
Labeling functions are fundamental building blocks of programmatic labeling that encode diverse sources of weak labeling signals to produce high-quality labeled data at scale.
Let’s start with the core motivation for labeling functions: over time, every major commercial organization and government agency builds various valuable, often bespoke knowledge resources. These resources include employee expertise, wikis and ontologies, business logic, and more. They are a rich source of competitive advantage; organizations turn to automation or machine learning solutions to scale their value. Unfortunately, they often run into blocking challenges:
- Using rule-based systems to automate decisions (using domain experts’ heuristics or information captured in ontologies or wikis) is too rigid and brittle to catch edge cases or meet changing requirements.
- Machine learning (ML) models require high-quality training data, which is slow and costly to create with traditional hand-labeling approaches—often to the point that application development becomes infeasible. When ML models are deployed, maintaining their value in changing production data or business objectives again becomes untenable.
With programmatic labeling, the Snorkel Flow platform unblocks organizations by accelerating training data creation by 10-100x and making AI application development possible and practical. At the heart of this is the ability to use labeling functions to capture diverse types of existing knowledge resources as code that can be applied to label data intelligently at scale.
In this post, we review what labeling functions are and three examples of using them to build machine learning solutions.
What are labeling functions?
The core idea of labeling functions is to encode organizational knowledge into reusable functions with the purpose of labeling training data. The founding team at Snorkel AI pioneered programmatic labeling and labeling functions as part of the Snorkel research project at the Stanford AI Lab. This work is represented across 60+ peer-reviewed research publications, and we continue to carry out fundamental research on programmatic labeling.
“The key idea is that if you can write some code that handles data labeling for you, building an effective model will be much faster and much cheaper because you can move at the speed of a machine.”
Chris Re
Associate Professor, Stanford AI Lab
Labeling functions can capture simple heuristics or keywords and far more complex sources of signals ranging from existing ontologies or dictionaries to the latest large language models or cluster embeddings.

When applied to your data, labeling functions will programmatically “vote” for the best label to apply to each data point (or whether to abstain). Labeling functions can often be imprecise, incomplete, and in conflict with one another. Here is where Snorkel’s concept of weak supervision comes in—the platform automatically de-noises and reconciles these “weak” sources to build a dataset with probabilistic labels. To dive deeper into labeling functions, programmatic labeling, and weak supervision, read the following research papers or watch a short video:
📝 Data Programming: Creating Large Training Sets, Quickly by A. Ratner et al.
📝 The Role of Massively Multi-Task and Weak Supervision in Software 2.0 by A. Ratner et al.
📝 Leveraging Organizational Resources to Adapt Models to New Data Modalities by S. Suri et al.
📺 Introduction to Snorkel by B. Hancock [Video]
Let’s focus on how labeling functions are used to create high-quality training data sets at scale with three explicit examples that may be relevant to the machine learning projects you’re considering.
Labeling functions for document classification
Document classification is a procedure of assigning one or more labels to a document or text from a predetermined set of labels. It is an everyday use case across many industries. For example, consider different kinds of invoices like reimbursements, office expenses, invoices for third-party software, etc., that need to be sorted by category. Or even something as simple as classifying email in SPAM or NOT SPAM.
For our first use case, let’s take a scenario where the business has tasked a machine learning team with producing a model to classify and route business contracts based on their contract type: “services”, “stock”, “employment”, and “loans”. A Top 50 US Bank has used Snorkel Flow to solve a similar problem.
Data scientists and subject matter experts can create labeling functions that capture and apply heuristics or patterns.
Looking at a few examples of the text extracted from a handful of “services” documents, we can see that a pattern emerges:
- This Amended and Restated Technical Consulting and Services Agreement (the “Agreement”) is entered into as of July 20, 2003…
- THIS PROGRAMMING SERVICES AGREEMENT (this “Agreement”) is made and…
- This MANAGEMENT SERVICES AGREEMENT (the “Agreement”) is entered into on…
Many of these documents seem to contain some pattern of This (something) services agreement. We can write a labeling function to test our assumption that this pattern will be prevalent and distinct to “services” agreements, and we can see that it is both highly accurate and provides excellent coverage of our intended documents:
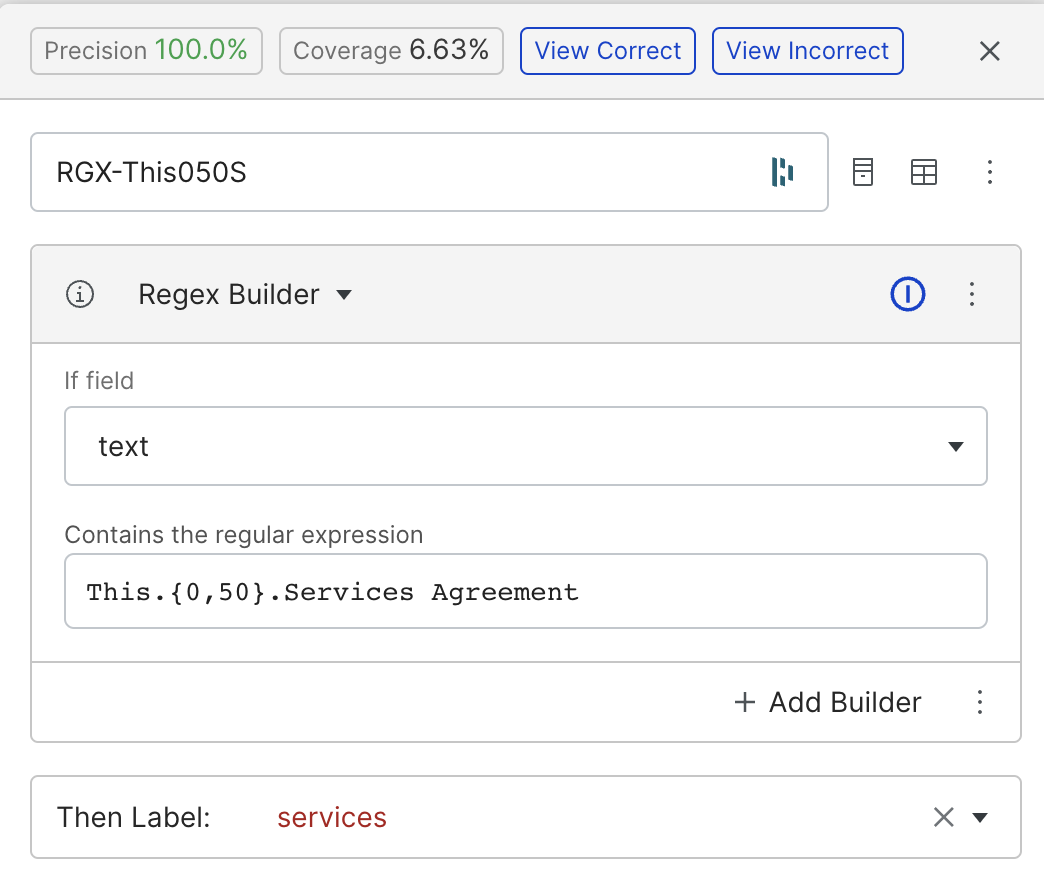
If your organization has already built out a knowledge repository, you can use it as a source of supervision as a labeling function. A list of commonly associated terms with a given class can be placed in a Dictionary.
In this example, a small dictionary with terms commonly associated with loans (terms such as “borrower” or “credit check”) is used in a labeling function to search the text of a contract for instances with those words. As demonstrated, this simple labeling function provides surprisingly high accuracy and coverage.

Snorkel Flow, a data-centric AI platform, can also help you bootstrap a collection of labeling functions by learning from a small hand-labeled dataset. Using the “Suggest LFs” feature, Snorkel Flow can automatically produce new labeling functions with discovered keywords that result in high precision and coverage for each class.
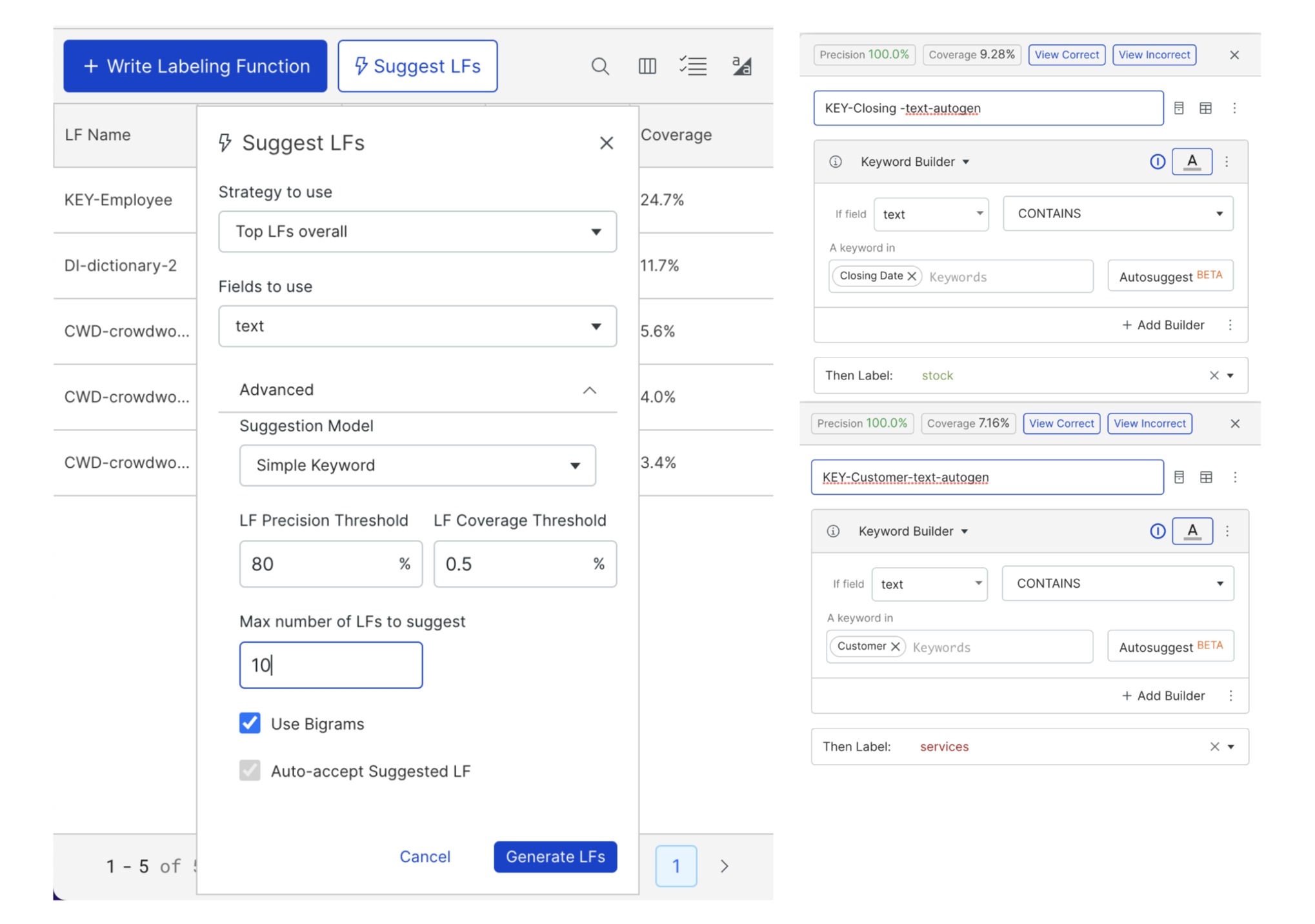
It is worth noting that while each of these labeling functions individually is quite simple (looking only for specific keywords verbatim), our classifier will not be limited to such a simple feature set. These labeling functions are used only to create a training set. The model trained on that dataset will likely observe the prevalence of those features and thousands of others that co-occur with them, allowing it to generalize beyond the individual labeling functions into a more general-purpose and robust classifier. This way, we benefit from having direct and scalable inputs (labeling functions) to our model development process while still getting a fine-tuned state-of-the-art ML model as an output.
Labeling functions for numerical network data classification
The application of network classification can be seen in many domains. These vary from preserving the network’s quality to analyzing network users’ characteristics. However, traditional methods applied for network data classification are less effective in the real world. Networks are dynamic and prone to rapid changes. Programmatic labeling using labeling functions offers a way for organizations to develop adaptable applications.
For the second use case, we explore a scenario where the business has tasked a cybersecurity team with building a model to identify which applications that encrypted network data flows originated from Facebook, Amazon, or Youtube. A Fortune 500 Telecom has developed a similar use case using Snorkel Flow.
While the traffic is encrypted and we cannot see the content, the network flows still have a lot of different features (over 80) that can be used to label them. Cybersecurity analysts can use data analysis tools combined with their subject matter expertise to create labeling functions on any of these features quickly.
For example, an analyst may know that port 80 is always used by Youtube for streaming services. This fact can be encoded into a Numeric LF, similar to the Keyword LF discussed in the document classification example. Furthermore, video services often involve large packet sizes. As the diagram shows, beyond 15 million, all values map to Youtube. An analyst could have initially encoded these types of rules into a custom rules-based engine, but given many available features, such a system would be hard to manage. If some variables change significantly, labeling functions make it easy to adjust the encoded heuristics. Consider how when Twitter first doubled its message size or enabled video, all the rules surrounding packet size would have needed to change, and the Snorkel Flow LF interface makes this process easy.

We see that Youtube seems to have packet sizes that are very large consistently. Youtube is a video streaming service that returns large video files. At the same time, Facebook and Amazon are primarily social media and shopping sites that rely on smaller images or text files.
Creating a labeling function based on this observation results in an estimated high precision while achieving coverage of over 7% of the data.

What can be more interesting with numeric data is not observing individual features but instead discovering the relationships between these features. Through a bit of correlation analysis, a cybersecurity SME might find that there appears to be a strong relationship between the features Avg.Fwd.Segment.Size and Fwd.Packet.Length.Max. Plotting these features on a scatterplot reveals a few distinct clusters for each class.
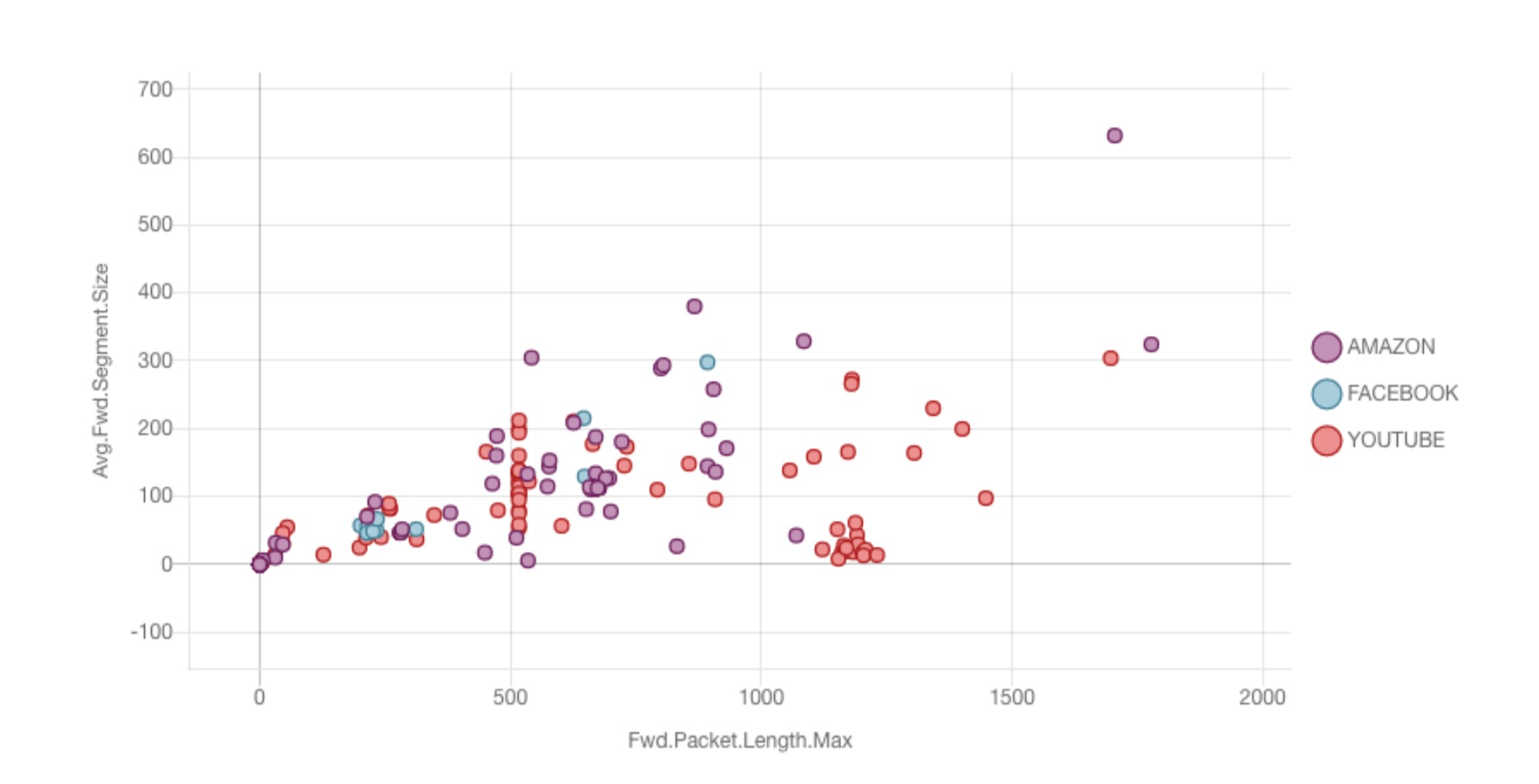
We can easily capture these clusters in a labeling function by drawing a bounding polygon around the intended areas.

This labeling function drawn to identify a Youtube cluster was estimated to have nearly 100% precision and over 9.8% coverage.
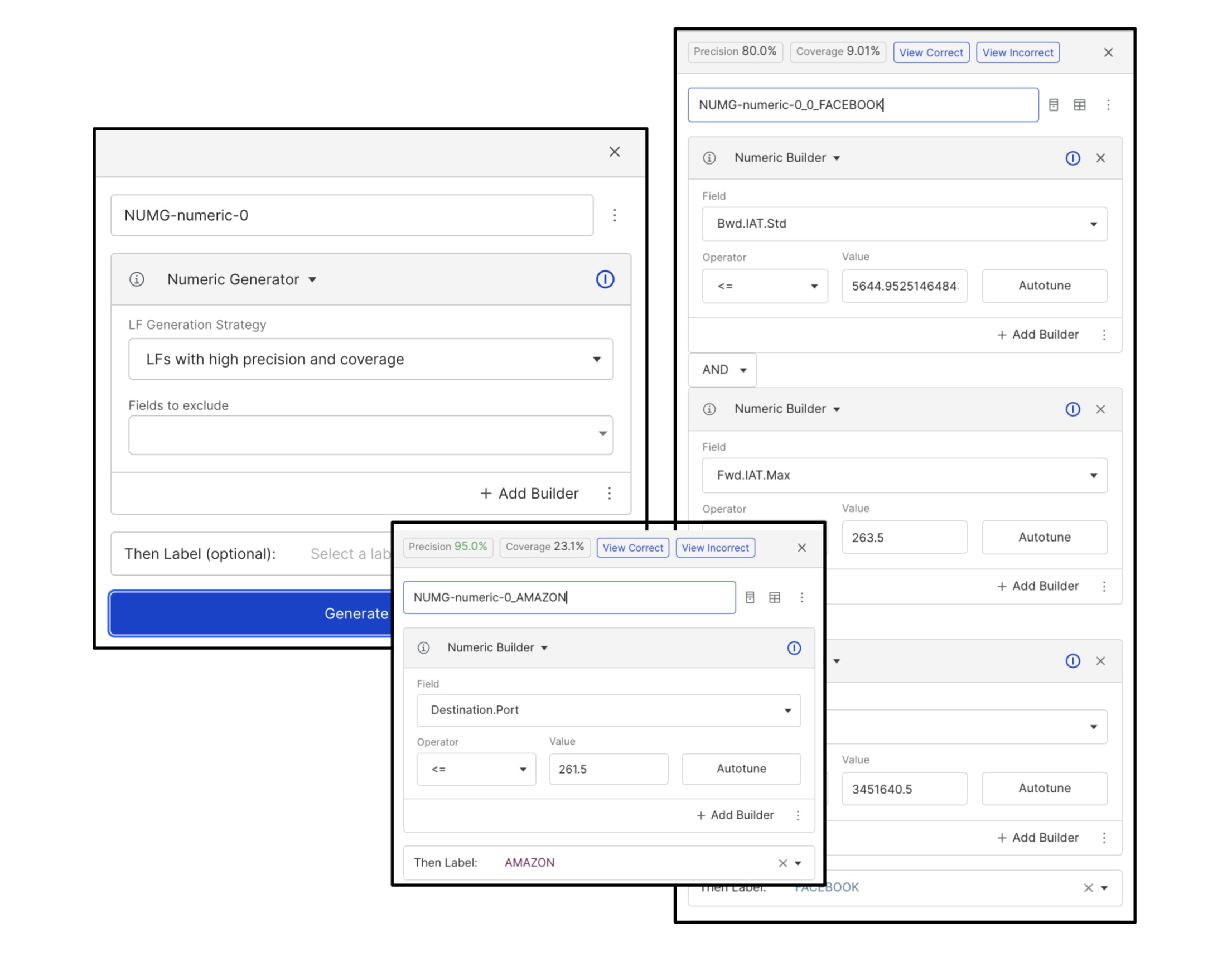
Like the “Suggest LFs” feature, we can use the Numeric Generator to create Numerical labeling functions based on a small number of labeled examples in the train set if such exist. Again, this allows us to bootstrap our labeling coverage of our FACEBOOK and AMAZON classes without subject matter expertise or existing knowledge bases.
Labeling functions for Conversational AI
Some of AI’s newest applications appear in conversational interfaces such as chatbots or customer support triaging from text messages or social media accounts. Let us look at an example labeling utterances from conversations with a virtual banking assistant.
Because labeling functions can be expressed as arbitrary python code through the Snorkel Flow’s SDK, they can take advantage of other use-case-specific tools. One class we are interested in identifying is the “TransferMoney” class for utterances related to users’ requests to transfer money between various accounts owned by other people or organizations. An entity recognition library from the natural language processing (NLP) application spaCy was used to preprocess the data and identify these entity types (Organizations (ORG) and Persons (PERSON)) within each utterance. A simple labeling function determines if these entities are present:
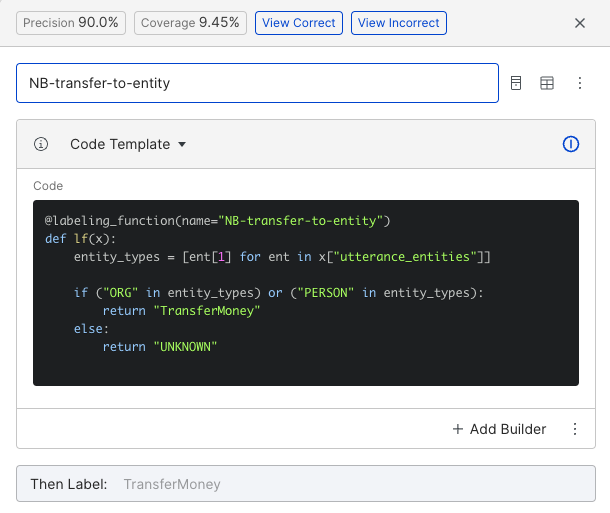
We have used the spaCy example from our growing library of code-based labeling functions. But you can easily create new, custom labeling function templates by adding the @labeling_function decorator to any python function.
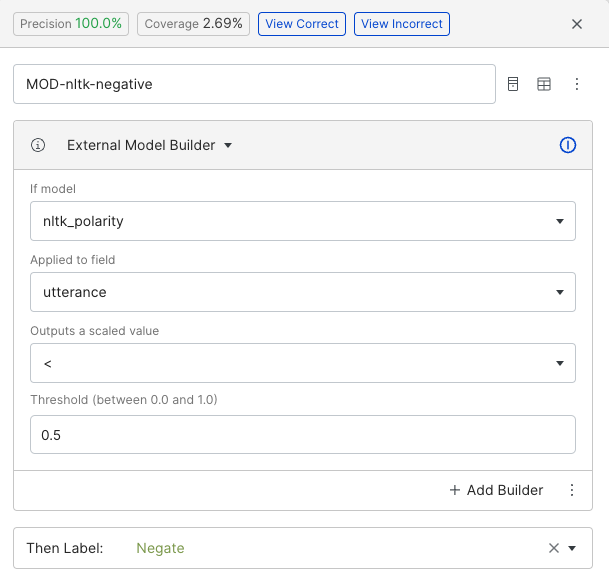
Labeling functions can also take advantage of other existing machine learning models. While any model can be used via the SDK, here we craft a labeling function that uses the built-in nltk sentiment model, which identifies if a given phrase is expressing a negative sentiment (e.g., “I will not do that”).
Final thoughts
Labeling functions offer a way to capture and store various pieces of information that have already been proven to be valuable within your organization. Snorkel Flow can also discover new labeling functions for your data without subject matter expertise or existing knowledge when all you have to start is a small pre-labeled set. When labeling functions are utilized within the Snorkel Flow platform as a part of a programmatic labeling methodology, this leads to the creation of massive, high-quality training datasets, with many advantages over previous disparate methods.
Where to learn more about labeling functions
In this post, we have only demonstrated a small sample of the growing number of use-cases we support within the Snorkel Flow platform and the ways we can express labeling functions. Labeling functions are incredibly flexible and extensible to nearly every imaginable data type and problem formulation.
If you are interested in learning more about labeling functions and how they work within Snorkel Flow, request a demo with one of our machine learning experts. We would be happy to go over the specifics of your use case and how weak supervision can be applied to accelerate your AI efforts.
Stay in touch with Snorkel AI, follow us on Twitter, LinkedIn, and Youtube, and if you’re interested in joining the Snorkel team, we’re hiring! Please apply on our careers page.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

