
We are honored to be part of the International Conference on Learning Representations (ICLR) 2022, where Snorkel AI founders and researchers will be presenting five papers on data-centric AI topics
The field of artificial intelligence moves fast!
- Hardly a month goes by without exciting new state-of-the-art techniques, results, datasets, and models being released.
- Hundreds of AI papers are published each day on pre-print websites such as arXiv and OpenReview.
- And the conversation never stops, between conference workshops, industry meetups, and the 24/7 “ML Twitter” chatter.
This is a world we are intimately familiar with at Snorkel AI, having spun out of academia in 2019. For over half a decade before beginning work on Snorkel Flow, we were researchers at the Stanford AI Lab, reading and writing papers, attending and hosting conferences, collaborating across universities and disciplines, and keeping abreast of exciting industry trends and future directions. And in the three years since…we haven’t stopped!
Developing and integrating cutting-edge research in data-centric AI development is at the core of what we do at Snorkel. We have intentionally designed Snorkel Flow with flexible abstractions and extensible interfaces that allow us to continually bring the latest and greatest technologies from the lab to our customers.
As part of fulfilling that mandate, members of the Snorkel founding team and research team regularly participate in and present work at top-tier AI conferences such as ICLR. During ICLR 2022, we are honored to be presenting five papers:
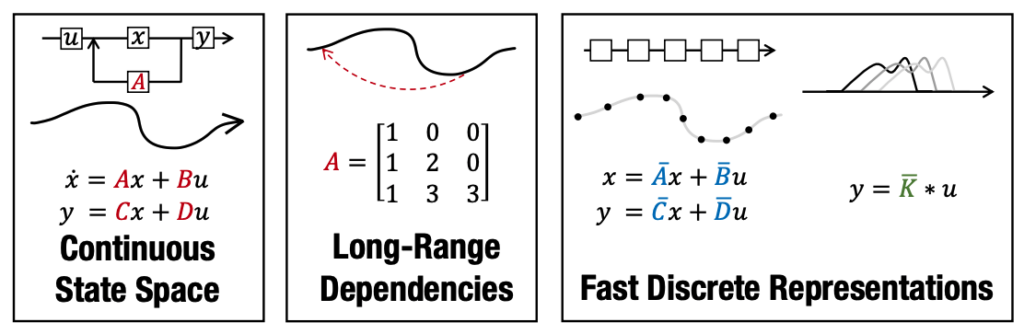
“Efficiently modeling long sequences with structured state spaces”
- To enable users to focus primarily on the data, ML practitioners need robust model architectures that work across a variety of data and task types. Data types with long sequences (such as time series or long docs) have historically been problematic, requiring specialized variants of common architectures.
- In this paper (an Outstanding Paper honorable mention, representing the top 10 papers out of 3000+ submissions and an oral presentation at ICLR 2022), Chris and team at Stanford introduce the Structured State Space sequence model (s4), which uses a new parameterization for the state-space model to improve long-range dependency handling both mathematically and empirically. Among other things, the model achieves new state-of-the-art scores on every task form the Long Range Arena benchmark.
“Domino: Discovering systematic errors with cross-modal embeddings”
- At the center of data-centric AI is having visibility and control over what signals are present in your training data. This includes being aware of slices (data subsets) where your model consistently underperforms or overperforms relative to the dataset at large.
- In this paper (an oral presentation at ICLR 2022), Chris and team at Stanford outline a new principled evaluation framework for comparing slice detection methods, then introduce a new technique motivated by our discoveries that outperforms existing methods by double digits.
“Multitask prompted training enables zero-shot task generalization”
- Our first paper (a featured spotlight at ICLR 2022) comes from the Big Science year-long research workshop, which gathered 900 researchers from 60 countries and more than 250 institutions to create T0, a best-in-class foundation model that often outperforms models 6-16x its size on zero-shot tasks by focusing on higher quality training data.
- Snorkelers Stephen Bach and Jason Fries co-led teams as part of that initiative, using a data-centric approach to generate high-quality training data at massive scale to improve the zero-shot abilities of that model.
“Universalizing weak supervision”
- Weak supervision has been successfully applied to a wide variety of data types and tasks, resulting in a proliferation of frameworks and algorithms.
- In this paper presented at ICLR 2022, Fred and team at Wisconsin introduce a universal framework that enables weak supervision over any label type while still offering desirable properties, including practical flexibility, computational efficiency, and theoretical guarantees. This enables weak supervision to work for regression, recommendation systems, graph, manifold, and many other type of learning problems.
“Creating training sets via weak indirect supervision”
- As more and more organizations turn to using programmatic supervision to drive their data-centric AI development cycles, a natural and exciting question emerges: can this programmatic supervision be reused to accelerate the development of new, related tasks?
- In this paper, Alex, Jieyu Zhang, and collaborators at UW, Microsoft Research Asia, UST China, and CMU define a new way to formalize, model, and use existing programmatic supervision on related tasks, enabling new levels of subject matter expertise reuse and strong economies of scale across multiple modeling tasks.
We provide links to these five papers below, their abstracts, and one key figure from each paper to give a taste of what they contain. If you’re going to be at ICLR 2022, find us at our presentations or poster sessions—we’d love to chat! For future updates on data-centric AI research from the Snorkel AI team, follow us at @snorkelai on Twitter. To see what’s in the Snorkel Flow platform today or discuss the product roadmap, request a demo.
Efficiently modeling long sequences with structured state spaces
⭐ Outstanding Paper honorable mention and oral presentation
Snorkeler: Christopher Ré
Abstract:
A central goal of sequence modeling is designing a single principled model that can address sequence data across a range of modalities and tasks, particularly on long-range dependencies. Although conventional models including RNNs, CNNs, and Transformers have specialized variants for capturing long dependencies, they still struggle to scale to very long sequences of 10000 or more steps. A promising recent approach proposed modeling sequences by simulating the fundamental state-space model (SSM) x 0 (t) = Ax(t) + Bu(t), y(t) = Cx(t) + Du(t), and showed that for appropriate choices of the state matrix A, this system could handle long-range dependencies mathematically and empirically. However, this method has prohibitive computation and memory requirements, rendering it infeasible as a general sequence modeling solution. We propose the Structured State Space sequence model (S4) based on a new parameterization for the SSM, and show that it can be computed much more efficiently than prior approaches while preserving their theoretical strengths. Our technique involves conditioning A with a low-rank correction, allowing it to be diagonalized stably and reducing the SSM to the well-studied computation of a Cauchy kernel. S4 achieves strong empirical results across a diverse range of established benchmarks, including (i) 91% accuracy on sequential CIFAR-10 with no data augmentation or auxiliary losses, on par with a larger 2-D ResNet, (ii) substantially closing the gap to Transformers on image and language modeling tasks, while performing generation 60× faster (iii) SoTA on every task from the Long Range Arena benchmark, including solving the challenging Path-X task of length 16k that all prior work fails on, while being as efficient as all competitors.
Domino: Discovering systematic errors with cross-modal embeddings
⭐ Oral presentation
Snorkeler: Christopher Ré
Abstract:
Machine learning models that achieve high overall accuracy often make systematic errors on important subsets (or slices) of data. Identifying underperforming slices is particularly challenging when working with high-dimensional inputs (e.g. images, audio), where important slices are often unlabeled. In order to address this issue, recent studies have proposed automated slice discovery methods (SDMs), which leverage learned model representations to mine input data for slices on which a model performs poorly. To be useful to a practitioner, these methods must identify slices that are both underperforming and coherent (i.e. united by a human-understandable concept). However, no quantitative evaluation framework currently exists for rigorously assessing SDMs with respect to these criteria. Additionally, prior qualitative evaluations have shown that SDMs often identify slices that are incoherent. In this work, we address these challenges by first designing a principled evaluation framework that enables a quantitative comparison of SDMs across 1,235 slice discovery settings in three input domains (natural images, medical images, and time-series data). Then, motivated by the recent development of powerful cross-modal representation learning approaches, we present Domino, an SDM that leverages cross-modal embeddings and a novel error-aware mixture model to discover and describe coherent slices. We find that Domino accurately identifies 36% of the 1,235 slices in our framework – a 12 percentage point improvement over prior methods. Further, Domino is the first SDM that can provide natural language descriptions of identified slices, correctly generating the exact name of the slice in 35% of settings.

Multitask prompted training enables zero-shot task generalization
⭐ Spotlight presentation
Snorkelers: Stephen Bach, Jason Fries
Abstract:
Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks (Brown et al., 2020). Where it has been hypothesized that this is a consequence of implicit multitask learning in language models’ pretraining (Radford et al., 2019). The paper dives into the question, can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping any natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts with diverse wording. These prompted datasets allow for benchmarking the ability of a model to perform completely held-out tasks. We fine-tune a pre-trained encoder-decoder model (Raffel et al., 2020; Lester et al., 2021) on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models up to 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-bench benchmark, outperforming models up to 6x its size. All trained models are available at this Github repo and all prompts are available at this Github repo.

Universalizing weak supervision
Snorkeler: Fred Sala
Abstract:
Weak Supervision (WS) frameworks are a popular way to bypass hand-labeling large datasets for training data-hungry models. These approaches synthesize multiple noisy but cheaply-acquired estimates of labels into a set of high-quality pseudolabels for downstream training. However, the synthesis technique is specific to a particular kind of label, such as binary labels or sequences, and each new label type requires manually designing a new synthesis algorithm. Instead, we propose a universal technique that enables weak supervision over any label type while still offering desirable properties, including practical flexibility, computational efficiency, and theoretical guarantees. We apply this technique to important problems previously not tackled by WS frameworks including learning to rank, regression, and learning in hyperbolic space. Theoretically, our synthesis approach produces a consistent estimator for learning some challenging but important generalizations of the exponential family model. Experimentally, we validate our framework and show improvement over baselines in diverse settings, including real-world learning-to-rank and regression problems along with learning on hyperbolic manifolds.

Creating training sets via weak indirect supervision
Snorkeler: Alex Ratner
Abstract:
Creating labeled training sets has become one of the major roadblocks in machine learning. To address this, recent Weak Supervision (WS) frameworks synthesize training labels from multiple potentially noisy supervision sources. However, existing frameworks are restricted to supervision sources that share the same output space as the target task. To extend the scope of usable sources, we formulate Weak Indirect Supervision (WIS), a new research problem for automatically synthesizing training labels based on indirect supervision sources that have different output label spaces. To overcome the challenge of mismatched output spaces, we develop a probabilistic modeling approach, PLRM, which uses user-provided label relations to model and leverage indirect supervision sources. Moreover, we provide a theoretically-principled test of the distinguishability of PLRM for unseen labels, along with a generalization bound. On both image and text classification tasks as well as an industrial advertising application, we demonstrate the advantages of PLRM by outperforming baselines by a margin of 2%-9%.

If you’re also attending ICLR 2022, we look forward to seeing you there and hope you’ll stop by our presentations and posters! You can find more past research papers by the Snorkel team on our website. To learn more about data-centric AI with Snorkel Flow, request a demo, or stay informed about future news and research from the Snorkel team, you can follow us on Twitter, Linkedin, Facebook, or Instagram.

Braden Hancock
Co-founder
Braden is a co-founder and Head of Technology at Snorkel AI. Before Snorkel, Braden spent four years developing new programmatic approaches for efficiently labeling, augmenting, and structuring training data with the Stanford AI Lab, Facebook, and Google. Prior to that, he performed NLP and ML research at Johns Hopkins University and MIT Lincoln Laboratory and earned a B.S. in Mechanical Engineering from Brigham Young University.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

