
ML models will always have some level of bias. Rather than relying on black-box algorithms, how can we make the entire AI development workflow more auditable? How do we build applications where bias can be easily detected and quickly managed?
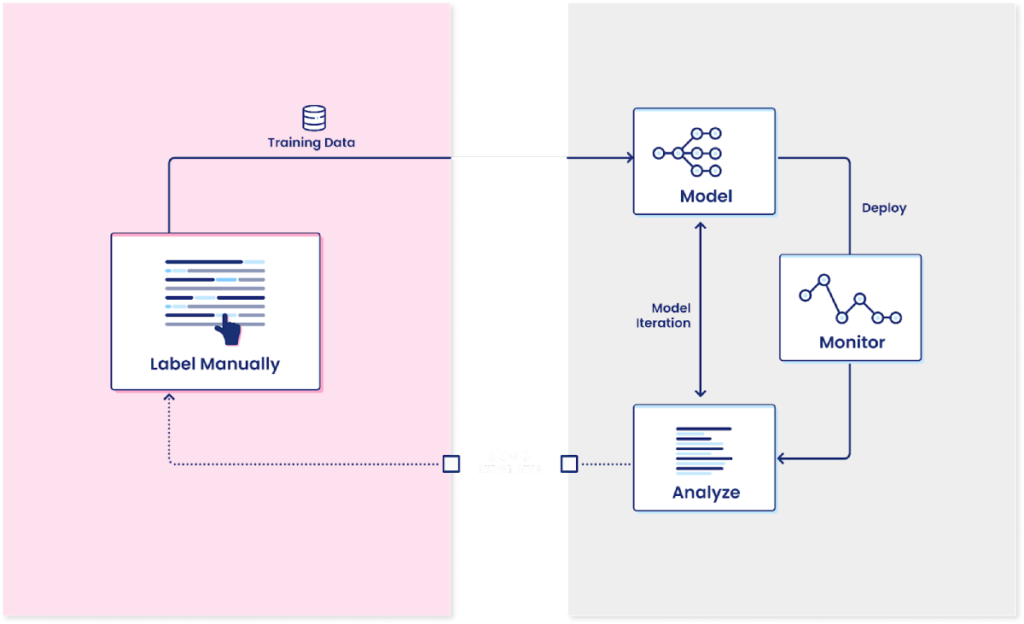
Today, most organizations focus their model governance efforts on investigating model performance and the bias within the predictions. Data science teams often choose less powerful but more interpretable frameworks like regressions and ensure their model will generalize by testing it via cross-validation and out-of-sample holdouts. However, what they miss in these efforts is generating sufficient labeled data to power high-performing models or ensuring the labels that the modeling process relies on are accurate.
The key to auditable models is auditable training data.
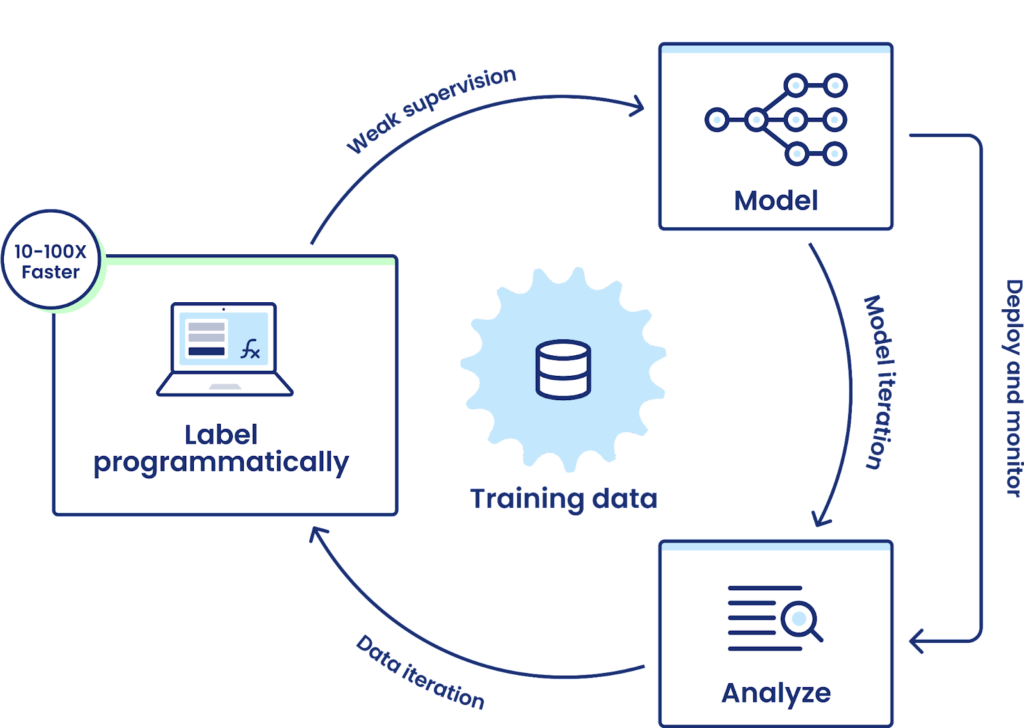
Snorkel Flow introduces an auditable process for labeling data programmatically, modeling, and analyzing the results. Snorkel Flow allows everyone involved in the model lifecycle – subject matter experts, data scientists, and model risk management teams – to audit and understand all aspects of the development process. It moves development teams away from manual data labeling or model building being done at a distance from the model governance teams, accelerating model development and increasing the visibility of how the end-to-end model works.
Programmatic labeling increases auditability of model development workflows.
We will walk through a high-level review of why companies put model risk management and governance processes in place, how people today audit the creation of data labels, and more details on how programmatic labeling and Snorkel Flow improve upon traditional approaches.
What do model governance processes look like within modern organizations?
Let’s first take a step back. Many companies have realized that quality control for machine learning models looks different than testing for traditional software. It’s not sufficient to make sure the model itself returns predictions in the correct format since you could end up with functioning but an incorrect model that does more damage than a model that returns no prediction at all. These issues can occur in several ways: the model itself may overfit the training data and fail to generalize; the data distributions may have changed from when the model was first built; you could even be passing through new categories for the inference that the model was never trained on in the first place. For example, McKinsey has written about the model resiliency challenges that banks ran into as COVID-19 impacted their operations.
Teams have responded by imposing formal or informal model governance processes on their machine learning efforts. For example, most large banks have centralized model risk management teams that need to review every model (partly because agencies like the Office of the Comptroller of the Currency publish hundreds of guidelines around the need for formal processes). For models used internally that are unlikely to have a negative impact if something goes wrong, this may only consist of a review to make sure that the data science team that built the model used best practices around out of sample holdout sets when testing model performance. In other cases, however, these model risk management teams sometimes go as far as rebuilding the whole model from scratch independently while requiring the modeling team to write up their end-to-end process, including feature selection, how they tested for bias, and what gives them confidence the model will be performant.
Not every company imposes this level of rigor and scrutiny. Still, most teams accept that there needs to be some level of approval for models that can impact the company’s bottom line or expose it to reputational or regulatory risks if something goes wrong. Issues arise when there isn’t sufficient data to train high-performing models or the labeled data is incorrect. These challenges come up more often than data science and model governance teams prefer.
Generating training data for modeling is time-consuming and challenging.
Let’s start with limited training data. Companies gather enormous amounts of data today, but much of it is unstructured, messy, and lacks clearly defined labels. Supervised machine learning models, which make up the bulk of models that companies rely on, learn from the past to predict the future. However, when there aren’t any labels to draw on, the algorithms and data science teams can’t make much progress and turn to labeling data points by hand.
Data science teams rarely (if ever) want to handle this themselves, so they ask the lines of business they’re supporting for subject matter experts to go through and annotate the data for them. These subject matter experts, in turn, have more important and urgent priorities and want to minimize the time they spend labeling. However, most large organizations can’t send data outside their firewalls, limiting how much third-party annotation teams can help. Even when companies turn to outside contractors, they face challenges with quality control or reconciling disagreements between annotators. Organizations like the Model Risk Managers’ International Association offer guidelines around the need for high-quality data. Still, it often falls on individual teams to decide how to proceed with data labeling.
If the project and model are important enough, companies can find a way to force people to label data despite these challenges. Everyone involved is incentivized to reduce the amount of time spent on this process, which leads to the creation of the minimum amount of labeled data possible that can power a machine learning model. Having more data does not hurt machine learning models since it works as a weak form of regularization. Most data-hungry algorithms benefit from more and more data over time.
The implicit risk companies take during this process is worse than the limited amount of labeled data. Individual people who label data incorporate their interpretations and biases into the process. The most impactful problems, where subject matter expertise may be needed, often require domain knowledge and subjectivity that can lead to disagreements amongst experts on what label would be appropriate. You can solve this problem by throwing more and more bodies to provide multiple opinions for each label or adjudication teams to resolve disagreements, but this only compounds the scaling issue that companies face upfront.
Most companies hold their nose and choose to ignore these issues, accepting the risk. Some model risk management teams end up having multiple reviewers for every single label created, but this imposes a huge drag on getting any models into production and limits the value of machine learning for the business.

Programmatic labeling and its impact on end-to-end model governance
Snorkel Flow sidesteps these challenges by using a fundamentally more auditable and reusable type of user input than manual labels: labeling functions. These let subject matter experts build their domain knowledge into a scalable approach to automating data labeling. More importantly, for model governance, programmatic labeling sheds light on data labeling processes and lets organizations inspect or correct bias in the labeling process in a practical way.
Each label can be traced back to auditable labeling functions with programmatic labeling. If data science or model risk management teams find issues or biases with the model, they can map it back to the labeling functions that created it. It’s then straightforward to improve or remove the suspect labeling function and then create a new training dataset in minutes instead of what would typically take weeks or months.
All in all, programmatic labeling lets risk management teams apply the right level of scrutiny to an overlooked part of the modeling process. Usually, teams either need to accept the risks and ignore the flaws in their data labeling processes or impose high costs by adding additional manual inspections to every labeled datapoint. This new data-centric approach to machine learning helps organizations avoid the risk associated with poor performing or biased models without imposing additional burdens on their subject matter experts or data science teams.
To learn more about auditable training data with Snorkel Flow, request a demo or follow us on Twitter, Linkedin, Facebook, or Instagram.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

