Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Machine learning on Kubernetes: wisdom learned at Snorkel AI
Here at Snorkel AI, we devote our time to building and maintaining our machine-learning development platform, Snorkel Flow. Snorkel Flow handles intense machine learning workloads, and we’ve built our infrastructure on a foundation of Kubernetes—which was not designed with machine learning in mind.
Of course, no standardized platform is perfect for any specific application. We chose Kubernetes because it provided the scalability, resilience, and standardization needed for our deployments with enterprise customers. Planning our code to take advantage of all Kubernetes has to offer took work, but we are willing and able to engage deeply with the challenges that come with technologies we really like.
Below are some lessons we’ve learned along the way. If you’re new to Kubernetes, see our Introduction to Kubernetes post to learn more about the basics.
The benefits of using Kubernetes for ML training
Despite the challenges we faced building architecture around Kubernetes, there are three big reasons we used it: containerization, scalability, and infrastructure standardization.
Scaling gets first-class support in Kubernetes. This unlocks scaling for training and experimentation as well. Spark, Dask, and any other workflow executors used for experimentation can grow along with the size of the cluster. ML engineers and data scientists can also kick off a large number of experiments at the same time—arbitrarily large, up to the cluster’s maximum size.
Containerization, despite being cumbersome for fast iteration (requiring build, push, and apply steps), provides consistent, reproducible behavior required for ML workloads. Reproducibility is important in ML. It means you can probably and consistently get the same results from the same set of inputs (datasets, model type, etc.). This was previously difficult to accomplish from ad-hoc pip installs and scripting.
Kubernetes is now the standard orchestration platform for the vast majority of enterprise customers we see at Snorkel AI. Building Snorkel Flow natively on top of Kubernetes unlocks our ability to deliver software on-prem scalably across a variety of different enterprises, regardless of company size and vertical. Our ability to deploy on-prem with Kubernetes ensures that customer privacy and security are a top priority and that no data leaves their premises.
Run a distributed workflow orchestrator as the backbone
Snorkel Flow runs large preprocessing jobs as part of the application development workflow. These jobs can include extracting features from rich documents, converting unstructured data into standard formats, running models to generate embeddings, and filtering out rows with custom logic. These processes can execute against hundreds of gigabytes to terabytes of data, and we want them to run as quickly and reliably as possible.
In order to take advantage of the large, distributed workloads that Kubernetes enables, we run a distributed workflow orchestrator as a backbone for these jobs.
At Snorkel, we primarily use Ray. Ray does the bulk of data processing for Snorkel Flow, performing transformations and other operations over large dataframes.

Leveraging Ray allows us to parallelize work at large scale across multiple worker pods in the cluster, and achieve our performance benchmarks while executing multiple jobs at once. We’ve also built in autoscaling functionality for Ray based on job queue size—our Ray stack has the ability to scale up and down based on the job load of the platform, and dynamically attach resources like GPUs. It scales up the number of Ray workers during periods of heavy ML application development and processing and scales them down during periods of low platform usage to save on compute spend.
Implement job checkpointing
Kubernetes embraces chaos by design. It constantly spins up and tears down nodes and pods, and Kubernetes expects the services running on it to be able to deal with this level of interruption and churn.
Simple horizontally scaled microservices are generally resilient to this, but ML development workloads are stateful, long-running, and not natively redundant. This presents an issue when pods can get interrupted at any time. For example, eight hours into a 12-hour model training job, the cluster decides to scale down the node your job is training on.
Snorkel Flow implements job checkpointing to deal with this issue. This means that the workers processing jobs will periodically store and checkpoint their status (typically after each training epoch). If Kubernetes happens to reschedule the worker (due to eviction, downscaling, etc.), it can pick up the job from the previous checkpoint and continue where it left off. As a result, the job always runs to completion and users see very little interruption, regardless of if Kubernetes tears down workers mid-job.
As we further build out job checkpointing, we’re also using a combination of pod affinity rules and pod disruption budgets to minimize interruptions due to cluster operations. Even with checkpointing, users can lose job progress (e.g. a training epoch) due to pod disruption. Pod disruption budgets ensure that stateful, long-running pods can only be disrupted by a node shutting down.
The affinity rules, on the other hand, make it so that stateful pods will gravitate towards nodes running other stateful pods, and stateless pods will gravitate towards nodes running other stateless services. Working in tandem, the effect is that we have two distinct pools of nodes: one running stateful and long-running jobs, and one running stateless services that can scale up and down freely.
In effect, we end up having two categories of nodes: one that runs stateful services that avoid scaling down, and one that runs stateless services that can scale up and down freely. Combining these Kubernetes rule sets ensures that stateful pods do not get interrupted by the cluster, while at the same time maximizing cluster efficiency.
Enable autoscaling of the compute cluster
Due to the stateful, long-running, and non-redundant nature of ML development workloads, it may intuitively make sense to avoid autoscaling. Needing to re-trigger jobs due to random workload interruption versus turning off autoscaling altogether and keeping a consistently-sized cluster is a tough tradeoff to make. However, job checkpointing allows us to enable autoscaling with the tradeoff that we expect workers to be interrupted on occasion, but erases the risk of non-completion.
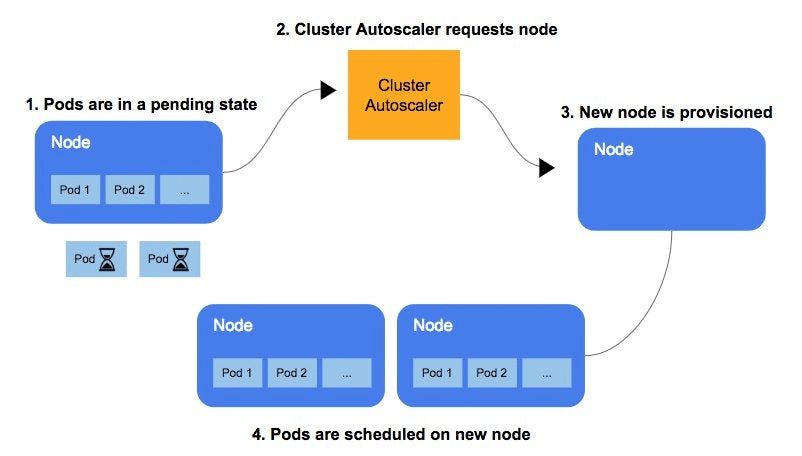
ML development workloads are bursty by nature. During periods of active ML application development on Snorkel Flow, workers all busily execute jobs. During off-hours, when the platform use drops, workers sit idle (but still remain the most resource-intensive part of our application).
Enabling autoscaling of our cluster gives us two major benefits:
- During periods of high activity, the Kubernetes cluster scales up along with the workers, enabling us to execute more jobs in parallel, clear out our job queue quicker, and keep end-users happy with platform performance even under heavy load.
- During periods of low activity, the Kubernetes cluster scales down automatically to save cost.
Distributed systems and infrastructure at Snorkel AI
At Snorkel AI, we develop Snorkel Flow, an end-to-end platform for the ML development lifecycle. The distributed systems and infrastructure teams at Snorkel are working on solving unique challenges in handling and processing data at a massive scale on a modern stack—all while having an eye for efficiency and cost. Through this, we aim to make ML development practical for some of the world’s largest enterprises.
Come work with us
At Snorkel AI, we work diligently to make it easier for enterprises to build better AI solutions, faster. We integrate cutting-edge research with industry-leading design and engineering to create new, powerful, and user-friendly tools on our Snorkel Flow platform. If that sounds like work you'd like to do, check out our careers page! We’re actively hiring for engineering roles across the entire stack.

Will Huang