
Powerful resources to leverage as labeling functions
In this post, we’ll use the COVID-FACT dataset to demonstrate how to use existing resources as labeling functions (LFs), to build a fact-checking system. The COVID-FACT dataset contains 4086 claims about the COVID-19 pandemic; it contains claims, evidence for the claims, and contradictory claims refuted by the evidence. The evidence retrieval is formulated as an unsupervised learning problem, which is not covered in this post. We focus on the veracity prediction task and formulate it as a binary classification problem: for each set of claims and pre-extracted evidence statements, we predict whether the claim is “SUPPORTED” and “REFUTED”.
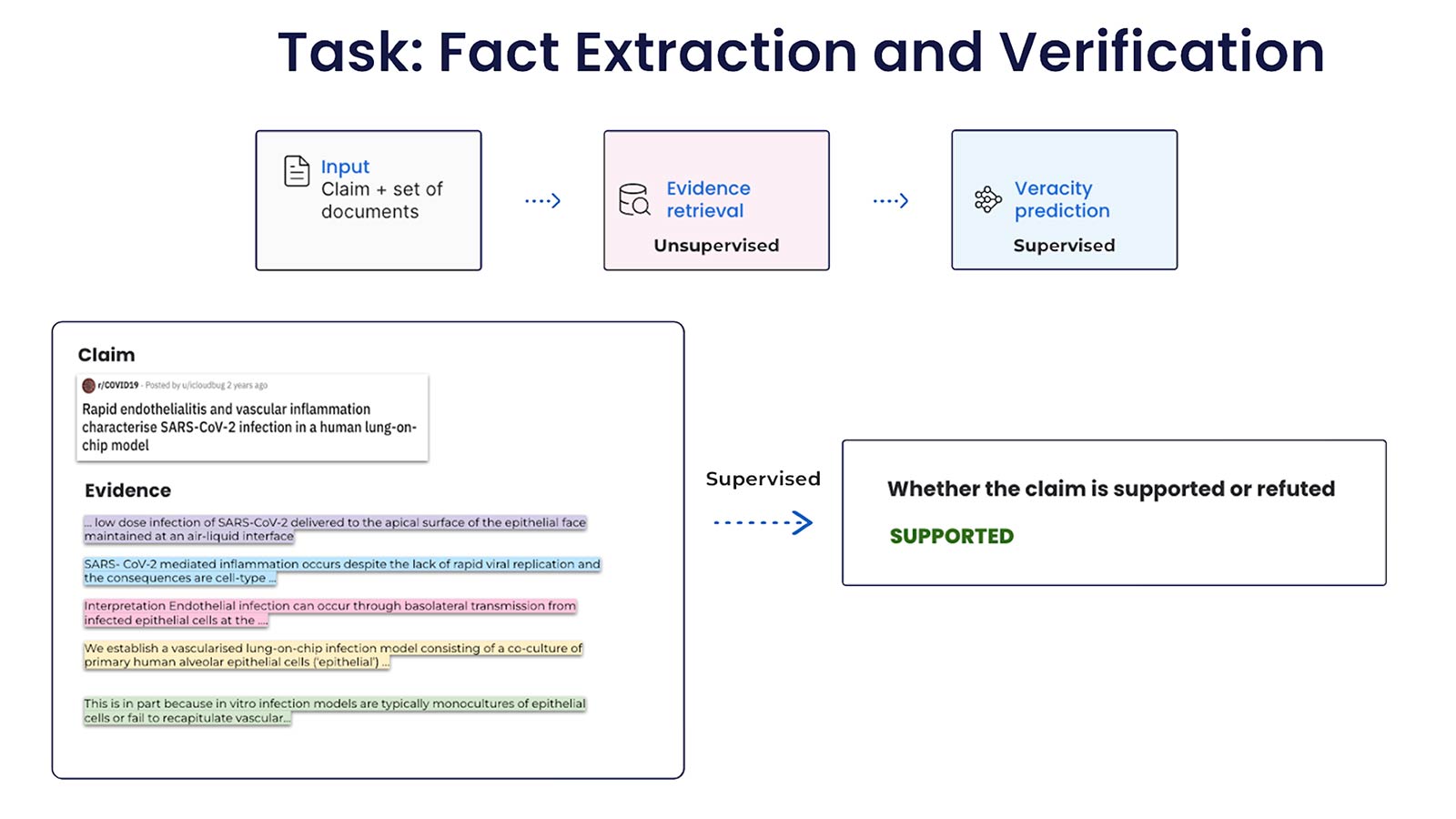
A labeling function is an arbitrary function that takes in a data point and produces a label programmatically. As no logic is assumed inside the function, it provides a flexible interface for leveraging various sources, ranging from domain expertise and knowledge bases, to pre-trained large language models (LLMs). Unlike traditional rules-based systems, LFs don’t need to be perfectly precise or have 100% coverage—our years of research show that we can produce high-quality training datasets using signals from external resources that may be noisy or incomplete. There are various types of LFs coming from a wide array of resources (see the figure below). In this post, we will focus on 3 types of labeling functions based on powerful external resources: knowledge-based, sentiment-based, and zero-shot learning-based LF.

Knowledge-based labeling functions
The COVID-FACT dataset contains evidence sourced from scientific and clinical research papers, and one heuristic to determine if a claim is supported by evidence or not is by leveraging the shared presence of medical terms. To do this, we first extracted all medical terms from both claim and evidence and then compared the overlaps between the medical terms: If a claim contains a medical term that is not mentioned in the evidence, then it is likely that the claim is not supported by the evidence. However, when extracting medical terms, it is common to see inconsistencies or abbreviations in text. For instance, in the example below, it is hard to know that claim and evidence are referring to the same entity without domain knowledge:
Claim: Saliva-based antigen testing is less than the [pcr] swab
Evidence: The failure of the antigen-based assay to match the diagnostic accuracy of the gold-standard test you are probably familiar with—the laboratory-based, reverse-transcription [polymerase chain reaction] nasal (or nasopharyngeal) swab—is why the Food and Drug Administration has been reluctant to approve it for sale in the U.S.
Luckily, there are many knowledge-based resources in the medical domain that we can use in LFs such as SNOMED CT.
We’d like to leverage this medical ontology to express a simple knowledge-based LF like the following:
If the medical terms extracted using the SNOMED ontology from the claim does not appear in the evidence, then vote “REFUTED”, otherwise vore “UNKNOWN”And the pseudo-code is:
def lf(x):
claim_terms = extract_snomed_terms(x.claim)
evidence_terms = extract_snomed_terms(x.evidence)
If not claim_terms.issubset(evidence_terms):
return "REFUTED"
else:
return "UNKNOWN"
In the above example, as the “polymerase chain reaction(PCR)” term appears in both claim and evidence, the LF would vote this example as UNKNOWN. With this LF, we are able to label 28.4% of the data, with a precision of 71.8%.Many more complex rules can be then applied on top of extracted medical terms, such as detection of ‘negation’ or ‘absence’, and can be used to compose more powerful LFs in fact-checking systems.
Sentiment-based labeling function
Sentiment analysis is a popular natural language processing (NLP) technique used to determine whether data is positive, negative or neutral. In our system, we will be using the off-the-shelf nltk.sentiment library to compute the sentiment, and the logic for the sentiment-based LF in fact-checking is pretty straightforward:
If the sentiments of the claim and the evidence are opposite, then vote “REFUTED”, otherwise vote “UNKNOWN”The pseudo-code is the following:
def lf():
If sentiment(x.claim) x sentiment(x.evidence) < 0:
return “REFUTED”
return “UNKNOWN”
In the example below we can see the sentiment score of the claim and evidence: the claim has a positive score of 0.2, while the evidence has a negative score of -0.18:
Claim: The recent CDC report on comorbidity is good news or evidence of a hoax
Sentiment score: 0.20 [positive]
Evidence: The latest ‘stunning confirmation’ in support of minimizing the pandemic threat is a recent report from the CDC which concludes that 94% of U.S. COVID-19 deaths were also associated with other ailments or comorbidities.
Sentiment score: -0.18 [negative]
Though sentiment signals are rarely used in fact-checking systems, they can be leveraged as a flexible interface in LFs.
Zero-shot learning-based LF
Zero-shot learning with pre-trained large language models has shown promising performance in many different tasks including fact-checking systems. However, as detailed in this post, these off-the-shelf models cannot serve as end models directly due to the knowledge gap. However, they can be excellent resources for labeling functions, as LFs do not require high precision/accuracy. We explored several existing pre-trained models to develop LFs. We are able to find out a couple of LLM pre-trained on combined Recognizing Textual Entailment (RTE) tasks: combination of well-known Natural language inference (NLI) datasets including SNLI, MNLI, FEVER-NLI, ANLI, etc, with different model architectures including RoBERTa, ALBert, BART (special shout out to Hugging Face).The pseudo-code is the following:
def lf(): prediction = ZSL(x.claim, x.evidence) If prediction == ‘entailment’: return ‘SUPPORTED’ elif prediction == ‘contradiction’: Return ‘REFUTED’ else: Return ‘UNKNOWN’
We observe that these models are doing a fantastic job in identifying the “REFUTED” class (with accuracy above 95%) when compared to the “SUPPORTED” class (with accuracy around 60%). See the detailed scores below with the statistics for the aforementioned LFs):
| Precision | Coverage | Label | |
| Knowledge-based LF with SNOMED CT | 71.8% | 28.4% | REFUTED |
| Sentiment-based LF | 73.3% | 6.0% | REFUTED |
| Pre-trained language model based LF -RoBERTA large | 61.3% | 30.0% | SUPPORTED |
| 97.7% | 35.2% | REFUTED | |
| Pre-trained language model based LF -Albert-xxlarge | 60.2% | 35.2% | SUPPORTED |
| 95.4% | 34.8% | REFUTED |
Generalizing beyond LFs
How does programmatic compare to manually labeled approaches? In this section, we show that labeling functions are comparable with manual labeling: we discard most of the ground truth labels, and only keep a small fraction (5%) of ground truth labels (total of 3263 labels) in the training set for iterating LFs and evaluation.
Even though most LFs developed here are noisy and do not have high coverage, when combined with the Label Model, the accuracy of the programmatic training labels is 79.5%. When we train an end model on top of the programmatic training labels we are able to achieve 82.6% of accuracy, which generalizes beyond the label model outputs. A few hours of LF developments came within 2 points of a fully-supervised approach (for reference, the benchmark score trained on manual labels is 84.7%).
| Accuracy | Trained on | |
| Label model | 79.5% | 5% manual labels ( to develop LFs) + 95% LF labels |
| End model | 82.6% | 5% manual labels + 95% programmatic label |
| Benchmark | 84.7% | 100% manual labels (or 3263 manual labels) |
Takeaways
Manual labeling is often time-consuming, often requiring professional fact-checkers to spend several hours or days annotating data. In Snorkel Flow, once a set of labeling functions are built it can label a dataset in just minutes instead of days or weeks. In addition, the programmatic labels generated from existing external resources are comparable to human labels, and can be easily applied to large datasets.
In summary, we demonstrated how to build LFs using external knowledge resources, and showed the advantages of these LFs:
- Flexible: Leverage signal from a wide range of resources, from off-the-shelf models to knowledge bases — Snorkel’s label model will help you denoise and aggregate those inputs!
- Efficient: By using programmatic labeling sources, we can achieve high quality models in a fraction of the time it takes to manually label these examples.
- Powerful: Take advantage of rich knowledge stored in powerful language models, or specific domain knowledge is stored in ontologies curated by human experts.
- Adaptable: it doesn’t matter if the knowledge is from SNOMED ontology or a large language model, these resources are being improved by researchers constantly and actively.
External resources are a powerful way to bootstrap labels for model development in Snorkel Flow. As you saw in this case study, we were able to build a high quality fact-checking model by injecting domain knowledge from a variety of external resources!
- While the individual LLM (x, y, z) can only achieve 50-60% of accuracy on the covid dataset, Combining them + other resources lead to 80+ of accuracy, which is very close to the bench mark numbers.
To demonstrate the ability of the labeling function and how its performance is comparable with human labeling, we discard most of the ground truth labels, and only keep a small fraction (5%) of ground truth labels in the training set for iterating LFs and evaluation.
If you’re interested in staying in touch with Snorkel AI, follow us on Twitter, LinkedIn, Facebook, Youtube, or Instagram.If you’re interested in becoming a user of Snorkel Flow, reach out to us at info@snorkel.ai. And if you’re interested in joining the Snorkel team, we’re hiring! Apply on our careers page.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

