Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Data-centric AI: A complete primer
Published: May 17, 2022
Share
The founding team of Snorkel AI has spent over half a decade—first at the Stanford AI Lab and now at Snorkel AI—researching data-centric techniques to overcome the biggest bottleneck in AI: The lack of labeled training data. In this video Snorkel AI co-founder Paroma Varma gives an overview of the key principles of data-centric AI development.
What is data-centric AI?
Machine learning by definition is about data and always has been, but only recently, with the development of powerful push-button mo dels have data science teams shifted their focus to the data. This process, known as data-centric AI, is all about iterating and collaborating on the data used use to build AI systems and doing so programmatically.
But what is the reason for the industry’s increasing focus on data-centricity? A good way to answer that is to start by contrasting data-centric AI with what has been the focus of machine-learning development for many years: model-centric AI.
Traditionally, data science and machine learning teams have focused on model development by iterating on things like feature engineering, algorithm design, and bespoke model architecture. They treat the data as a static artifact and the bulk of the team’s focus is on the model itself.
But as models have become more sophisticated and push-button, AI teams are quickly realizing that focusing on data iteration is as crucial, if not more so, to successfully and rapidly develop and deploy high accuracy models.
Today, machine learning models have simultaneously grown more complex and opaque, and they require much higher volumes of training data. In fact, data has become a practical interface used to collaborate with subject matter experts and turn their knowledge into software. Ultimately, data-centric AI unlocks a higher degree of model accuracy than was possible using model-centric approaches alone.

“There is no need for every organization to develop another large language model. We should move towards leveraging what has been developed and only require some refinement and tuning of the model to make it serve a different business use case.”
Daniel Wu
Head of AI/ML, Commercial Banking, JPMorgan Chase
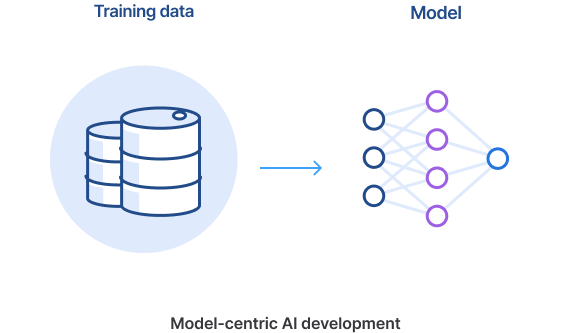
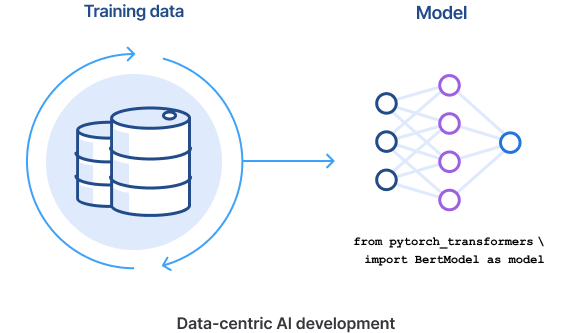
Data-centric AI vs model-centric AI
In the model-centric approach to development, there is frequently the sense that the dataset is something “outside” or that comes “before” the actual AI development process. Data scientists largely consider the training datasets from which their model is learning as a collection of ground-truth labels, and their machine-learning model is made to fit that labeled training data.
This (somewhat caricatured) approach largely treats the training data as exogenous from the machine-learning development process. When, for example, you start your academic experiment against one of the benchmark datasets like ImageNet, your training data is something you download as a comma-separated values (CSV) file. After that, any new iterations of your project result from changes to the model (at least in the broadest sense). This process includes things like feature engineering, algorithm design, bespoke architecture design, etc. In other words, you are really “living” in the model and treating the data as a static artifact.
The tectonic shift to a data-centric approach is as much a shift in focus of the machine-learning community and culture as a technological or methodological shift—“data-centric” in this sense means you are now spending time on labeling, managing, slicing, augmenting, and curating the data efficiently, with the model itself relatively more fixed.
It is also important to stress that this is not an either/or binary between data-centric and model-centric approaches. Successful AI requires both well-conceived models and good data.

“In a data-centric approach, you spend time efficiently labeling, managing, slicing, augmenting, and curating the data, with the model itself remaining relatively more fixed.”
Alex Ratner
CEO and Co-founder
Key principles of data-centric AI
With data-centric AI, data quality and quantity is increasingly the key to successful results. There are three main principles to keep in mind with a data-centric approach:
01
As models become more user-friendly and commoditized, the progress of AI development increasingly centers around agile iterability and quality of training data, rather than around feature engineering, model architecture, or algorithm design.
02
Data-centric AI should be programmatic in order to cope with the volume of training data that today’s deep-learning models require. Manually labeling millions of data points is simply not practical. Instead, a programmatic process for labeling and iterating the data is the crucial determiner of progress.
03
Data-centric AI should treat subject-matter experts (SMEs) as integral to the development process. Including SMEs who actually understand how to label and curate your data in the loop allows data scientists to inject domain expertise directly into the model. Once done, this expert knowledge can be codified and deployed for programmatic supervision.
Data-centric AI as implemented by Snorkel AI is particularly useful for situations where:
- Training data is complex and requires subject matter experts to label.
- Production data or business objectives change frequently requiring models to adapt via retraining.
- Training data is private and outsourcing the labeling task is not an option.
Benefits of focusing on data above all else
Some of the world’s largest organizations have benefited from adopting data-centric AI. Using Snorkel Flow, a data-centric AI application development platform, companies from diverse industries such as banks, biotech, insurance providers, telecommunications, government agencies, and more have seen improvements in developing and deploying deep-learning-based solutions.
A few improvements we’ve seen from the adoption of a data-centric approach include:
01
Faster development: A Fortune 50 bank built a news analytics application 45x faster and with +25% higher accuracy than a previous system.
02
Higher accuracy: A global telco improved the quality of over 200,000 labels for network classification resulting in a 25% improvement in accuracy over the ground truth baseline.
03
Cost savings: A large biotech firm saved an estimated $10 million on unstructured data extraction, achieving 99% accuracy using Snorkel Flow
Use cases of data-centric AI
More recently, the industry has exhibited a major shift toward much more powerful, automated, but also data-hungry machine-learning models. Rather than, say, thousands of free parameters that need to be learned from your data, there are sometimes hundreds of millions. So, despite their power and utility, these models need a great deal more labeled training data to reach their peak level of performance.
A data-centric AI approach has been applied successfully to numerous types of machine learning applications, ranging from classification of and extraction from text, PDFs, HTML, images, time-series, and more.
Data-centric AI as implemented by Snorkel AI is particularly useful for situations where:
- Training data is complex and requires subject matter experts to label.
- Production data or business objectives change frequently requiring models to adapt via retraining.
- Training data is private and outsourcing the labeling task is not an option.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!