
What is data annotation?
Data annotation refers to the process of categorizing and labeling data for training datasets. This process plays a critical role in preparing data for machine learning models, as high-quality training data enables more accurate predictions and insights. In order for a training dataset to be usable, it must be categorized appropriately and annotated for a specific use case. With Snorkel Flow, organizations can annotate high-quality labeled training data via Labeling Functions and rapidly develop and adapt AI applications by iterating on labeled data programmatically.
Teams often overlook the importance of data annotation guidelines and best practices until they’ve run into problems caused by their absence. Supervised machine learning problems require labeled data, whether you are trying to analyze financial documents, build a fact-checking system, or automate other use cases. Snorkel Flow accelerates the annotation process by generating labeled data via programmatic labeling, but teams still need a clear definition of the labels (i.e., ground truth).
The quality of annotated data impacts the effectiveness of machine learning models. Ensuring data quality through consistent annotation practices can elevate projects involving object detection, image classification, and semantic segmentation.
What are data annotation guidelines?
Annotation guidelines are the guideposts that annotators, domain experts, and data scientists follow when labeling data. The critical steps for creating these guidelines are:
👩💼 Consider your annotators’ background, as robust project management involves understanding whether they are experienced in specific data annotation types such as video annotation or audio annotation
🔄 Iterate early to refine definitions
📍Consistently keep track of confusing and difficult data points.
Annotations can encompass different data types, including text annotation, image annotation, and sensor data. For example, audio data annotation supports models in voice recognition, while video data annotation assists with tasks like object tracking.
Snorkel Flow supports this process by providing a custom data annotation platform and tagging capabilities for flagging ambiguous data points as a part of the end-to-end, data-centric AI application development platform. Moreover, the interplay of programmatic labeling and hand annotations can surface systematic problems in the annotation guidelines.
Why do we need guidelines for data annotation?
Supervised learning tasks like sentiment analysis or topic classification may seem straightforward at first glance, but they often involve a lot of gray areas. Does this sentence have a positive or negative sentiment:
I loved the acting, but the special effects were awful.
The best answer is mixed sentiment, but has that class been added to the label space? In Named Entity Recognition (NER), a common problem is distinguishing between GPEs (Geo-Political Entities or governments) and Locations. Consider this sentence:
The aliens attacked Britain.
Should Britain be labeled as a government or a place? These scenarios show how detailed semantic annotation and entity annotation are necessary for consistent results. Clear annotation guidelines can help narrow down the set of unclear situations. This early process directly impacts your downstream applications, as models can only fit their inputs. For example, if a social media platform wants to build a model to detect harmful language — an underspecified process for labeling the training data may lead to legitimate content getting blocked, or vice-versa for inadvertently publishing violative content.
Annotation requirements vary by project. For instance, computer vision projects that involve image annotation may utilize bounding box annotation for accurate object detection. Similarly, annotating data for audio classification or video annotation requires meticulous guidelines to label raw data effectively.
Types of Data Annotation
Data annotation encompasses various techniques to ensure machine learning models receive high-quality training data tailored to specific use cases. Understanding these types is essential for choosing the right annotation strategy for your project. Below are some key types of data annotation:
Image Annotation
Image annotation is crucial for computer vision tasks, including object detection, image classification, and semantic segmentation. Annotators label images using different methods like bounding box annotation, polygonal segmentation, and key point tracking to define objects accurately within an image. These techniques help AI models identify and interact with the real world effectively, improving applications such as autonomous driving and facial recognition.
Video Annotation
Video annotation involves annotating video data frame-by-frame or through automated techniques to track and label moving objects. This type is used for tasks like object tracking, activity recognition, and motion analysis. Video annotation ensures that AI models learn to detect and follow objects across sequences, which is vital for surveillance systems, sports analytics, and robotics.
Text Annotation
Text annotation helps with natural language processing (NLP) tasks such as sentiment analysis, entity annotation, and intent annotation. Annotators label elements like named entities, emotions, and key phrases within text. This type of annotation is crucial for training models that need to understand human language, such as chatbots, sentiment analyzers, and language translators.
Audio Annotation
Audio data annotation involves labeling sound clips to train models for applications like voice recognition, speech-to-text conversion, and audio classification. This may include transcribing spoken words, identifying background noises, or categorizing different speakers. Audio annotation is key for improving voice-activated systems and enhancing user interactions with virtual assistants.
Sensor Data Annotation
With the rise of IoT and sensor data in AI applications, annotating data collected from sensors (e.g., lidar, radar) is vital for developing systems like self-driving cars and smart home devices. Annotators work to label environmental inputs accurately, ensuring AI can process and react to real-time sensor information for tasks like navigation and obstacle avoidance.
Video and Image Segmentation
In projects requiring precise annotation, semantic segmentation is used to label each pixel in an image or video, helping AI distinguish between different objects and backgrounds. This detailed approach is crucial for medical imaging, geographic mapping, and any use case where high precision is required.
3D Point Cloud Annotation
For 3D modeling tasks, annotators use point cloud annotation to map objects in three-dimensional space. This type of annotation is commonly used in applications such as drone navigation, AR/VR environments, and detailed urban mapping projects.
Textual Intent and Sentiment Annotation
Annotators identify the underlying intent of a piece of text or the sentiment behind it. Intent annotation classifies text based on user intentions (e.g., query, command), while sentiment annotation labels it as positive, negative, or neutral. These types help refine models for customer service chatbots, recommendation engines, and social media sentiment analysis tools.
Common challenges in data annotation
When defining guidelines, consider these frequently overlooked aspects:
- Addressing the management of sensitive data. In AI data annotation, ensuring the privacy and integrity of data points is crucial, particularly when dealing with personal or proprietary information.
- The role of bias and subjective interpretation. Annotator demographics and personal views can subtly influence their judgments, especially in nuanced tasks like toxicity detection.
- Clarifying class overlap: Some classes may inherently overlap (e.g., ‘supportive’ versus ‘neutral’ in sentiment analysis), so distinct examples should be provided to distinguish these cases.
Next, let’s take a deeper look at real-world annotation guidelines. They may include class definitions, examples, and rules on when to skip an example. Detailed guidelines for text annotation, image classification, or intent annotation help maintain high-quality data annotation results and reduce discrepancies in the labeled dataset.
Example: Part-of-Speech Tagging
Consider the Part-of-Speech Tagging Guidelines for the Penn Treebank Project, which was developed in 1991. The resulting corpus is used as a basis of many modern NLP packages that include a Part-of-Speech (POS) component. For some classes, the guidelines assume that the annotator knows English grammar rules and simply provides the acronym to use.
For instance, annotators need clear instructions on handling homonyms (e.g., ‘lead’ as a verb versus ‘lead’ as a metal) and context-dependent roles in data annotation tasks.

Other guidelines include explicit examples:

A large portion of the guide is devoted to “Problematic Cases,” where the part of speech may not be apparent even to an expert in grammar. The difference between prepositions and particles can be exceptionally subtle.

Example: Annotation Argument Schemes
The guidelines can get increasingly complicated depending on the task — for example, in the paper Annotating Argument Schemes that looked at argument structure in Presidential debates, an extensive flow-chart was used to define the intent of different argument types:
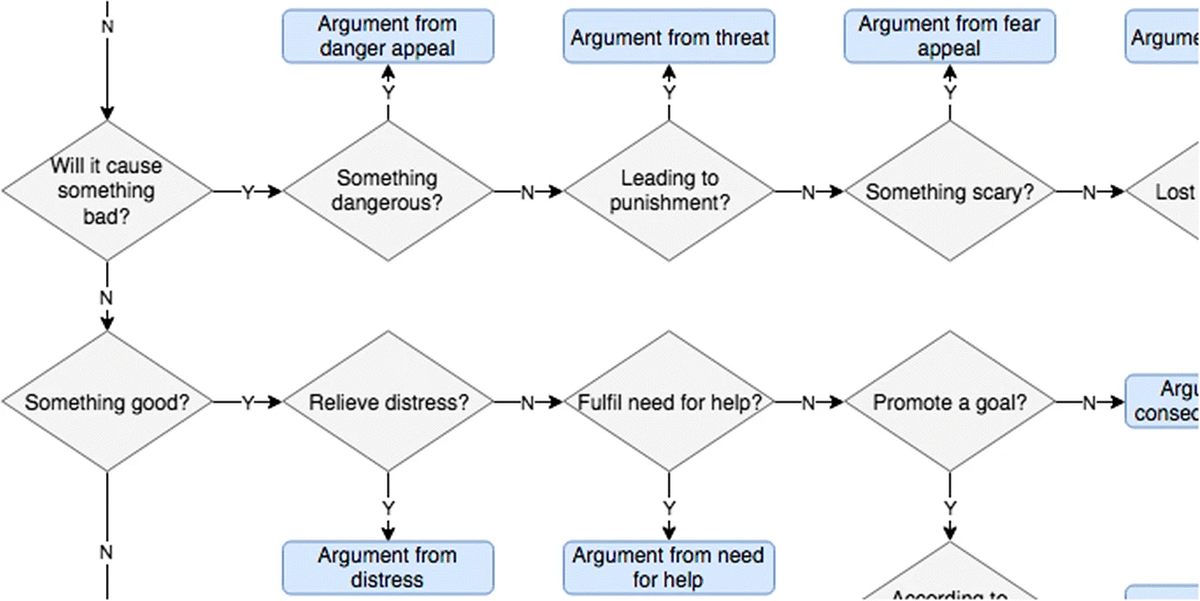
Both of those examples represent tasks with complex structure and high cardinality. However, even binary classification tasks may need to be worded diligently:
When classifying social media posts for toxic traits, detailed examples should be given to explain what language falls into each class. This scenario is challenging as multiple studies have found annotators’ predisposition to affect their perception of toxicity 1, 2. Subjectivity can come up in less nefarious contexts, too. Consider a financial group that wants to build a relevance model to identify news that may affect companies’ stock portfolios. Different annotators may perceive what the model should classify as relevant.
Building the data annotation guidelines
Now that we’ve established the importance of well-designed annotation guidelines, we will discuss some criteria for how to produce them. To start, teams should conduct preliminary tests with small data samples to identify ambiguities and make iterative updates. This ensures that any discrepancies are spotted early on. Robust project management during this phase ensures that relevant data is handled properly, and tasks such as image annotation or object tracking remain accurate.
Considerations in building data annotation guidelines
Let’s consider the overall process in terms of two examples: designing guidelines for the POS Treebank and a news relevance task for a financial organization. First, we want to consider the audience. In this case, it is both the annotators and the downstream users of the application. Guidelines must adapt based on the type of data being labeled, whether it’s semantic annotation for NLP tasks or data annotation for sensor data used in autonomous systems.
Each group will require different levels of detail in the guidelines. We would also consider whether the nuanced uses of “there” (as shown earlier) will matter to the model trained on this dataset. In the news relevance task, the annotators and downstream application users will be the same analysts, so the definition of relevance will be up to them, but we still want alignment across the annotators.
Include mechanisms to assess data quality, such as reviewing samples of annotated data periodically and employing annotation tools that support consistency checks.
Creating a first pass
With this consideration, we will create a first pass of the guidelines. These should include a definition of each class and a couple of examples. Teams should always have a couple of expert annotators label a few dozen examples so everyone involved can review disagreements, points of confusion, and missing definitions. Deciding how to handle these cases early helps avoid relabeling more significant swaths of data later. Even a small set of data can reveal problems: we may realize that “one” can be used both as a cardinal number or a noun; or that two analysts disagree on whether a news article about vaccine availability will affect a specific company; or that we forgot to include a class for the mixed sentiment. We can empirically consider how subjective the task is using one of several empirical annotator agreement metrics.
“Newsflash: Ground truth isn’t true. It’s an ideal expected result according to the people in charge.”
Cassie Kozyrkov, Chief Decision Scientist, Google
With subjectivity, we should consider potential annotator biases when designing the guidelines. We discussed how annotator demographics could influence their perception of toxicity in social media. In such cases, a very detailed rubric can be used to mitigate some of the effects. In the next section, we will discuss how programmatic labeling can help us recognize some of these problems and fix the guidelines and the labels.
Snorkel Flow’s advantage in data annotation
The Snorkel Flow platform can help with all aspects of designing annotation guidelines.
First, Snorkel Flow provides an in-platform annotation workspace that is integrated with the main model development loop. In the annotation workspace, it provides inter-annotator agreement metrics and the ability to comment on individual data points. Next, the platform has a built-in capability for tagging data points. This allows annotators to note confusing examples early in the process and bring them up for discussion within the platform. By keeping the annotation and development processes in the platform, we tighten the loop for iterating annotation guidelines.
Leveraging programmatic labeling to enhance guideline accuracy
Snorkel’s Labeling Functions provide a powerful mechanism for resolving problems with ground truth. Using heuristics, users can encode the guidelines. By evaluating them on hand-labeled data, we can discover underspecified cases. Let’s say that for the parts-of-speech system, we encode a rule:
If the word is “one”, then it is a cardinal number.
If this rule gets low precision based on ground truth, we will quickly see that some annotators consider one a noun in specific cases. This points us to a place where we can iterate on the guidelines. For news relevance, a rule that says vaccines → non-relevant and getting low precision will point to another point for discussion amongst the subject matter experts. Once an agreement is reached, the “controversial” examples can be easily pulled up in the platform and fixed by filtering on the rule.
Finally, Snorkel Flow makes it simple to edit the label space.
Going back to the initial example: I loved the acting, but the special effects were awful. If you decide that your application needs a new mixed sentiment class, Snorkel Flow’s Label Schema Editor allows this change and preserves existing ground truth and rules.
Final thoughts on data annotation
For many reasons, the whole definition and nuances of a task are often not going to be evident when we approach a new task. Projects involving intent annotation, semantic segmentation, and computer vision can face unique challenges that evolve over time. The data may contain unexpected edge cases. Downstream users may disagree on specific labels, or we may have defined the guidelines in a manner subjective to the annotators. These situations emerge naturally from the process. Most of them can be handled through an iterative and collaborative-driven process. The Snorkel Flow platform accelerates this process both through a built-in annotation workspace and the ability to use programmatic labeling to capture assumptions and disagreements in the labeling process.
Ensuring that annotators receive continuous training and that data annotation tools support real-time feedback and updates can contribute to more consistent, high-quality annotations.
Annotation tasks, when approached with accurate annotation and data quality measures, lead to the creation of reliable, annotated datasets that improve the performance of AI models.
If you are interested in learning more about data annotation guidelines and how they work within Snorkel Flow, request a demo with one of our machine learning experts. We would be happy to go over the specifics of your use case and how programmatic data labeling can be applied to accelerate your AI efforts.
Stay in touch with Snorkel AI, follow us on Twitter, LinkedIn, and Youtube, and if you’re interested in joining the Snorkel team, we’re hiring! Please apply on our careers page.
Footnotes:
1 Jiang, Jialun Aaron, Morgan Klaus Scheuerman, Casey Fiesler, and Jed R. Brubaker. 2021. “Understanding International Perceptions Of The Severity Of Harmful Content Online”. PLOS ONE 16 (8): e0256762. doi:10.1371/journal.pone.0256762.
2 2022. “Annotation with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection”. Homes.Cs.Washington.Edu.
Featured image by Clayton Robbins on Unsplash.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

