Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
How AI speeds patient classification and recruitment in clinical trials
The medical industry is exploding with data. The increasing universality of electronic health records (EHRs), the maturity of genomic data science, and the growing popularity of wearable devices and health apps have created an enormous influx of data for both practitioners and researchers.
Trial clinicians rely on healthcare data including patient demographics, medical records, laboratory results, and imaging data to identify and classify patients for clinical trials. However, manually labeling and analyzing data at any stage of a clinical trial is time-consuming, labor-intensive, and difficult to scale.
Fortunately, AI solutions can help mitigate these challenges.
Leveraging AI for clinical trial efficiency
AI shows promise as a useful technology in clinical trials, particularly in patient recruitment. Poor recruitment practices can cause undue expense, less favorable patient outcomes, and delayed results.
AI tools can expedite recruitment for clinical trials by:
- Automating eligibility analysis and trial recommendations. Manually evaluating electronic health records (EHRs) for eligibility criteria is challenging and time-consuming, but AI can quickly process these complex unstructured documents and help clinicians identify potential participants. AI can even power search engines for trial matching.
- Improving identification accuracy to help ensure that only eligible patients are enrolled in clinical trials. This can also improve patient safety by identifying patients who may be at risk of a particular course of treatment.
- Streamlining multimodal data from disparate sources to match patients with complex inclusion criteria. Natural language processing (NLP) and computer vision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types.
Trial clinicians face challenges in adopting AI, such as complex and changing criteria for patient inclusion or exclusion. The language for eligibility criteria is not standardized, and data sources can be dense and unstructured. This leads to a lack of quality datasets with which to train AI models, which can also be an expensive and labor-intensive process.
How LLMs can be customized for clinical trials
Foundation models (FMs) such as large language models (LLMs) can accelerate the development of accurate, time-saving AI applications for clinical trials.
Out of the box, generic LLMs may struggle to address specific use cases. However, by fine-tuning on a relevant dataset, they can adapt to new tasks, including those relevant to patient recruitment.
Data scientists can also distill their processing power into small and less expensive models should they need to run at high throughput.
There are limitations to using LLMs in clinical scenarios. Pre-trained LLMs can be limited by the low quality of their data sources and struggle to adapt to domain-specific tasks. They can be limited in their multi-modality, and they can be difficult to explain, adapt, or control.
The inherent sensitivity of healthcare data can also raise serious concerns about privacy when using public APIs. Additionally, developing or hosting a proprietary foundation model can be prohibitively expensive due to computation costs.
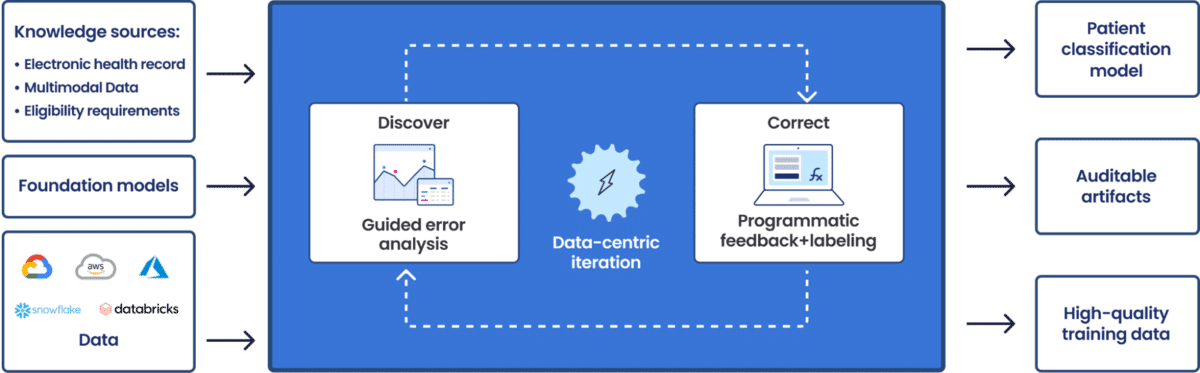
For clinical trials, LLMs customized with Snorkel Flow can:
- Provide an initial source of label signal. High-quality training data is essential to AI success, but hand-labeling is expensive and labor-intensive. Clinicians can create, layer, and refine prompt-based labeling functions to tap the models’ cumulative knowledge.
- Adapt to specific tasks. LLMs can be fine-tuned to address particular needs, like facilitating cohort selection by reviewing medical records. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process. High-quality training sets are essential to this customization.
How Snorkel AI improves patient inclusion/exclusion analysis
Snorkel AI takes a data-centric approach to simplify customizing AI applications and significantly reduce the time needed to build training sets and fine-tune models. Snorkel natively integrates closed-API models such as GPT-3.5 and open-source FM/LLMs like BERT or Llama 2, and others —pulling their predictive power into a secure, easy-to-use platform.
Users can leverage these state-of-the-art AI models as launchpads for their own mini-models, tailored to their specific needs and data.
With Snorkel Flow, trial clinicians can:
- Quickly and programmatically label training sets. Snorkel combines data-centric AI and weak supervision to massively reduce manual data labeling while improving accuracy.
- Distill the power of gigantic foundation models into low-resource and governable deployment models.
- Develop iterative workflows to continuously improve and update models and label schemas.
- Adapt and refine models to changing conditions and criteria with enhanced explainability.
When production-ready, clinicians can deploy their custom models securely on-premises or in the cloud. Snorkel partners with leading cloud providers like AWS, Google Cloud, and Microsoft Azure, and our own cloud offers enterprise-grade security and is SOC-2 certified.
Create Custom AI for Clinical Trials with Snorkel
Many in the medical community agree that proper management, analysis, and stewardship of data are essential to providing comprehensive and sufficient healthcare. As technology evolves, the medical community must endeavor to evolve its data management and analysis practices alongside it. This holds true in the case of clinical trials.
AI tools show great promise in improving patient recruitment efforts for clinical trials, but clinicians can struggle to tailor and launch out-of-the-box tools efficiently. LLMs can be fine-tuned with high-quality datasets to address a wide range of recruitment challenges, but creating the necessary training sets by hand is expensive, labor-intensive, and prone to human error.
Snorkel helps trial clinicians and data scientists quickly and programmatically label large training sets with high accuracy using weak supervision and iterative data development processes.
Ready to learn more about how you can expedite clinical trial recruitment and patient classification with Snorkel AI? Chat with us today!
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Team Snorkel