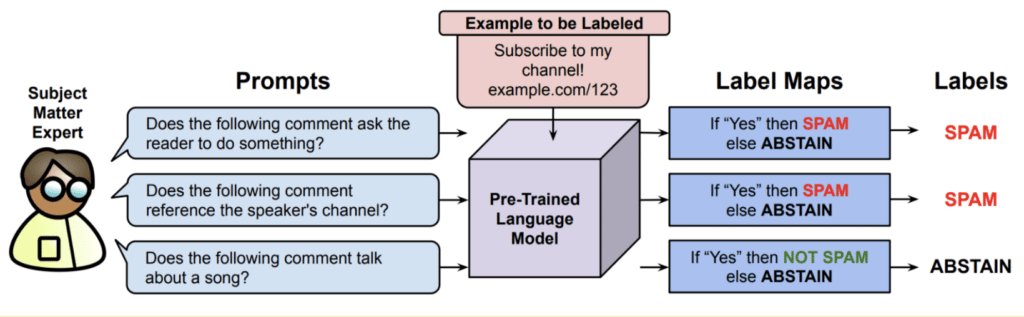
Snorkel researchers present a new framework for programmatic weak supervision that uses pre-trained language models to generate labeled training data. The authors propose expressing heuristic tasks as zero-shot prompts for the language model and using a label model to resolve conflicts between the different labels generated by these prompts.
Experiments show that prompting pre-trained models with multiple heuristic tasks can significantly outperform directly prompting the model to solve the task of interest, with an average improvement of 20.2 percent. Furthermore, translating labeling functions expressed as code into prompts can lead to significantly improved weakly supervised models, with an average improvement of 7.1 percent. These results suggest that large language models contain more useful information than can be easily accessed by a single prompt, and that combining multiple prompted labeling functions provides significant improvements over underspecified prompts commonly used for zero-shot classification.
Shoring Up the Foundations: Fusing Model Embeddings and Weak Supervision
Mayee F. Chen, Daniel Y. Fu, Dyah Adila, Michael Zhang, Frederic Sala, Kayvon Fatahalian, Christopher Ré
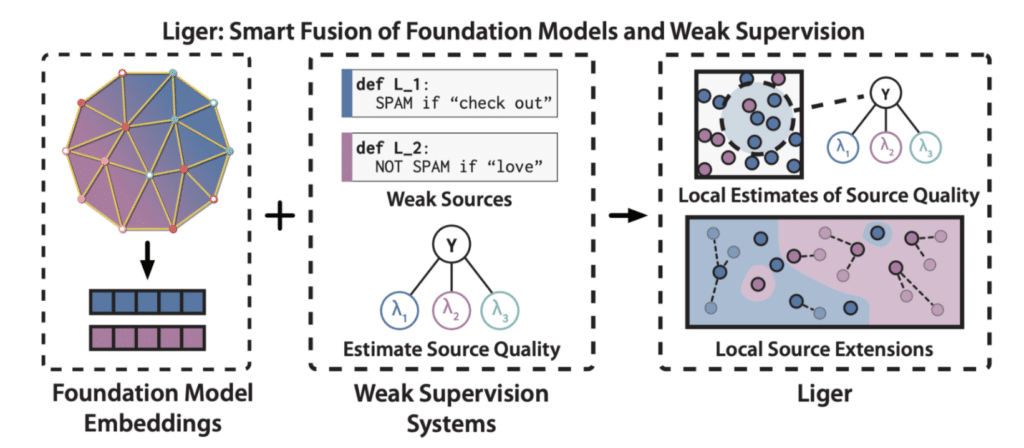
Researchers at Stanford and the University of Wisconsin-Madison (under the supervision of Snorkel co-founder Christopher Ré) examined a novel approach for combining foundation models and weak supervision techniques that the researchers call LIGER. Named after the offspring of a lion and a tiger, LIGER addresses two challenges in existing weak supervision approaches. It uses FM embeddings to produce more accurate estimates of source quality by dividing the embedding space and learning per-part source accuracies, as well as extending weak source votes into nearby regions of the embedding space to improve coverage.
LIGER outperformed traditional weak supervision, kNN and adapters supervised by traditional hand labels, and weakly-supervised kNN and adapters on six benchmark NLP and video weak supervision tasks.
Stay in the Know on Foundation Models
The world of data-centric AI moves fast. Soon, Snorkel and others will use the findings from the research papers above build new, more powerful applications using foundation models.
Join the Snorkel community by submitting your email below to keep up to date with the latest developments. You can also join us for a free virtual foundation model summit that will bring together speakers from Google, Cohere, Stability AI, Stanford, and more to discuss enterprise applications, best practices, and the latest research in the field of foundation models (FMs) and large language models (LLMs).

Matt Casey
Data Science Content Lead
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

