Building NLP techniques to understand 10-Ks is time-consuming, costly, and challenging. In this post, Machine Learning Engineer, Aarti Bagul discusses three information extraction case studies on how banks around the world are building highly accurate NLP applications using Snorkel Flow’s AI platform. From retail banking to hedge fund investing, NLP is used across the financial industry. By processing and extracting data from unstructured documents, such as 10-K reports, legal contracts, credit reports, and many other types, NLP techniques help financial institutions make informed decisions.
What are 10-Ks?
10-Ks are financial documents that every public company must file with the Securities and Exchange Commission (SEC) every year. They contain a wealth of information about the companies who file them: what the company does; their location; their key senior managers; their board of directors; their financial statements; etc. All of this information can be very valuable for a lot of downstream analyses and tasks.
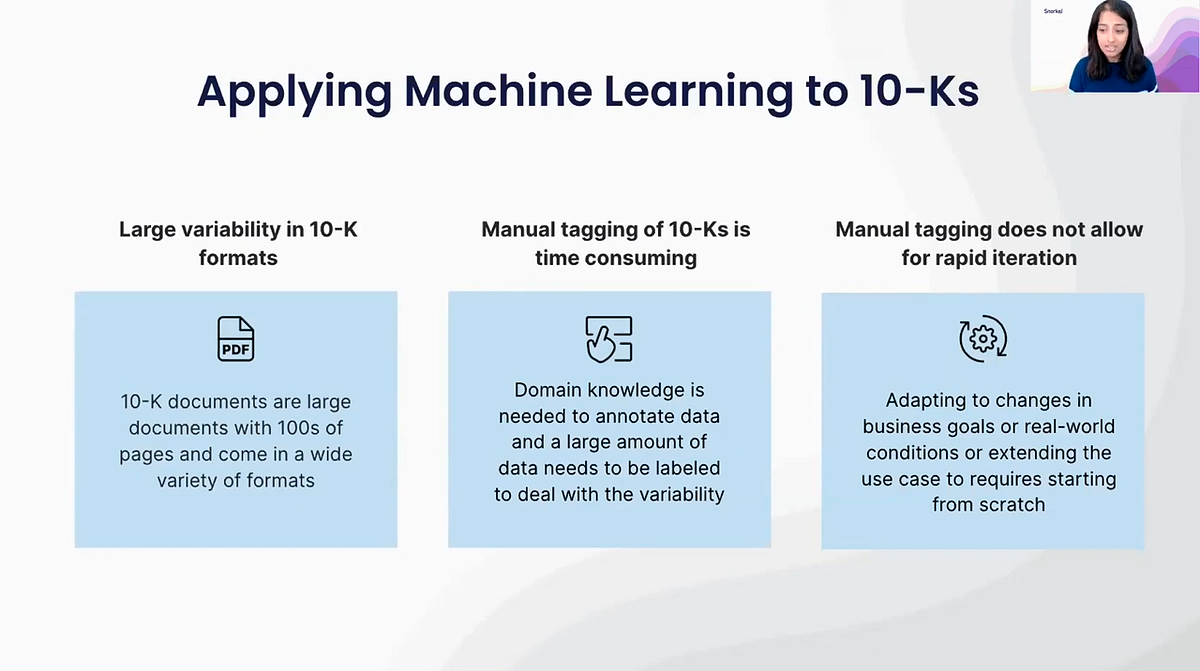
However, there is no standard template for 10-Ks. They come in a wide variety of formats and are generally pretty substantial documents — often from 100 to 300 pages.
Without standardization, that sort of document is quite challenging for machine learning because:
- It requires a large amount of data before a machine-learning model can be trained effectively.
- Many use-cases require sophisticated domain knowledge. If you must label your data manually, you will probably need subject-matter experts (SMEs) to do the work. This becomes expensive for an organization and burdensome for SMEs, who also have day jobs.
- Manually labeling large datasets is slow and time-consuming and so does not allow for rapid iteration. If you want to analyze a new kind of 10-K format or even simply extend the use-case, you already have to include more information, you need to effectively label everything again from scratch.
Each of these challenges can be efficiently addressed using the platform we have created, Snorkel Flow.
Examples for information extraction use cases
- Extracting Interest Rate Swaps
- Extracting “Know-Your-Customer” (KYC) Data
- Extracting Risk Factors
Case study 1: Extracting interest rate swaps

Why are interest rate swaps an important use case? These rate swaps represent the largest component of the global over-the-counter (OTC) derivatives market, and they are a very large notional amount. At Snorkel we worked with a top-3 U.S. bank that wanted to extract this data from 10-Ks, and in this case, the notional amount outstanding was $372 trillion, making it twenty-five-times the size of the U.S. public equities market. Needless to say, interest rate swaps are a critically important product category for a bank.
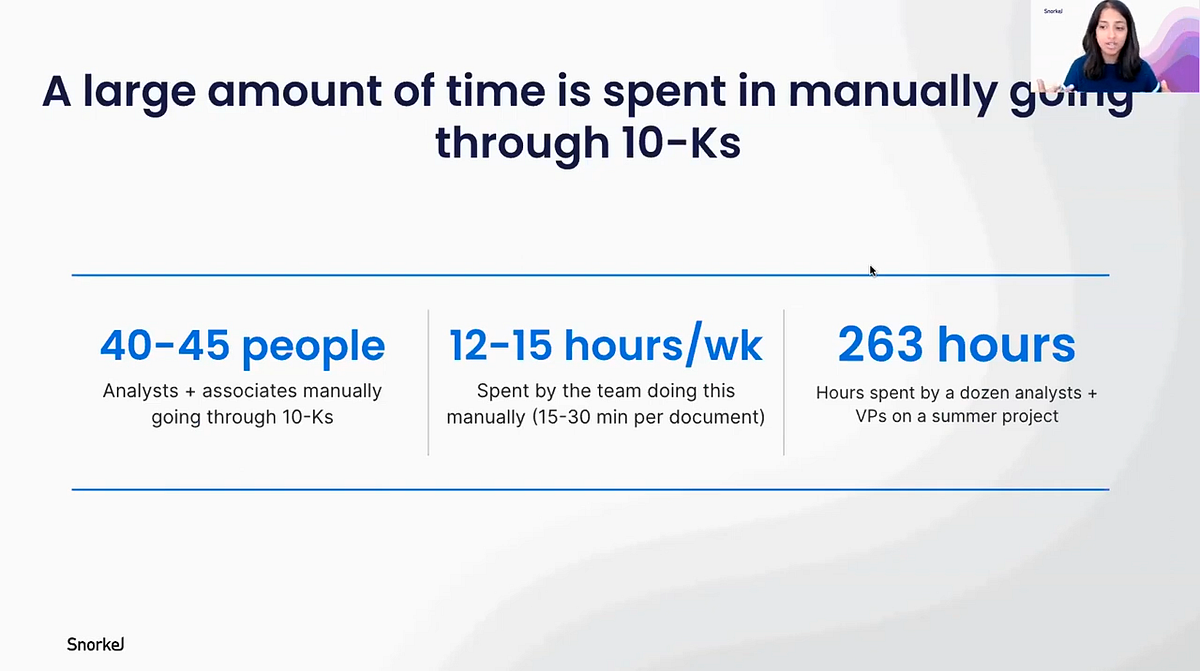
Interest rate swap information is only filed in 10-Ks, if teams want to influence their selling strategy or get information about, for example, what interest rate swaps a company has already undertaken, they have to manually go through and review 10-Ks to find the information. In our customer’s case, this process required 40–45 analysts, working 12–15 hours per week. In one instance, it took a dozen analysts and others 263 total hours just for one project.
This clearly seems like something ripe for machine automation, but, as mentioned above, there are significant challenges to overcome.

One challenge, as we mentioned, is the variability of 10-K formats. The interest rate swap amount might occur in a table as a notional amount. It might be broken down by years or by quarters. Those tables themselves vary between documents. For instance, the number of columns may vary. The interest rate swap might also occur in a text paragraph, stating that the company entered into an interest rate swap and the amount, or it might be split into multiple separate amounts or even the quarters during which the swaps were undertaken.

In order to deploy machine learning effectively for this task, you need to label a large amount of data. If you have to do this manually, you need your SMEs to go through each document to find the interest rate swap that you want to extract. In the specific use case that we will be exploring here, we ended up labeling about 70,000 data points. Doing this internally, by hand, would be very slow and require a lot of resources. There are also opportunity costs. For example, you must take your SMEs — in this case, traders — away from interacting with clients and have them label data instead. It simply is not a very helpful use of their time.
Moreover, once you have labeled all those data points, it is difficult to adapt the dataset if you want to make any changes. Let’s say, for instance, a new variation of the available data labels comes up, or you want to extend the data to include a different swap amount or a different entity. If you have done your labeling manually, you have to start from scratch.
K-10s are public documents, but most financial documents are confidential. So, the need to maintain data privacy also presents a challenge for traditional machine learning. You can’t simply send your data out to be labeled externally by a third-party vendor. It needs to be done in-house.
Snorkel’s approach: Programmatic labeling
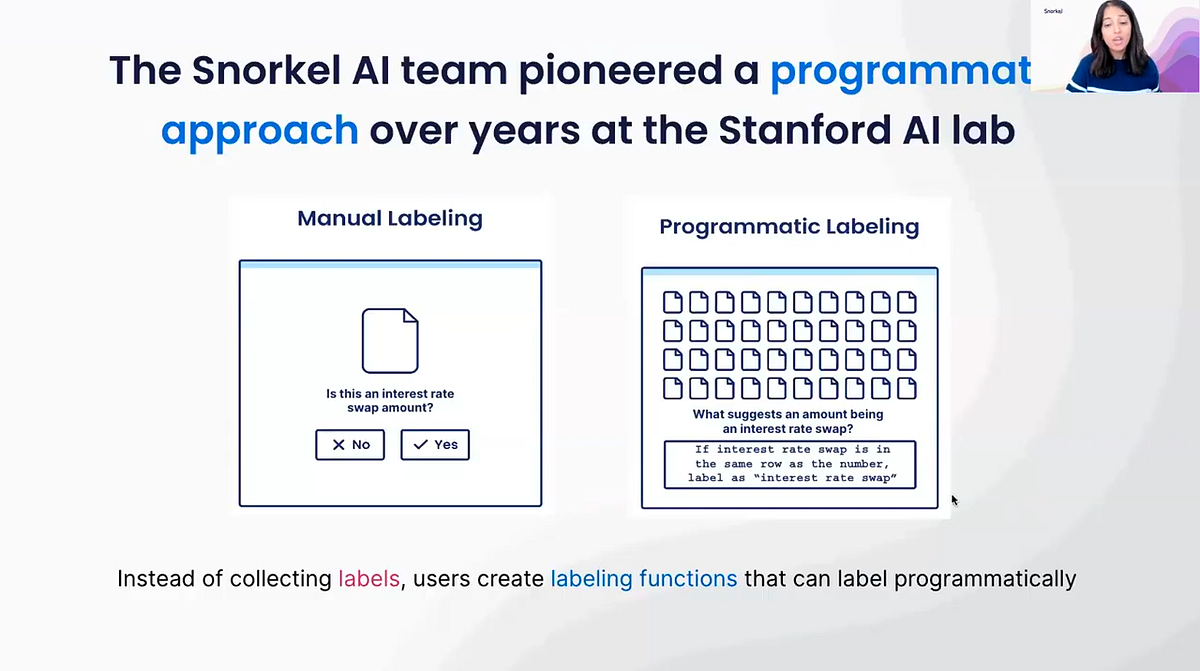
Snorkel tackles these machine-learning challenges using an approach we pioneered called programmatic labeling.
The core idea is that if you can label data programmatically, instead of manually, one point at a time, you can save a vast amount of time in your labeling task while also making your datasets more accurate and extremely flexible. Instead of laboriously locating each amount that appears in a document and asking, “is this an interest rate swap amount or not?” — in other words, selecting each interest rate swap manually — you can instead specify a rationale for why you think something is an interest rate swap via a labeling function.
Snorkel Flow uses labeling functions because they allow you to establish rules in order to extract the interest rate swap amounts you want far more quickly. If you know, for example, the term “interest rate swap” is usually in the same row as the number, then that corresponding number is likely the interest rate swap amount. The labeling function will label that programmatically, without any need for a human to find it manually. Programmatic labeling enables you to label large amounts of data all at once.
As mentioned, because the 10-Ks that hold this information come in all kinds of different formats, this labeling function may not be very precise at first. But that’s ok. With Snorkel Flow, the labeling functions don’t have to be perfect. Snorkel can de-noise them for you to resolve any conflicts and get you to one label per training-data point.
Examples of labeling functions:

With Snorkel’s GUI-based interface, even non-technical people can write these labeling functions. If, for instance, we wanted to say that a particular amount is an interest rate swap, how do we know that? If the amount is to the left or the right of the word “notional,” and it is to the left or the right of the words “interest rate” or “swaps,” then we can label it as an interest rate swap. Using this rubric, this particular function will then be able to label a lot of numbers all at once instead of one at a time.

Here is an example of a table. How do I know that all of these numbers are not interest rate swaps? With a labeling function, I can say, “if what is in the same line as this number is the word ‘currency,’ or ‘foreign exchange,’ or ‘carrying value adjustment,’ then it is a swap.” You might ask, how do you define the “other” class? In Snorkel Flow, you can write functions for “other” as well.
With this process, you will be able to write initial functions that cover large portions of your data, and then — because they will inherently be imprecise at first — Snorkel Flow can de-noise these imperfect functions until you get to one label per training data-point.
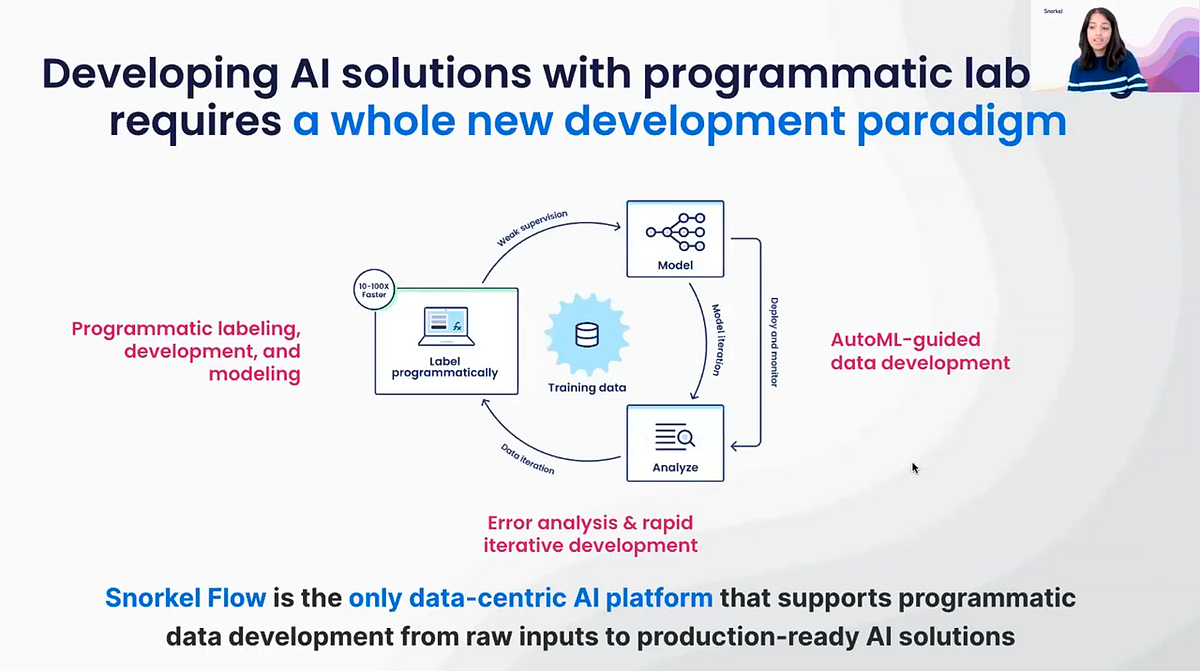
Snorkel has built an end-to-end platform that supports the rest of the workflow around this programmatic labeling approach. The process generally tends to be 10 to 100 times faster than manual labeling.
Once you have a labeled dataset, you can then feed it into one of several powerful machine-learning models that already exist. The model may be able to generalize beyond your labeling functions because there may be other signals in the data that the model can pick up on. You can train the model inside or outside the Snorkel Flow platform. After you train the model on your data, Snorkel has built-in error analysis tools that tell you how you can improve your model and results.
Iteration traditionally tends to be a very ad hoc process — throw in different models, throw in different hyper-parameters, etc. But with Snorkel Flow, you receive concrete tools to perform more systematic error analysis. This can help answer questions like: Where is your model already going well beyond the labeling functions? Where is the next iteration target? Should you be iterating on the model? Should you be iterating on the data? If so, what part of the data?
This is the power of data-centric AI. Instead of simply iterating on your models, iterating on your data actually produces larger gains in performance. Snorkel productizes this and makes it concrete in our platform, such that with our analysis tools you can quickly determine which specific parts of your data your model performs poorly. Then you can write new labeling functions for that portion of data.

Another benefit of Snorkel is we enable you to utilize text without losing useful signals. If you take a 10-K and need to look at the raw text, it can destroy a lot of the signal that is important for writing labeling functions or even training a model. Snorkel Flow preserves the formatting information in the raw text of a document, such as a 10-K. So, rather than simply telling you that something occurs in the document, it can tell you where it occurs as well. What page is it on? What is the font? What else is in the same line? Is it at the top, right, left, or bottom? All of these aspects can be used to write new labeling functions.
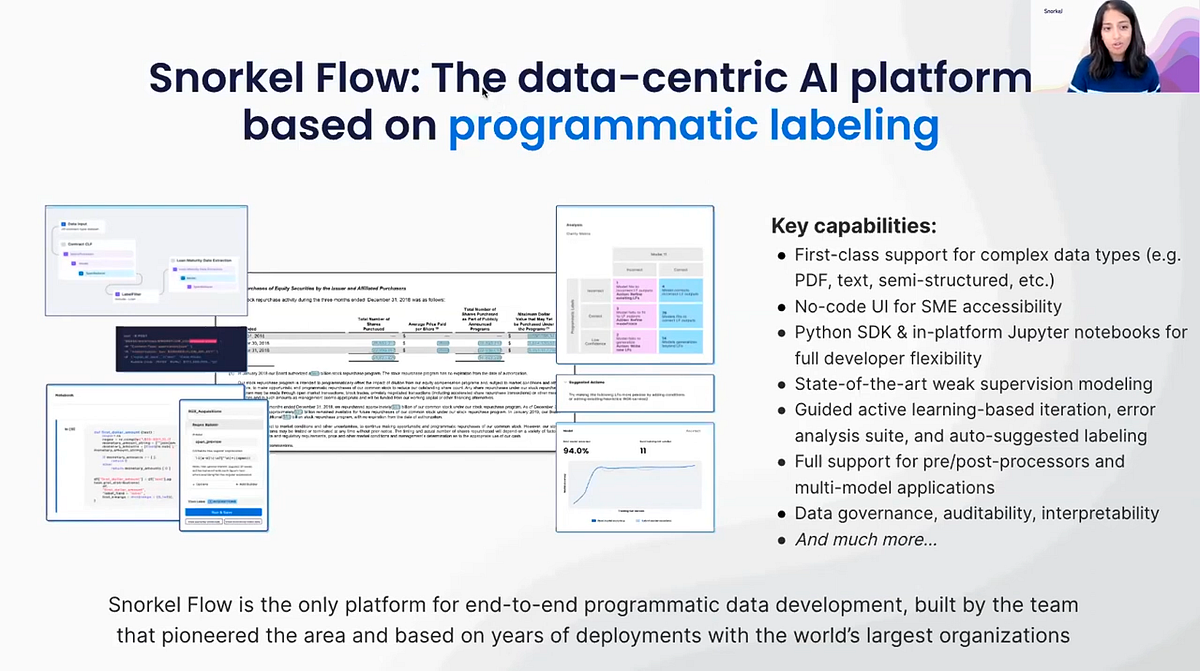
Snorkel, then, is an end-to-end, unified data-centric AI platform based on this core idea of programmatic labeling. But it also has a number of key capabilities that allow it to perform really well on structured data extraction tasks. This includes first-class support for complex data types like PDFs and semi-structured data; no-code user interfaces that really help integrate your SMEs’ expertise into a project; and many others laid out in the slide above. This suite of capabilities and functionality really empowers users to be adaptable and to achieve accurate, trustworthy AI results in a much more time- and resource-efficient way.
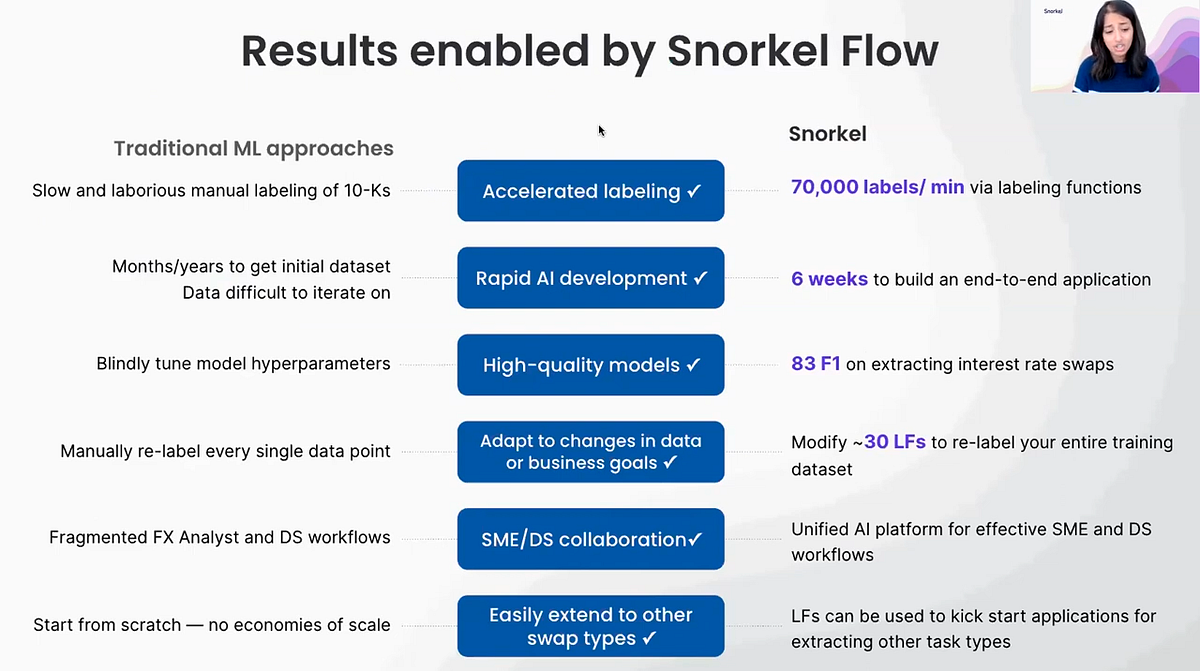
What are the benefits of using Snorkel Flow?
- Instead of a slow manual labeling process in which data points receive labels one at a time, Snorkel Flow’s programmatic approach can produce 70,000 labels per minute via labeling functions.
- Instead of spending months or even years to get an initial dataset, Snorkel Flow can help you build an end-to-end application in six weeks. In that time, you get a high-quality model that allows for rapid iteration on both the model and the data.
- Because of the ability to rapidly iterate, Snorkel Flow makes your dataset and model highly adaptable to changing circumstances or business goals over time. Rather than start a new dataset from scratch using new labels or new classes of data, in other words, you can simply iterate on the one you already have just by modifying your labeling functions.
- Instead of fragmented workflows between data scientists and your SMEs, Snorkel Flow enables continuous collaboration between these two groups via a feedback loop, allowing you to take full advantage of SME domain knowledge in much less time.
- Labeling functions can be used to start new projects. Rather than starting from scratch, Snorkel Flow allows you to get a head start on, for instance, extracting a different type of swap amount or extending your current task to new entities you may want to extract. This introduces an economy of scale that is just not possible with traditional machine-learning approaches.
Snorkel Flow saves time for SMEs

Here is a more concrete example of how SMEs can really use the output of the model in Snorkel Flow. This is just one way to present the data, and Snorkel can work with customers on different ways to do so based on their specific needs.
In this case, instead of having to go through a 300-page 10-K to find the interest rate swap amount, Snorkel has made it so that traders can simply look at a table that gives them: the name of the company, the swap value extracted by the model, a short excerpt surrounding that swap amount so that traders can quickly verify the information is correct, the confidence the model has in its prediction, and finally, a link to the specific page on which the amount appears, highlighted with context for further SME verification.
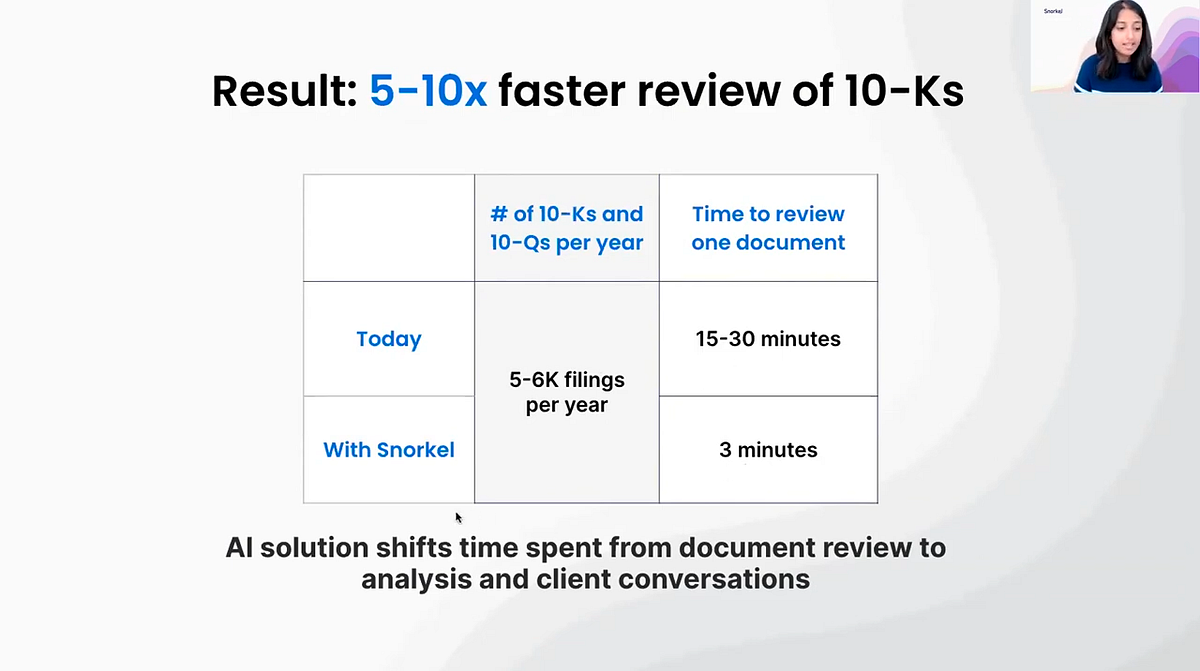
Instead of taking 30 minutes to scan through the 10-K yourself, this may simply take a moment or two. If the model’s confidence level is not quite high enough, you have the information in front of you to make a quick review. Your team can then spend the bulk of its time on their actual duties.

Case study 2: KYC attribute extraction

“KYC” stands for “know your customers,” and for one top-three U.S. bank that Snorkel worked with, they had as many as 500 analysts manually searching through 10-Ks to extract simple attributes such as: Where is the company located? What is the nature of their business? Who is on the board of directors? What are the company’s total assets? Etc. Just to extract that kind of information, they spent between 30 and 90 minutes manually reviewing a given 10-K, looking at more than 10,000 of them per year.
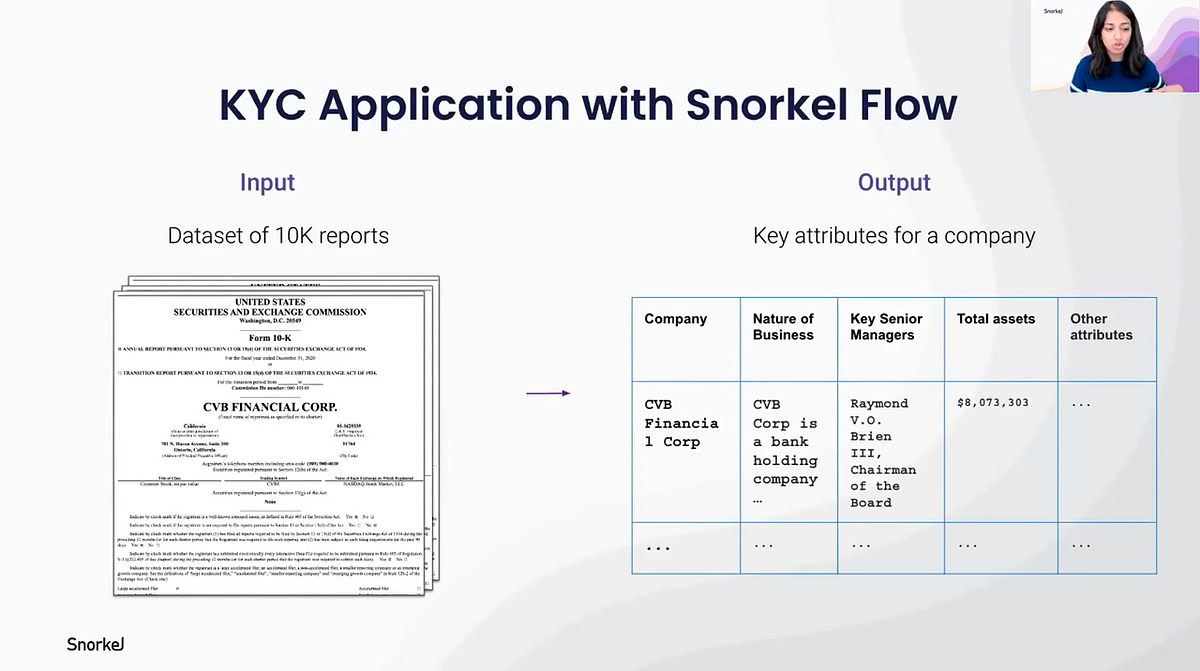
Using Snorkel Flow, they are now using an application that says, given a specific 10-K, what are 15 to 20 key attributes of that company — senior managers, assets, etc.

Snorkel flow does this quickly and accurately with its use of labeling functions. In this particular case, the bank was able to save 10,000 person-hours per year with just this relatively straightforward application of our platform.
Case study 3: Risk factor extraction:

So far we have shown you extractions of particular entities, such as amounts, locations, names, etc. But with Snorkel Flow you can also build applications to extract sentences or paragraphs from any document — in this case, a 10-K.
The use-case that our banking customer wanted to address was, again, a large unstructured 10-K that can be expressed with a structured output and that presented the text that is associated with certain kinds of legal or regulatory risk. Using Snorkel Flow, we were able to use labeling functions to extract those passages from the unstructured document and present them in a table as you see above.
Why would a company want that information?
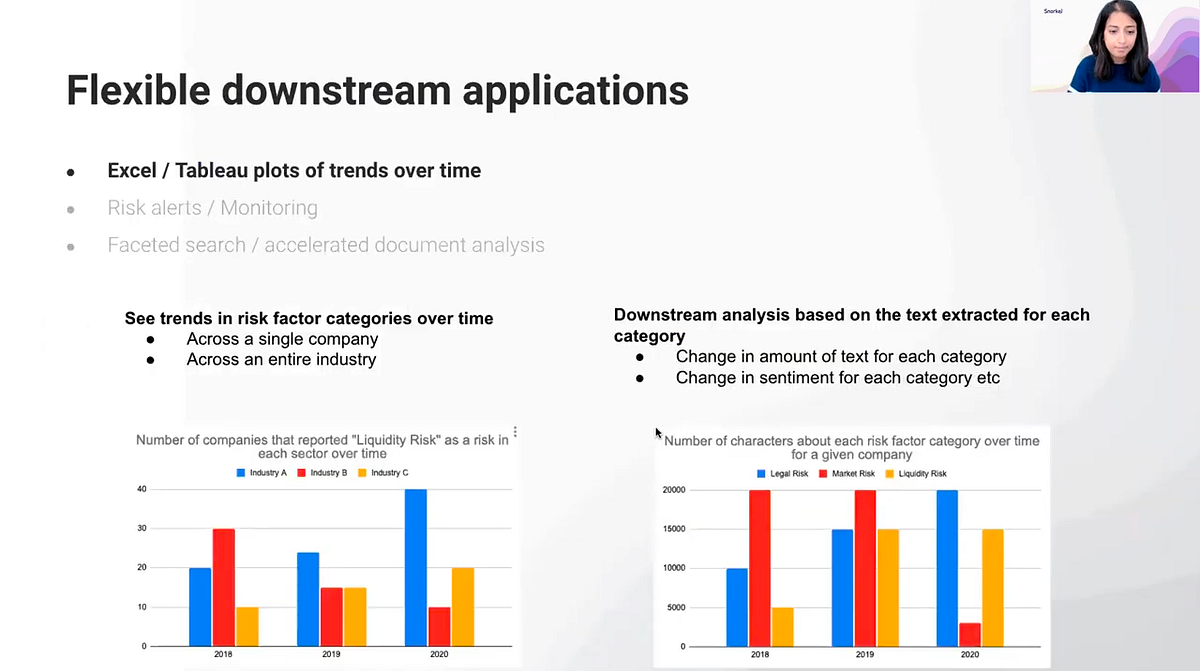
For one, these extracted risk-factor paragraphs offer several flexible downstream applications.
Once you take a large unstructured piece of text and put it in a structured format, for example, it becomes much easier to start seeing trends across customers, companies, and industries. You can bring these risk factor paragraphs to a single place and find trends in risk factors for a given industry or company over time.

Second, risk factors presented in a structured way allows for risk alerts and much more effective monitoring. Perhaps, if a particular risk factor shows up in a company’s 10-K that was not there in previous years, it might be something you want to flag for investment analysts down the line.

Thirdly, having extracted these risk factors greatly accelerates the review of large documents. You can use the output to very quickly jump to relevant parts of the document so that analysis and investment decisions are thus made much quicker as well.
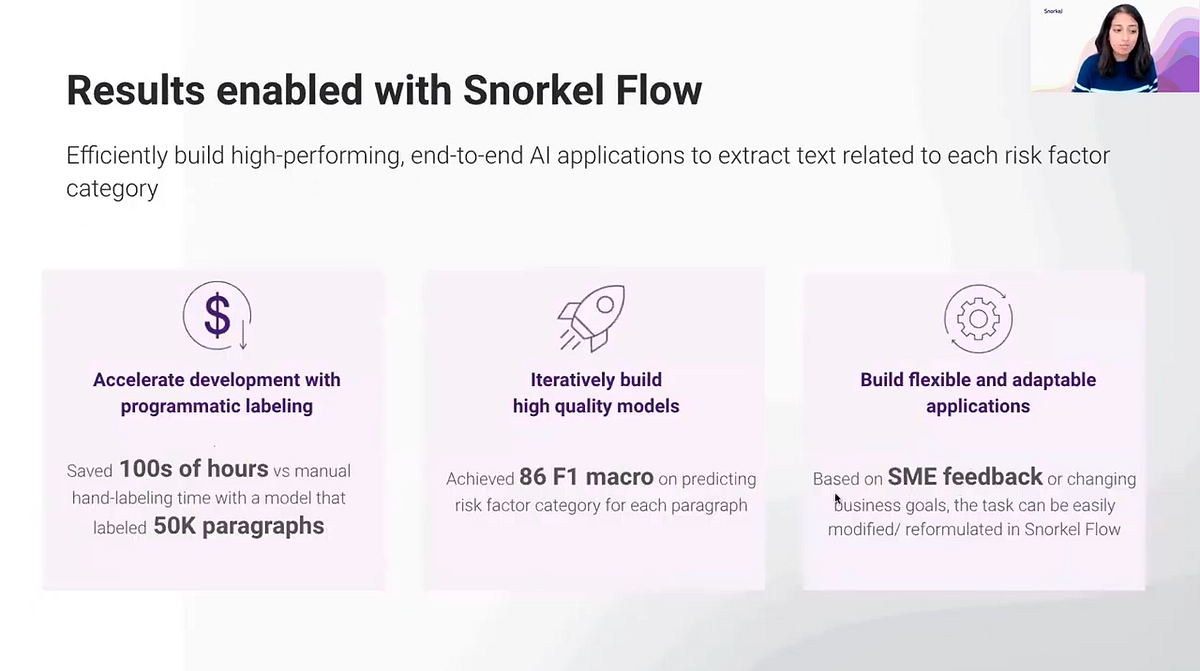
If a company were to do this manually — that is, reading through 50,000 10-Ks to find 50,000 paragraphs that define risk factors — it would take a really long time. Using Snorkel Flow’s programmatic approach, however, we were able to save our customers hundreds of hours and then leave them with an application that is resilient and eminently adaptable to changes in data needs or business goals.

We have highlighted only three use cases in which Snorkel’s data-centric AI platform saved a company a lot of money and time by creating a “smart” document in which meaningful information or insights were extracted via labeling functions and programmatic labeling. But this only scratches the surface of the possibilities and opportunities for machine learning in financial services. The potential is there for the extraction of additional meaningful information from news analytics, conversational analytics, and a wide variety of other use-cases that Snorkel supports in our platform.
Q&A
Does [rich docs] work over scanned images of documents?
Yes. Snorkel Flow handles both scanned and native PDFs, and we can convert that into our internal format.
What is your de-noising process? Is it a “human-in-the-loop” approach?
As we mentioned above, we help you write these labeling functions, which inject your SME expertise and let you label a large amount of data all at once. But these labeling functions can be imprecise and even conflict. How do you de-noise them to get to one label per training data point?
Say, for a given document or a given number, three of your labeling functions say “this is an interest rate swap” and two of them say it is not, how do you decide on a label? One way to do this is a simple majority vote. If most of the functions say it is a swap amount, then you simply go with that decision. But Snorkel does something much more sophisticated on the back end. Even without any ground truth, Snorkel can de-noise these disagreements and use that to automatically figure out the weighting for each labeling function. If you *do* have some ground truth, Snorkel takes that into account as well.
The de-noising process is entirely done “under the hood.” You just need to specify the functions. You can also tell us which functions you trust more or less. But the de-noising itself is automatic.
What is the desirable size for a training dataset for programmatic labeling to be effective?
One primary benefit of programmatic labeling is you can work with an extremely large dataset because you just need to write labeling functions.
Snorkel does evaluate on ground truth, internally, in Snorkel Flow, just to follow best practices. So for that, we do recommend having a small validation or test set that is hand-labeled in Snorkel Flow. We have hand-annotation capabilities too.
But for large training datasets, you simply are not limited. Labeling functions can be applied to sets that have hundreds of thousands or millions of data points, and you can just keep adding more documents and Snorkel will apply the functions and de-noise them for you. You may eventually begin seeing diminishing returns on performance. But that is also something Snorkel can help with. You’re not bounded by dataset size in any way because of our new approach.
Are Python notebooks supported in Snorkel? What is the difference between the Snorkel open source and what Snorkel Flow does as presented above?
Each instance of Snorkel Flow comes with a notebook interface, like a Jupyter notebook, and we have our own Python SDK that gives you a lot of flexibility on top of the GUI that is already in the platform. You can write your own custom labeling functions, custom operators, and custom models. It is extremely flexible as a development platform.
In terms of the open-source, everything presented above is in the Snorkel Flow platform. The open-source was what you can think of as our research code that our founders put out and that has been in maintenance mode since 2017. It is essentially a Python library to be able to write these functions and de-noise them. But the entire suite of capabilities that we present above — writing labeling functions in the GUI, iterating on them, training a model, then analyzing the model and completing the whole loop, is only available in Snorkel Flow.
More specifically, in the 10-K use-case examples above, having this rich-doc format — which preserves formatting and gives you additional information per attribute — this entire workflow centered around iterating on PDFs and the GUI-based interface is in the Snorkel Flow platform.
For those who are interested, our founder Alex Ratner has a webinar on our YouTube channel about our open-source DNA and how Snorkel has progressed from that point, and there is also a blog post on our website that gives you a feature-by-feature comparison of how Snorkel Flow has evolved from our early roots. It is called “Advancing Snorkel Flow from Research to Production.”
In the rate-swap use case, who is writing the labeling functions, Snorkel engineers or bank engineers?
Domain experts generally are the ones who need to tell you, in the examples above, what makes something an interest rate swap. Different companies prefer different workflows. You could have SMEs write these labeling functions, but generally SMEs can also talk to the data scientists about what they are looking for in identifying an interest-rate swap, and it is the data scientists who encode it. It really depends on your team. Bu yes, Snorkel Flow offers a more efficient way to capture SME expertise, and they are able to work on the platform if they choose via the GUI.
Why don’t companies just write their 10-Ks in a structured format?
Really, 10-Ks are documents that companies put out and there is no set format for them. We don’t have any control over how they are formatted. But we can offer a way to take a large unstructured document that you can quickly parse through and extract relevant or useful information about that company.
Are large language models used for the ML models for weak supervision? How are heuristics assigned for programmatic labeling?
You can use language models in various different ways. We have an excellent blog post on our website from one of our research team members using zero-shot learning algorithms to come up with labeling functions. Labeling functions that use language models can look at cosigned similarities between embeddings, for example, to come up with labeling functions for a particular task.
You can pre-process your data in any way, using for instance Spacey or a BERT model, etc., and use that to write your labeling functions. They can be as simple as a keyword-based function — e.g. If an email has the words “wire transfer” in it, it is probably spam — all the way to far more complex labeling functions that use large language models.
The main idea in using our programmatic labeling approach is that you are injecting your SME expertise into your labeling task in a far more efficient way than with manual labeling. That is what the functions are designed to do: ask why are you labeling something in a particular class and encode that, either as a simple keyword or something far more complex as in an existing model. There are some very powerful machine-learning models out there nowadays and given a training dataset they may be able to generalize beyond the models. So, once we label data, we also use powerful push-button models to generalize beyond the function.
How can we make 10-Ks using generative methods?
10-Ks are documents that companies are putting out already, and the goal is to extract insights from them or turn that unstructured content into structured data very quickly. Then we can hopefully see trends across companies and customers can make more informed decisions about investments. This information is sort of already out there in the “void,” so to speak, but it is not very actionable as it is formatted. That is the use case we are primarily tackling in our post above.
Do labeling functions work best if they are uncorrelated with each other?
Snorkel handles correlations as well. Generally, you can simply drop your subject matter expertise and ideally they are uncorrelated. But you don’t need to worry about it if they are correlated. Snorkel Flow resolves conflicts and correlations automatically.
Without any labeled data, how do you measure recall and precision?
When you get started with Snorkel Flow and get your initial training dataset, you don’t actually need any ground truth. We can resolve the various functions into one label per training data point, and we can also estimate the precision for you. Even if we don’t know what the ground truth is, if your functions overlap certain amounts and there are some theoretical criteria around the level of overlap, you just need at least three labeling functions. Based on the set in which they overlap, Snorkel can see how often these functions agree or disagree with each other and estimate the precision.
In practice, a lot of customers do start with a small amount of ground truth, just to iterate quickly, and we can also auto-generate labeling functions for you at that point.
In terms of calculating the final model performance, we do recommend evaluating on ground truth, but you can think of the final evaluation set as much smaller. Let’s say, for instance, for our classification task you may have a hundred documents in your validations, compared to a hundred thousand or a million in your training set. So in the name of best practices, we do recommend you evaluate based on ground truth so you can feel confident in your model’s performance.
How do you define a risk factor? How would the model react when it comes across a completely new risk?
It really depends on the company and how they want to formulate the task. In the case above, a bank wanted to see if they could simply extract text related to a particular risk factor. One of the sections in a 10-K is often called “risk factors.” So while a 10-K does have a standard list of sections, they are formatted in all sorts of different ways. Companies are obligated to disclose those risk factors the company may be facing, and the goal was to take that section and do a more granular analysis as to the type of risk.
In our use case, the team was interested in three different types. But you can imagine these can be extended to many different types. Our use case is not exhaustive. In fact, often, one of the categories is simply “other.” And so, when the model comes across a new type of risk or one that does not fit in one of the three categories, it will categorize it as “other.” What you can do, though, is now monitor the amount of “other” risk over time and see if you need to define a new class for a new, commonly occurring risk.
Oftentimes the interest rate swap information in a 10-K is duplicated in the text multiple times. They also give information about historical and/or terminated contracts. How does Snorkel Flow deal with that?
It is true that the number often appears multiple times, and it is something you may want to resolve. But we would consider this a step for after the application is built. Really, step one is: extract the interest rate swaps for a company. Then, downstream applications we can build on top of that can classify whether the swap is a “fixed-to-floating” or a “floating-to-fixed” type-swap to use the two common subcategories.
You will be able to see if the extracted amounts are the same, or if they occur in the same sentence or the same table, and you can pre-process the data to resolve duplicates. Or you can just train further downstream models to perform additional tasks and resolve issues.
Bio: Aarti Bagul is a machine-learning engineer at Snorkel AI, where she works with organizations across banking, healthcare, and government to enable them to solve complex ML problems with the Snorkel Flow platform. Before Snorkel, Aarti worked closely with Andrew Ng at AI Fund, where she helped build and invest in ML companies, as well as at Ng’s startup Landing AI, where she was also a machine-learning engineer. She holds a master’s degree in computer science from Stanford University and a bachelor’s degree in computer science and engineering from New York University.
Interested to learn more about Snorkel Flow? Sign up for a demo and follow Snorkel AI on Linkedin, Twitter, and Youtube.
