New Snorkel benchmark leaderboards. See the results.
Building AI models for financial document processing best practices
Highlighting the best practices for building and deploying AI models for financial document processing applications
AI has massive potential in the financial industry. Building AI models to automate information extraction, fraud detection, and compliance monitoring can provide efficient and faster responses and support repurposing domain experts’ labor to more meaningful tasks. Developing AI models is not just about having models and good scores, especially at large financial institutions. There are many more moving pieces: problem formulation to address business needs, templatization for future iterations, managing dozens of datasets and models, explainability, governance, and more.
At Snorkel AI, with years in research and working with some of the largest enterprises in the financial services sector tackling complex use cases using Snorkel Flow, a data-centric AI platform, we have gathered best practices for developing AI pipelines rapidly. This article focuses on sharing our learnings about building AI pipelines for financial documents (and much of these learnings apply to other use cases as well).
Representing problems as graphs is helpful for cross-team collaboration and dependencies management
Most financial organizations have complex business scenarios driving document processing specifications. Using natural language processing (NLP) approaches to conduct textual analysis of unstructured data from financial reports such as 10-K, Letters of Credit, Bank Notes, etc., are becoming increasingly common. However, each organization has these documents uniquely warehoused and seeks to use information from these documents uniquely.
For example, if a banking institution is looking to build customer risk profiles for auditing or investment purposes, they would need to process documents such as 10-Ks, 10-Qs, 20-Fs, etc. Each of these documents contains a piece of the information needed to build comprehensive risk profiles. While some problems can be solved with a single end-to-end model, in most cases, you need significant pre/post-processing and custom logic to accurately represent business needs.
Learn more about the design principles for our DAGs.
Instead of having one model handling all the required logic, data science and machine learning teams should break down the problems into a modular, composable pipeline of individual building blocks of processing, models, and business logic. Such pipelines need a clear Directed Acyclic Graphs (DAG) representation to orchestrate the team efforts and reflect the hierarchical data flow and dependencies of projects. This is a highly effective way to foster team collaboration across data scientists, data engineers, machine learning engineers, MLOps, and even subject matter experts.
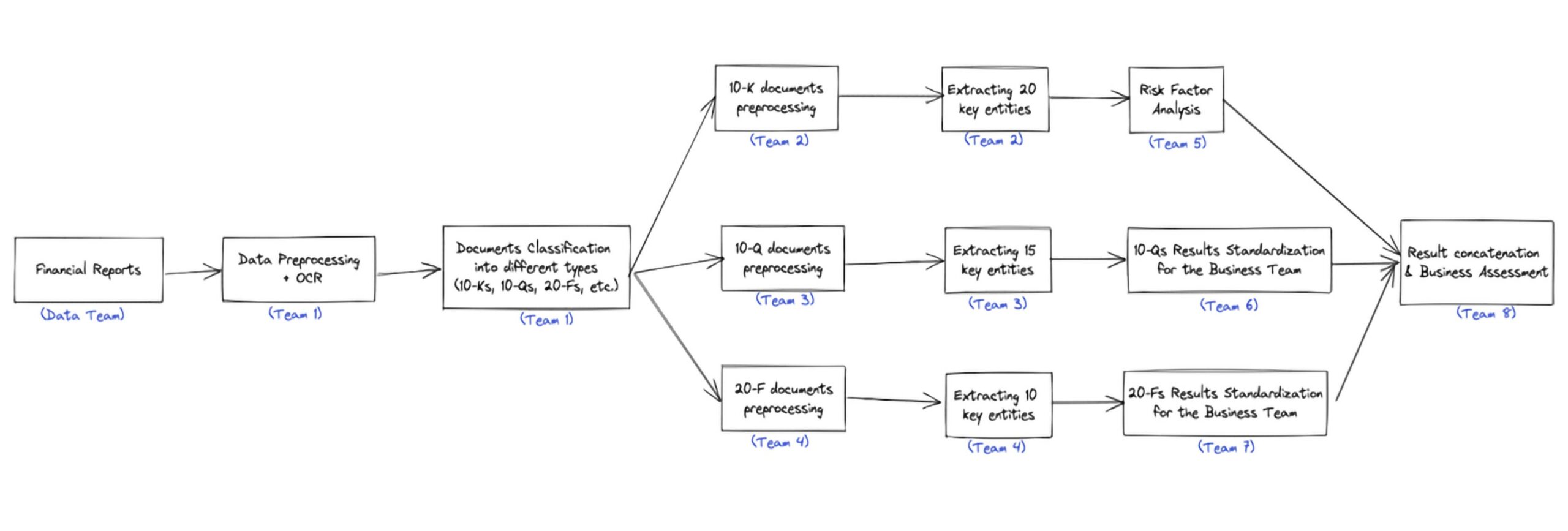
Especially for financial institutions, where all documents are deeply specialized, the involvement of subject-matter experts in the iteration loops is even more critical. Furthermore, problem statements at these institutions are rarely independent. One model will be the input for many other models, e.g., extracting 10-Ks information will not be a standalone problem but rather as input to risk assessment models. Complicated dependencies are then introduced in these pipelines. Often, teams underestimate how much context they have. Some teams might understand the problems’ data flow inside out, but without a clear DAG, subject-matter experts and engineers could miss out on the bigger picture, hence, degrade or fail to achieve production-worthy performance.
Via the DAG, data scientists and ML engineers can communicate accordingly to directly involved stakeholders to manage dependencies. Furthermore, they can communicate with people solving similar problems at similar DAG levels, templatize, and share learnings across different teams, resulting in better model results and fewer custom efforts.
How we do it with Snorkel Flow
Snorkel Flow applications are structured as directed acyclic graphs (DAGs) over atomic building blocks, called operators. Each operator is a function that performs a transformation over one or more data frames.
Each team can work individually on their models and processing, and eventually, we merge all individual pipelines into a complete workflow directly on the platform. This structure supports flexible development within each team; and transparency and effective coordination across teams. Furthermore, after merging models into the main workflow, results are reflected across all models once an upstream model changes, helping all groups be up-to-date on current performances and error modes. Snorkel Flow empowers collaboration and communications between data science teams! Read more on the design principles for our DAGs.
Plan for auditability, evaluation & error analysis at every step
Teams should always evaluate the performance after each building block and record the performance across the DAG. The end-to-end evaluation consists of aggregating errors across models. Models can work perfectly in their controlled test environment, but unexpected behaviors can happen in the full pipeline with dependencies on upstream models.
Especially in financial services, where trust is critical, understanding your model failure modes is a requirement before deployment. Aggregated errors can create systematic biases, and failures can be propagated and magnified in later models. These errors could cause severe trust issues with clients and reputation costs. A small error in upstream models can introduce new severe error buckets for all downstream models, even though they were perfect in the test environment.
For example, financial institutions with know-your-customer (KYC), anti-money laundering, or credit risk modeling require significant governance on these pipelines as these are client-related. These pipelines are also tremendously complex at every step, with different processing and parsing methods. Hence, evaluation and auditing only of the final results are neither trivial nor sufficient. A failure at the beginning of the pipeline to extract certain writing styles via OCR engines can cause some serious loop-hole in our KYC process, incurring serious business risks. Only through auditing and closely monitoring model performance at every step that we understand the potential errors and deploy a production-worthy model.
In addition, in many cases, biases & errors come from unrepresentative datasets and biases in sampling, reporting, or labeling methods. Snorkel’s programmatic labeling approach is beneficial for data auditing purposes. Snorkel Flow allows teams to leverage all existing unlabelled data (to prevent sampling biases), utilizes functions to label more data, and creates an audited, controlled environment where errors can be traced back and revised for better future models.
How we do it with Snorkel Flow
As Snorkel Flow applications are structured as DAG, it also enables close monitoring, evaluation, and error analysis at every stage.
This design principle helps debug scenarios when downstream models poorly perform due to unexpected inputs, allowing downstream models to evaluate and audit their expected input and output more similar to the production environment. Each application can consist of a few or a dozen building blocks, and as the complexity scales up, the workflow can contain hundreds of blocks, yet each block is independent and fully auditable.
Also, a considerable part of auditability is data auditability. Before, data was always treated as a fixed asset. However, by using programmatic labeling, one can control their data labels and prevent potential biases in manual labeling by confirming and cross-checking the labels against labeling functions. You can dive deeper here.
Snorkel Flow also has many built-in error analysis features and error-bucketing tools. We also perform deployment monitoring and full pipeline error analysis. As a data-centric platform, we strive to provide a more holistic approach to building AI pipelines from labeling, modeling, deployment, and monitoring.
Recycle existing resources and utilize special patterns
There are many potential useful resources you can utilize while building new models. Oftentimes, there are earlier attempts to tackle these financial documents. Although performance is not as high as expected, or minor data shifts occur, it would still be beneficial to bring these existing weak signals to support our new AI pipeline.
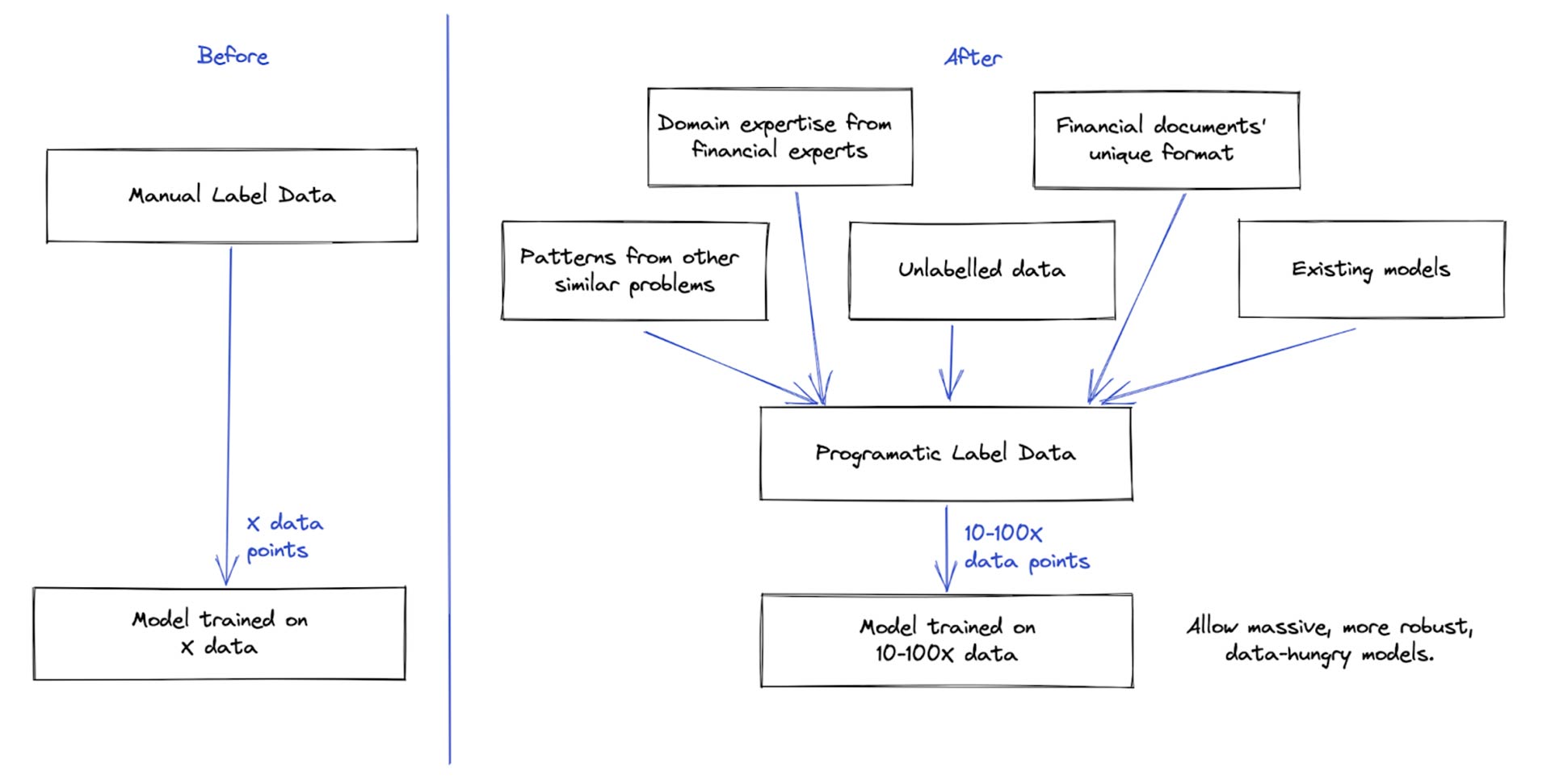
Helpful existing resources
- Leveraging domain expertise from financial experts—these patterns might take ML models thousands of data points to generalize. For example, experts will skim and jump directly to critical sub-sections. Without learning such heuristics, your model will struggle to extract information from dozens of pages.
- Utilize financial documents’ unique format—financial records usually have unique distinguishing layouts. Hence, models and solutions tailored to these formats are powerful.
- Reusing existing models as weak signals—past models can be outdated, but their signals to some subset of data can still be valuable.
- Utilizing patterns from similar document types—Extracting market risks from 10-Q documents can reuse many preprocessing, postprocessing, and models’ configs in projects extracting similar entities from 10-K documents.
- Unlabelled data—Labeled data is expensive, especially with these specialized functionalities. Unlabeled data is numerous and currently underutilized.
These existing resources can be messy and noisy and might not be perfect. You can make a rule-based system to utilize these signals, but it might not be well-performing due to noisy rules.
A better approach would be to utilize these signals as labeling functions. Labeling functions are signals that are allowed to be less precise, incomplete, correlated, or conflicting. Snorkel weak supervision model can bootstrap these labeling functions to create a large labeled training set from your unlabelled data, much faster and less expensive than manually labeling a similar amount of data. You can label thousands of documents within hours or days of development. Afterward, your team can train a data-hungry model for further generalization on this curated large training set.
Especially at financial institutions, your team can even reuse and refine these labeling functions for similar projects, like extracting managers’ information from 10-Qs and 10-Ks. Also, there are very high-cardinality problems like in conversational AI with hundreds of classes. You can easily bootstrap labeling functions and reuse similar logic for different classes, utilizing sentiment and topic-detection models as weak signals. Why start fresh and manual label when there are existing models and labeling functions that can help speed that process up multiple times with weak supervision. The reusability opportunity across models is auspicious.
How we do it with Snorkel Flow
Snorkel Flow has a variety of templatization across different ML use cases and allows utilizing any existing resources
Snorkel Flow has a library of many pre-built atomic building blocks or operators, from simple pre/post-processing to more advanced operators to create useful features in ML tasks. Especially for financial document processing use cases, we developed a built-in PDF document suite of features. These features leverage spatial and structural information, specialized models, and labeling functionality for model development. The PDF suite is applicable in many other ML use cases across industries.
All your existing resources, heuristics, models, and codes can be compatible with Snorkel Flow. You can bring in existing signals as “labeling functions”, and our Snorkel Label Model will bootstrap these labeling functions to create a large labeled training set from your unlabelled data. This approach creates exponentially more data compared to manual labeling, which is then used to fine-tune massive data models to tailor to the company’s use case.
Start small, iterate fast, and don’t be blocked by the data
ML problems need worthy business values. Especially for financial institutions, each ML problem will be closely tied to a business counterpart to ensure the models are meeting the business needs. The mutual understanding of both teams on a problem can sometimes be mismatched or business needs shift. Hence, before investing weeks building your entire ML pipeline, it’d be beneficial to run a few iterative experiments to validate the hypothesis for initial derisking and for teams to align on the expected results.
Start small with a minimal set of manually labeled data for validation and testing. Try curating your training set by utilizing programmatic labeling with your subject-matter experts’ domain knowledge. You’d be surprised how fast you can iterate and validate your hypothesis before investing further. That way, you wouldn’t be blocked waiting weeks or months before your data requests get approved and the first batch of manual labels arrive.
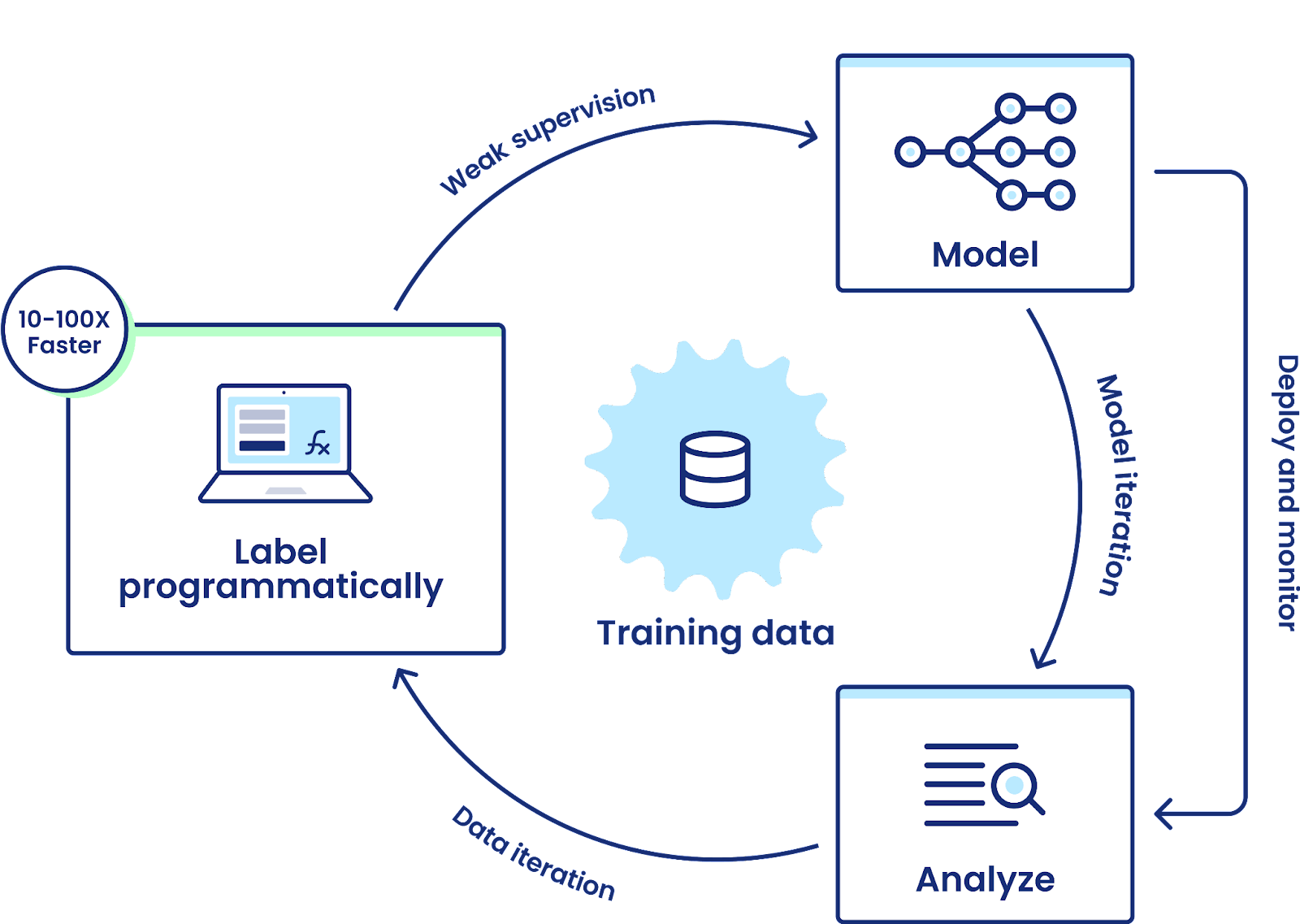
Furthermore, don’t be blocked by the data at all. If you wait for manual labeling, you might be blocked for a few months before having enough data for large models. Especially for financial institutions where your data must be processed and labeled internally, which incurs even a higher cost for labeling. Business objectives often shift mid-project, or you are back to square one if the data schema changes. Programmatic labeling can help speed up such processes.
Keep your limited expert-labeled data as validation and test set. Programmatic labeling can speed the labeling process up. Especially with financial documents, the programmatic approach is even more applicable thanks to the standardized structure. Resources from programmatic approaches can help adapt flexibly to new problem formulation and continue to empower you to leverage even more unlabelled data to train data-hungrier models. You can read it here if you are tired of waiting for your data to be manually labeled.
How we do it with Snorkel Flow
Data-centric and programmatic labeling empowers faster iterative development
Snorkel Flow is a data-centric AI platform powered by programmatic labeling & weak supervision. Instead of waiting for data to be manually labeled, you can utilize labeling functions to label your data, giving you a faster start. In one of our case studies, a top US Bank team produced a solution over 99% accurate in under 24 hours.
Snorkel Flow utilizes all available signals to give you faster iterations. Furthermore, with financial documents, the patterns can be very much similar. Hence, reusing the programmatic labeling solution in one application can inform many similar use cases. For example, when writing LFs to extract stakeholders’ names using structural information, you can reuse and transfer that logic to extract stakeholders’ nationality and equity percentage likely in the same text region. By utilizing all existing resources and “recycling” well-formed LFs, teams can boost their performance faster, and domain experts don’t have to label data manually. They can focus on more impactful work.
Final thoughts
In summary, developing and deploying AI applications for financial document processing is a challenging and massive process, and we have a few best practices:
- Representing problems as graphs is helpful for cross-team collaboration and dependencies management
- Plan for auditability, evaluation & error analysis at every step
- Recycle existing resources and utilize special patterns
- Start small, iterate fast, and don’t be blocked by the data
We’ve baked these best practices into our platform with programmatic labeling and other techniques available in Snorkel Flow. DAG-based Application Studio empowers problem formulation and auditability. Built-in templates, especially PDF Suite, promote templatization and leverage document-specific patterns. And finally, a data-centric approach with programmatic labeling helps teams utilize existing resources and iterate and deliver models faster.
To learn more about how SnorkelFlow can take your AI development to the next level, request a demo or visit our platform. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, or Youtube.
Featured photo by Ashu Sharma on PxHere.

Hoang Tran
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor's degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.