
Building a machine learning (ML) pipeline can be a challenging and time-consuming endeavor. Despite spending millions of dollars on AI initiatives, hiring top-tier and incredibly talented teams, and having historically unprecedented access to commercial and open-source tooling, only 1 out of 10 organizations generate significant business value from AI1. Most teams encounter one or more of the following challenges when trying to deploy and maintain AI applications:
- Developing models with production-grade quality is incredibly difficult or time-consuming. Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label.
- Large models can be difficult and expensive to serve, especially when experiencing spikes in demand.
- Inevitably concept and data drift over time cause degradation in a model’s performance. Determining when to retrain and how to do it efficiently can be difficult, often resulting in decommissioning previously trained models.
For an ML project to be successful, teams must build an end-to-end MLOps workflow that is scalable, auditable, and adaptable.
Snorkel AI provides a data-centric AI development platform for AI teams to unlock production-grade model quality and accelerate time-to-value for their investments. Seldon is a deployment solution that helps teams serve, monitor, explain, and manage their ML models in production. Together, Snorkel AI and Seldon enable enterprises to adopt AI across the business at scale by dramatically accelerating development and deployment and tightening the feedback loop to rapidly respond to data drift or changing business requirements. Both platforms facilitate more effective collaboration between data scientists and internal teams and enable greater auditability and governance across the ML lifecycle.
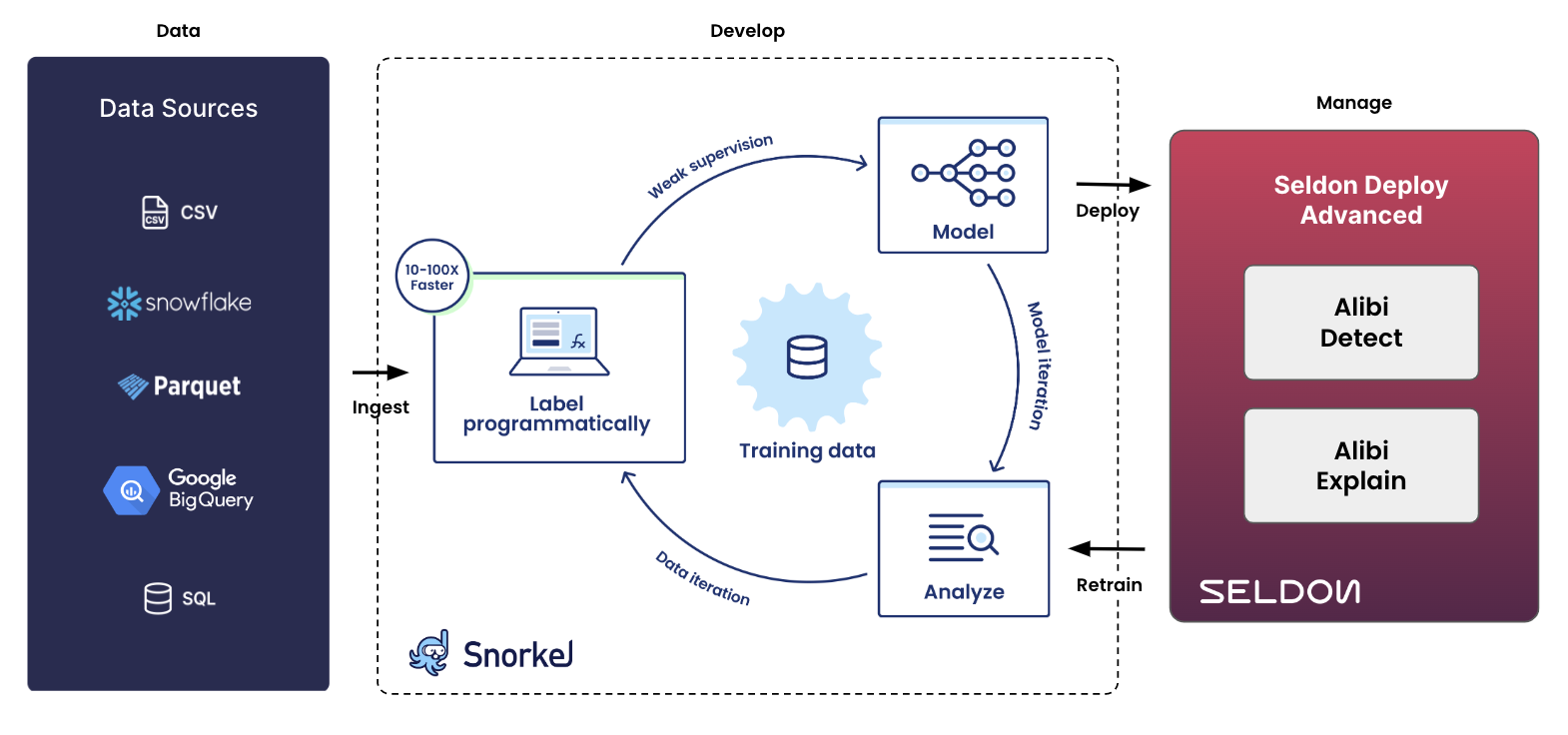
Data-centric approach to ML lifecycle using Snorkel Flow and Seldon Deploy Advanced
Model Development
Data collection and labeling is often the most time-consuming and labor-intensive part of building an AI application. Traditional data labeling methods require manual labeling by human annotators, which is slow, expensive, and prone to errors. Snorkel AI changes the paradigm with Snorkel Flow, a data-centric platform powered by state-of-the-art techniques including programmatic labeling, weak supervision, and foundation models.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently leverage various sources of supervision such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even foundation models like GPT-3, RoBERTa, and T5 and then scale it to label large quantities of data. Users are able to rapidly improve training data quality and model performance using integrated error analysis and model-guided feedback to develop highly accurate and adaptable AI applications.
AI applications created using Snorkel AI’s platform can be easily exported as MLflow models and packaged in a standardized way for deployment tools.
Model Deployment
Models are often deployed on Docker containers running on separate servers. Each new model adds complexity, and the model deployment challenges increase exponentially with multiple use cases and models. One of Snorkel AI’s banking customers, for example, has deployed 15 downstream applications to extract relevant information from a single data source: 10-Ks. 10-Ks contain a wealth of valuable information that can be relevant across a range of ML use cases from interest rate swaps to risk factor assessments to KYC initiatives. Even on the first production iteration, managing 15 separate models required complex traffic orchestration.
To extend the data-centric AI workflow through deployment, Snorkel AI is partnering with MLOps software innovator Seldon. Seldon provides a suite of tools, including MLServer, Seldon Core, and Deploy Advanced to handle model deployment.
MLServer is an open-source inference server that provides a simple and efficient way to create REST and gRPC endpoints on top of a serialized model artifact. This is a great way to get started, as MLFlow models can be easily Dockerized using MLServer and deployed anywhere. Seldon Core is an open-source model orchestration framework that allows you to deploy MLServer and Triton models at scale. It enables additional features like advanced inference graphs, A/B experiments, and simple monitoring. Like Snorkel Flow, Seldon is built on top of Kubernetes so is highly flexible and can be integrated with other tools and platforms.
As the number and complexity of deployments grows, a more robust and intuitive solution will be needed. Seldon Deploy Advanced is an enterprise product that makes it very easy for Data Scientists to deploy their models with best practices built-in, including monitoring, logging, alerts, and more.

Model Management
Simply having a model deployed covers the bare minimum of the MLOps lifecycle. Modern ML systems include the ability to discover models, monitor drift, explain predictions, and control who has access. Seldon Deploy Advanced provides advanced features around model monitoring, management, and governance to address these challenges. It provides a model metadata catalog that makes it easy to trace the lineage of model versions and to make them more discoverable. Seldon Deploy Advanced also provides peace of mind with role-based access controls (RBAC), as well as the ability to track and roll back to previous versions of your deployment. In addition, customers can leverage the expertise of the Seldon team, who can provide valuable guidance and support.
Seldon Deploy Advanced integrates with the Seldon Alibi Detect and Alibi Explain libraries, which provide advanced ML monitoring and interpretability. Alibi Detect enables data scientists to build drift detectors and outlier detectors which can be visualized in the UI. This works well when used alongside the feature distributions dashboard to drill down into why your mode’s performance is degrading. Alibi Explain provides a suite of explainability algorithms that work across tabular, text, and image data. One of these methods creates a set of rules that sufficiently “anchors” the prediction locally such that if the rules hold true, the prediction will be the same. These anchor explainers can be visualized in the Seldon Deploy Advanced UI to better understand why your model is behaving in a certain way.
In combination with Snorkel Flow, model governance can be extended upstream to the development process as well. Labeling data programmatically captures the original reasoning being labels, which is lost with manual labeling. Moreover, labeling functions and training dataset versioning improves transparency and auditablity, aiding model explainability and governance.
Model Iteration
As inference data is being collected and assessed, models may need to be re-trained in order to improve or maintain the same level of performance. All model requests are stored using Seldon Deploy Advanced, and can be easily fed back into Snorkel Flow. You can then add new labeling functions that account for data as it may have drifted over time and within minutes build an updated training dataset.
In order to further automate this machine learning iteration cycle, a CI/CD tool might make sense to trigger the deployment automatically. Once an MLFlow model has been saved to the registry, this could be automatically deployed as a shadow model using Seldon. A shadow model will receive real requests in the background and allow engineers to understand the performance before promoting it to become the default for serving requests. Further actions could be built to automatically pull in new data and retrain a model if it has drifted beyond a certain threshold.
What’s Next?
Together, Snorkel AI and Seldon enable enterprises to operationalize all of their data for AI and scale across the organization. This provides a seamless, modern, production-grade ML pipeline. Enterprises that are working with large, proprietary data sets and looking to deploy AI in production at scale with the ability to closely monitor and audit their deployments are well-positioned to benefit from this approach.
If this sounds interesting, please reach out to request a demo with a member of our team. In this session, we’ll be able to answer any questions you might have, tailor a demo, and find out if Seldon and Snorkel are right for you.
On Feb 23, Snorkel and Seldon are co-hosting a webinar showcasing the data-centric AI workflow to build an ML pipeline. We will label a dataset programmatically, train a model, serve it, set up monitoring, and create a feedback loop. Sign up for the webinar here.
References

Friea Berg
VP of Strategy
As VP of Strategy for Snorkel, Friea Berg leverages over a decade of channel experience to help the world’s most innovative enterprises realize the promise of AI using proprietary data. Friea joined Snorkel to build the startup’s channel strategy from the ground up. Under her leadership, Snorkel has built successful partnerships with Google, Microsoft, AWS, Databricks, Snowflake, and Hugging Face plus unlocked new routes-to-market via Marketplace and global resellers. Partners are now integral to every team at Snorkel, one of CRN’s 10 Hottest Data Science/ML Startups in 2022 and one of Forbes’s 50 most promising AI startups in the world in 2023.
Prior to diving into startups, Friea held leadership, alliance, and business development positions at Splunk, NetApp, and other technology leaders. At Splunk she built and scaled global strategic partnerships with Google, Cisco, and Palo Alto Networks. She also led a team that incubated first-of-a-kind ‘market maker’ partnerships with Deloitte, SAP, Cerner, Salesforce, and others.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

