
Kubernetes is an open-source container orchestration system built to automate deploying, scaling, and managing containerized applications. The project itself debuted in 2014, and has become the infrastructure backbone of many modern software companies and their products. This introduction to Kubernetes will cover the basics of the system.
Why has Kubernetes (abbreviated “k8s” because it contains eight letters between the “k” and the “s”) become such a popular framework to run applications on in the past couple of years? K8s comes with a number of features—practically for free—that teams previously needed to build support for themselves. Most of these are also quite complex requirements for any distributed system, involving tough design decisions that are non-trivial to implement such as horizontally scaling services and rolling deployments.

Introduction to Kubernetes’ Basic components
The pod is the core unit of compute in k8s; each pod can run one or more containers (with volume attachments if needed) that map to a single IP address, typically used to run microservices.
Each k8s cluster is made up of two key components: the k8s control plane and an arbitrary number of attached worker nodes whose sole job is to run containers. (Kubernetes refers to workers as “kubelets.”) Within the control plane, k8s has a control manager that watches for newly created pods that haven’t been assigned to a worker. This control manager uses the scheduler to assign a pod to a kubelet that belongs to the cluster, taking into account a number of heuristics and hard constraints in its decision.
The scheduler takes into account many factors, including:
- How busy are particular worker nodes?
- Do they have room for more pods?
- Are there any affinity rules where a pod needs to live on a particular node type (like those with GPU)?
Introduction to Kubernetes’ advantages
The design of k8s’ core infrastructure offers a lot of advantages out-of-the-box.
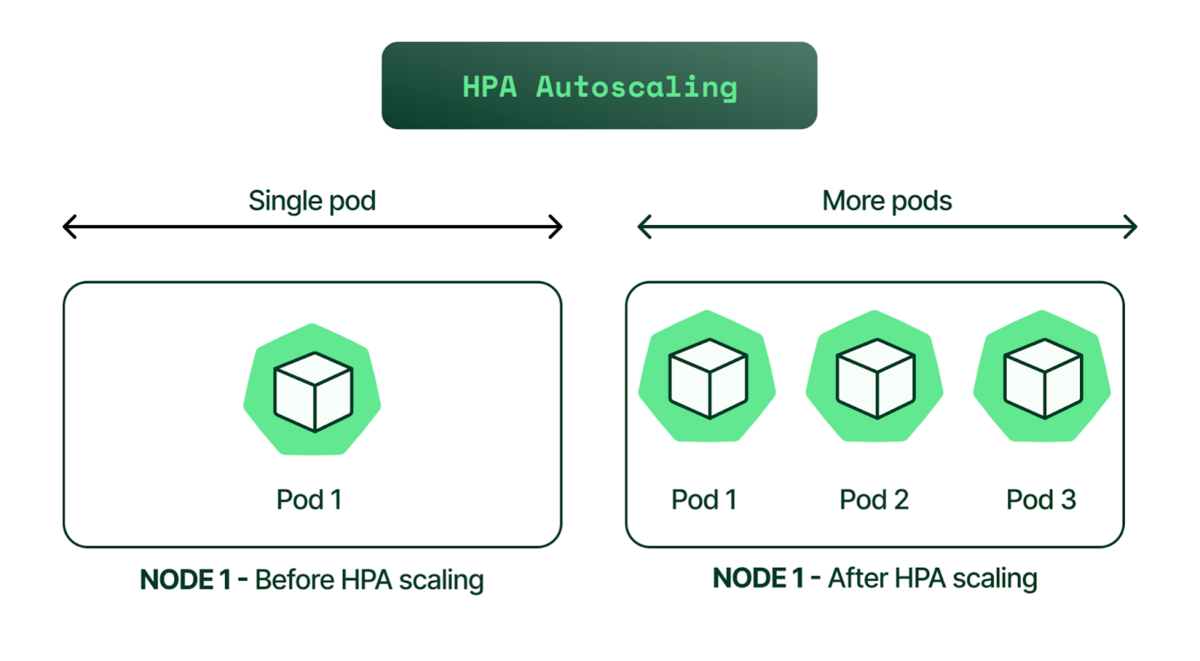
- Horizontal Autoscaling: The horizontal autoscaler in k8s will watch the CPUs and scale up or down the number of pods running a particular service based on load, completely automated.
- Rolling Deployments: K8s offers rolling deployments and rollbacks for free as well. It will bring up a pod running the new version, tear down a pod running the old version, and continue until the new deployment is completely rolled out, incurring no downtime.
- Self-Healing: K8s will restart pods that error out, reschedule pods if a kubelet dies, kill pods that fail health checks, and won’t advertise a pod to clients until it’s fully responsive and ready to serve.
- Service Discovery and Load Balancing: K8s service objects provide a load balancing layer in front of a set of pod replicas, taking care of service discovery automatically when pods spin up and tear down.
- Bin Packing: K8s will scale the cluster up and down according to need, and reshuffle pods based on the collective compute needs of the system, saving compute cost during times of low traffic.
Kubernetes has also become an appealing option for ML pipelines due to many of the reasons above. It offers a way for companies to achieve infrastructure parity between their ML workflow and other services. However, building and deploying ML applications is a unique k8s use-case, where some of the patterns don’t cleanly fit the paradigms k8s introduces.
Development Challenges
While Kubernetes offers a lot of advantages, it requires programmers to consider nuances of the framework as they build out their code.
Containerization
Running any kind of service on k8s requires building and deploying applications as containers.
Containerizing slows iteration speed, which can be a particular challenge for data scientists and ML engineers. When a developer adds a new third-party library to an experiment in k8s, they’ll need to rebuild the container image again. There’s no easy way to dynamically install additional libraries in a container environment without compromising security.
The Scheduler
The scheduler is one of the core components of the k8s control plane. It watches for newly-created pods that are not yet assigned to a node and finds the best kubelet/worker node to run the pod based on resource limits, affinities, or other factors.
Kubernetes can evict running pods and reschedule them at any time. There are many reasons why an eviction would happen:
- Readjusting bin-packing of pods on nodes.
- Scaling down the cluster’s size.
- Upgrading/rotating underlying nodes.
It’s actually a fairly common pattern to regularly rotate the entire cluster as part of routine cluster maintenance, as often as daily.
Eviction often causes problems if the underlying services aren’t built to handle it. Kubernetes assumes some level of fault tolerance by default. Services need to be horizontally scaled in order to handle evictions without downtime, and stateful services need to be able to handle arbitrary restarts.
The Job Abstraction
K8s users often initiate 1-off workloads (like for ML training) using a job object. This higher-level abstraction is typically used for running batch processes that need to run to completion and exit.
Let’s take training an ML model as an example of a job workload. By default, the job abstraction will restart the pod if it didn’t run to completion, which may not be what you want. If a training job fails due to a real error, we don’t necessarily want to keep retrying. However, a restart policy of “Never” is also not quite right either. If the pod running a training job gets evicted or the node it lives on gets scaled-down, I want the training job to restart and run to completion, not just disappear.
Kubernetes also garbage-collects all finished jobs eventually. This poses a problem if we want to grab error logs from a job that errored out a couple of days ago. The `kubectl logs` command will be inaccessible, and we’d be forced to just re-run the experiment and catch the error soon after it happens.
Lastly, since using jobs for ML training jobs will run the container to completion and exit, we’ll need to store the experiment results in an external store like s3 to persist.
Statelessness
Ultimately, k8s was built to run stateless web workloads, which can be a challenge for tasks that accumulate state over time—such as model training. If a long-running experiment gets interrupted (gets rescheduled, crashes, etc.), unless there is a persistent volume attached to this specific run, we’ll need to effectively restart from scratch.
Existing Tooling
The existing tooling for k8s is not very mature for some applications—such as machine learning workflows.
For ML engineers, working around the nuances of containerization, storage, and logging in a k8s environment is challenging. It’s a fundamentally different workflow than what developers were previously used to, where they would SSH into a single machine, install required packages, and kick off an ad-hoc experiment with a script, write to disk, and grab logs directly. Especially during development, there are times when a simple bash script to run over a dataset would be handy (data cleaning, preprocessing steps), but k8s doesn’t have the in-built tooling to support this type of workflow.
Using k8s also requires significant DevOps overhead. Due to the significant difference between DevOps around typical web services and DevOps around ML, “mlops” has recently become differentiated as a separate role, responsibility, and skillset.
Conclusion
This introduction to Kubernetes outlined why it has become the canonical infrastructure used to build modern software applications on top of. It provides benefits like self-healing, rolling deployments, and efficient bin-packing to optimize compute cost, practically out-of-the-box.
However, much of Kubernetes is optimized specifically for horizontally scaled, stateless services and presents a suite of challenges for running workloads that don’t exactly fit that mold. ML workloads, in particular, happen to often be stateful and not horizontally scaled, requiring developers to really understand and build around these challenges.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

