Financial institutions constantly innovate new ways to accurately determine the creditworthiness of potential borrowers. Artificial intelligence and machine learning (AI/ML) offer new avenues for credit scoring solutions and could usher in a new era of fairness, efficiency, and risk management.
Traditional credit scoring models rely on static variables and historical data like income, employment, and debt-to-income ratio. However, these formulas fail to account for the complex modern financial ecosystem. Some critics also call traditional credit reporting error-ridden, biased, and exclusionary.
Traditional credit scoring needs an upgrade
Three-digit credit scores are still the status quo and industry standard. Many lenders and credit bureaus, however, turn to AI to improve how they evaluate potential borrowers’ credibility.
Historically, credit scoring has been:
- Rule-based and inflexible
- Prone to human delay, bias, and error
- Based on select historical data points (i.e. mortgage payments) to the exclusion of others (i.e. rent payments)
These financial profiles are, by nature, limited in scope and fail to incorporate the enormous volume of data available about potential borrowers. Fortunately, financial institutions and credit bureaus are already using ML and AI to make credit scoring more efficient and accurate.
Delivering truly fair and precise credit scoring with AI
For more than two decades, credit scoring giant FICO® and the wider financial industry have worked to improve credit scoring processes with AI. AI has already been shown to improve loan performance and efficiency both by reducing non-performing loans and boosting returns, and there are still many opportunities to explore in this area.
AI’s predictive power rises to the complex challenge of creditworthiness, empowering lenders to:
- Quickly process tabular data. AI can rapidly classify, organize, and synthesize tabular financial data. ML can significantly reduce the time necessary to pre-process customer data for downstream tasks, like training predictive models.
- Supercharge predictive modeling. Lenders and credit bureaus can build AI models that uncover patterns from historical data and then apply those patterns to new data in order to predict future behavior. Instead of the rule-based decision-making of traditional credit scoring, AI can continually learn and adapt, improving accuracy and efficiency.
- Expand data points to paint a broader financial picture. Financial institutions can train custom ML models on a variety of data points, both traditional and non-traditional. Experimenting with different criteria, weights, and validation sets can help provide a more comprehensive picture of a borrower’s creditworthiness. Enriching consumer profiles can reduce default risk and identify opportunities for higher returns.
- Uncover and correct for bias in existing credit scoring models. Lenders and researchers can use AI to analyze traditional credit models and identify variables that are having a disproportionate impact on certain groups of borrowers. ML models can then be trained to account for known biases, intentionally improving objectivity and fairness in lending decisions.
Custom AI models offer unprecedented opportunities for lenders to control their creditworthiness criteria. Some may choose to experiment with non-traditional data sources like digital footprints or recurring streaming payments to predict repayment behavior.
How foundation models jumpstart AI development
Foundation models (FMs) represent a massive leap forward in AI development. These large-scale neural networks are trained on vast amounts of data to address a wide number of tasks (i.e. natural language processing, image classification, question answering). Financial institutions, credit bureaus, and researchers can also build upon FMs to tackle specific downstream tasks, like determining creditworthiness.
Lenders can use FMs to amplify AI credit scoring efforts to:
- Increase interpretability. FMs can even transform dense tabular data into digestible consumer profiles. Data scientists can train large language models (LLMs) and generative AI like GPT-3.5 to generate natural language reports from tabular data that help human agents easily interpret complex data profiles on potential borrowers.
- Improve the accuracy of credit scoring predictions. Pre-trained FMs can help supercharge pattern detection in the borrower’s income or spending habits that traditional credit scoring models may not capture.
- Speed and enhance model development for specific use cases. Data teams can fine-tune LLMs like BERT, GPT-3.5 Turbo, and LLama to jumpstart custom models that address creditworthiness. These could be risk prediction models, future earning models, or robust consumer profiles that incorporate traditional and alternative data.
While FMs hold powerful potential in credit scoring, they also present challenges. Third-party FMs are expensive to use at scale, and funneling consumer financial data through an open-access foundation model raises serious privacy concerns. Hosting a foundation model or building one from scratch is also no small feat; their massive sizes necessitate enormous computing and data science resources.
Snorkel AI streamlines custom AI credit scoring development
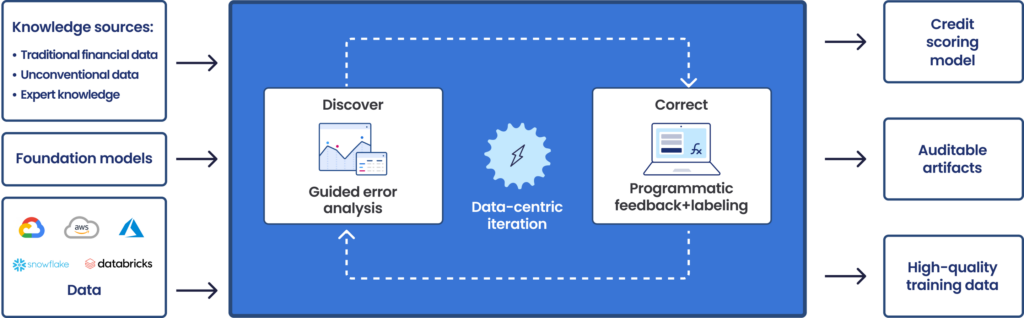
Snorkel offers a data-centric AI platform where lenders and credit agencies can build and train custom AI applications that deliver enhanced accuracy while minimizing manual efforts.
Credit-scoring AI tools require high-quality representative data to learn from, but manually labeling training data is slow, expensive, and can easily bottleneck AI development. AI credit scoring solutions may also have low explainability, making it difficult to understand why models make certain predictions and decisions, and how to correct errors or adapt to changing schema and conditions.
Lenders and credit agencies can use Snorkel to:
- Quickly and programmatically develop training data for credit scoring models. Snorkel Flow enables programmatic data labeling, eliminating the need for manual labeling which is a common AI bottleneck. Snorkel users can leverage weak supervision to quickly and accurately label large quantities of training data.
- Improve auditing, model explainability, and iteration. Credit scoring models must be monitored and fine-tuned to ensure fairness and accuracy. Snorkel Flow makes it easy to update programmatic labels, understand why models make decisions, and adjust them to enhance accuracy and accommodate new market conditions.
- Distill FMs into deployable mini-models. Snorkel’s secure platform integrates with best-in-breed FMs, both open-source and closed-API. Users can fine-tune pre-trained FMs like FinBERT, Palm 2, or LLama 2 and distill them into smaller, custom models that address specific credit score challenges like identifying patterns in the borrower’s spending habits or predicting their likelihood of default.
Once trained, these custom models can be deployed on-premises or in the cloud at a fraction of the computational cost of their multi-billion parameter parent models. Snorkel offers enterprise-grade security in the SOC2-certified Snorkel Cloud, as well as partnerships with Google Cloud, Microsoft Azure, AWS, and other leading cloud providers.
Building better credit scoring with Snorkel AI
AI can be a powerful tool in making credit scoring more accurate for lenders and fair for borrowers. Lenders, credit reporting agencies, and researchers can use AI to identify patterns, build predictive models, and address many of the issues inherent to traditional credit scoring.
Many lenders and credit agencies are looking at the generative power of foundation models to address common credit scoring challenges. While “black box” FMs may be too general to address specific tasks like determining creditworthiness, data scientists can fine-tune these models to produce useful, deployable models faster than ever before.
Snorkel’s data-centric approach and user-friendly platform can vastly simplify the training and deployment of credit-scoring models. Snorkel makes it easy to improve training data quality, build custom AI apps, and distill their predictive power into production-ready mini-models.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.
