
We are thrilled to announce the latest edition of Snorkel Flow, our platform to rapidly build, manage, and deploy predictive AI applications (e.g., classification, information extraction) using programmatic labeling, fine-tuning, and distillation.
This new release eases the process of creating new applications in Snorkel Flow and tightens the iteration loop with new tools to sort, edit and understand labeling functions. It also boasts upgraded security certifications and new beta features aimed at making the platform more useful and powerful than ever.
Our focus in this release was to optimize data-centric iteration, advance foundation model workflows, and enhance enterprise readiness, all while incorporating significant customer feedback. This post will dive into more detail about all of the above along with other exciting new features.
Latest features and platform improvements for Snorkel Flow
Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. Its main goal is to speed up the development and deployment of AI models for predictive AI applications that are focused on the classification and extraction of unstructured and semi-structured text such as raw text, PDF, conversations, web data, and more.
Snorkel Flow primarily achieves this by allowing users to label, build, and manage training data more efficiently, enabling rapid iteration and deployment of models. It leverages weak supervision and programmatic labeling methods to generate training data. This process involves creating labeling functions that programmatically label data, which can be particularly useful when data is private, complex, or fast-changing.
The platform includes capabilities for guided model development, training, evaluation, and deployment, making it possible for AI practitioners and data scientists to develop, manage, and deploy machine learning models 10-100x faster.
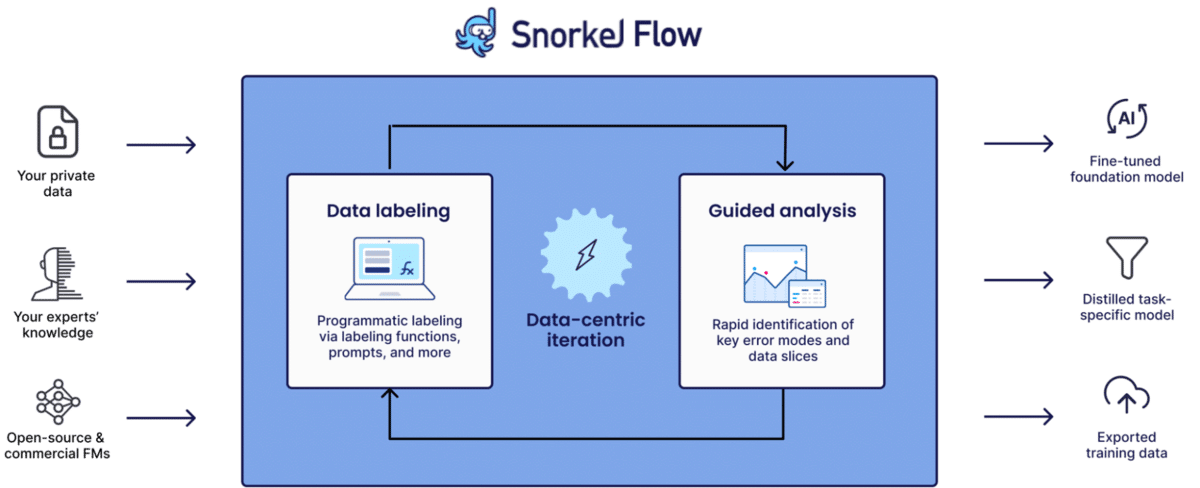
Caption: Snorkel Flow powered by programmatic labeling and LLMs
Improved Labeling Function (LF) Management
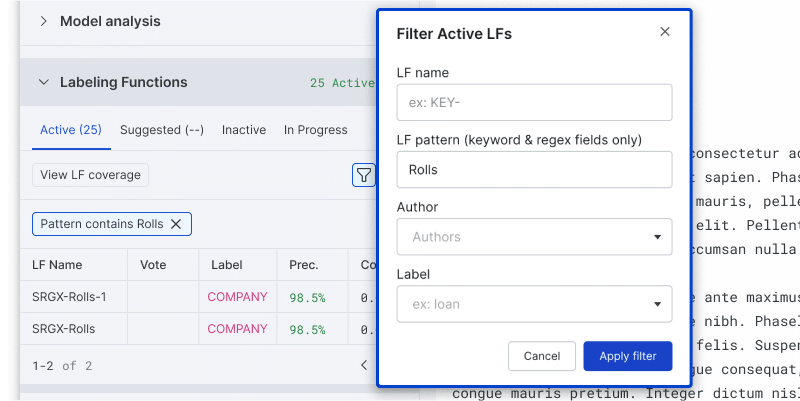
The number of labeling functions generated for any given project can be in the thousands, and managing such a large set can become quite a challenge. Therefore, we’ve revamped the interface to provide a fully featured management experience to navigate through labeling functions, ensuring a seamless user experience across the board. This is especially helpful for classification across many classes, where users tend to write more LFs.
Here’s what we’ve rolled out:
- LF Filtering: Looking for a particular LF? Our new filtering function allows you to find LFs based on name, pattern, author, or label. Less time searching means more time for creating top-notch LFs.
- One-Click LF Rename: We’ve introduced a one-click renaming feature for LFs to enhance usability. It’s all about giving you more control!
- LF Pop-out View: We’ve designed a pop-out feature to offer a comprehensive view of your active LFs. It allows you to dive deep into each LF and understand it in detail.
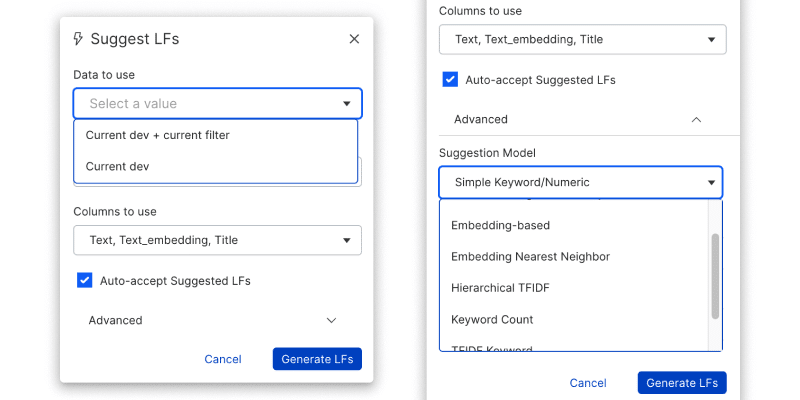
Intelligent Auto-Suggest Strategies for Labeling Functions
You can now target specific error hotspots using slice-based suggestions. Plus, you can curate suggested LFs faster using a new LF quality ranking. For advanced classification applications, you can now leverage new and improved suggestion models.
Streamlined annotation experience
As part of our commitment to continuously improve and innovate, we have significantly streamlined our sequence tagging annotation workflow in this new release of Snorkel Flow. Our new approach is aimed at making the annotation process more intuitive and efficient for our users. To achieve this, we’ve embedded Ground Truth (GT) labels directly into the workflow, which can be viewed inline during data annotation. This improvement eliminates the need to memorize color codes, enhancing the user’s focus on the task.
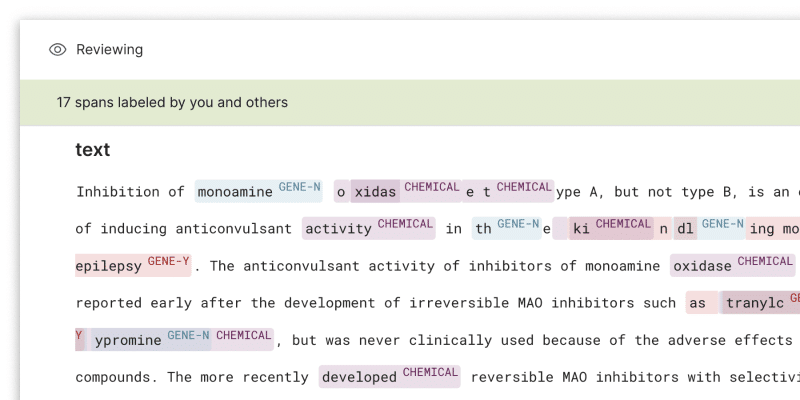
Moreover, we’ve integrated a much-demanded feature within our sequence tagging applications—the ‘find’ command, or Command F. This makes navigating data simpler and less time-consuming. It’s an especially valuable tool for high-velocity teams deploying intricately fine-tuned models at scale.
Foundation Model Suite (Beta): Stability & Usability Improvements
We have incorporated feedback from customers during our private beta rollout to improve usability and fix bugs. Furthermore, we have implemented easier LF management and introduced a range of SDK tools for advanced FM warm start capabilities.
And for our AI developers and practitioners, we’re also including a new set of opt-in only SDK tools. With the new SDK, you can warm up your classifiers and information extractors with GPT-4, tailor FM features to various use cases—and more—all directly from your notebook.
Full SOC2 Type 2 and HIPAA compliance
We are thrilled to share that Snorkel Flow has successfully secured the SOC2 Type 2 certification. This significant achievement underscores Snorkel’s rigorous commitment to upholding robust security practices and safeguarding customer data. The certification validates that Snorkel consistently meets strict standards related to security, availability, processing integrity, confidentiality, and privacy. Furthermore, it highlights Snorkel’s robust data security stance and underlines our unwavering dedication to adapting with ever-evolving technology infrastructure, compliance norms, and regulatory standards. The accomplishment, backed by a thorough audit, solidifies Snorkel’s resolve to ensure uncompromised data security.
Streamlined Data + Task Onboarding (Beta)
Our new onboarding wizard offers a guided experience to upload data, define the problem, preprocess data, and kickstart development. We’re making it easy for users to walk through the key steps for a new application in Snorkel Flow, coupled with guardrails to ensure ML best practices.
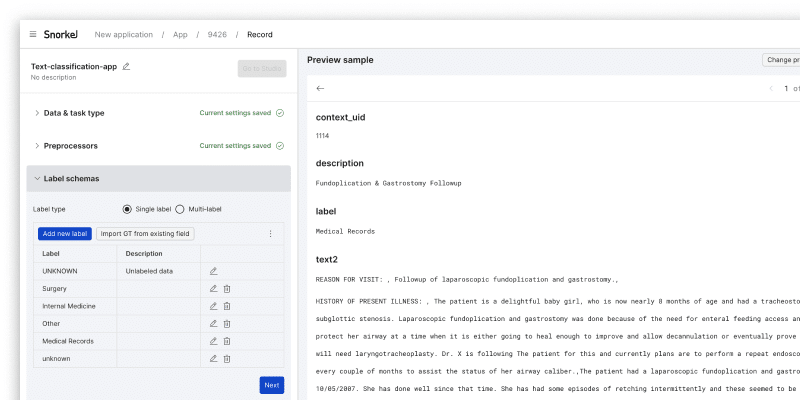
The onboarding experience also includes self-serve guardrails, such as in-app limits, warnings, and blockers to assist with process control and error prevention. These guardrails help users manage the data upload and pre-processing stages more effectively with ML best practices in mind. They also efficiently manage long-running jobs—often a bottleneck in data science projects. Users are provided with real-time updates about the status of these tasks and can easily control them, ensuring that their work progresses smoothly and without interruption.

With Snorkel Flow Summer 2023 release, we continue to empower enterprises in their AI development journey. The new features and enhancements discussed above represent our commitment to simplifying and expediting your AI workflow. From newly added self-serve onboarding to LLM-powered labeling, optimized PDF pre-processing, improved FM Suite stability, and streamlined annotation experiences, Snorkel Flow Summer 2023 Release is designed to make AI development faster, more efficient, and more accessible than ever before.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

