
Enterprise generative AI applications will likely surge toward production this year, according to survey results collected at our most recent Enterprise LLM Summit event.
Survey participants told us that their organizations had few generative AI (GenAI) applications in production in 2023, but expected to have at least one (and possibly many!) in production by the end of 2024. They also indicated that they expect their firms to focus primarily on computer vision tasks, and signaled that they believe collaboration between data scientists and subject matter experts (SMEs) is crucial to LLM development.
Let’s take a deeper look at the results.
Enterprise GenAI 2024: more coming soon!
Our survey found strong expectations for organizations to expand their arsenal of LLM-backed applications.
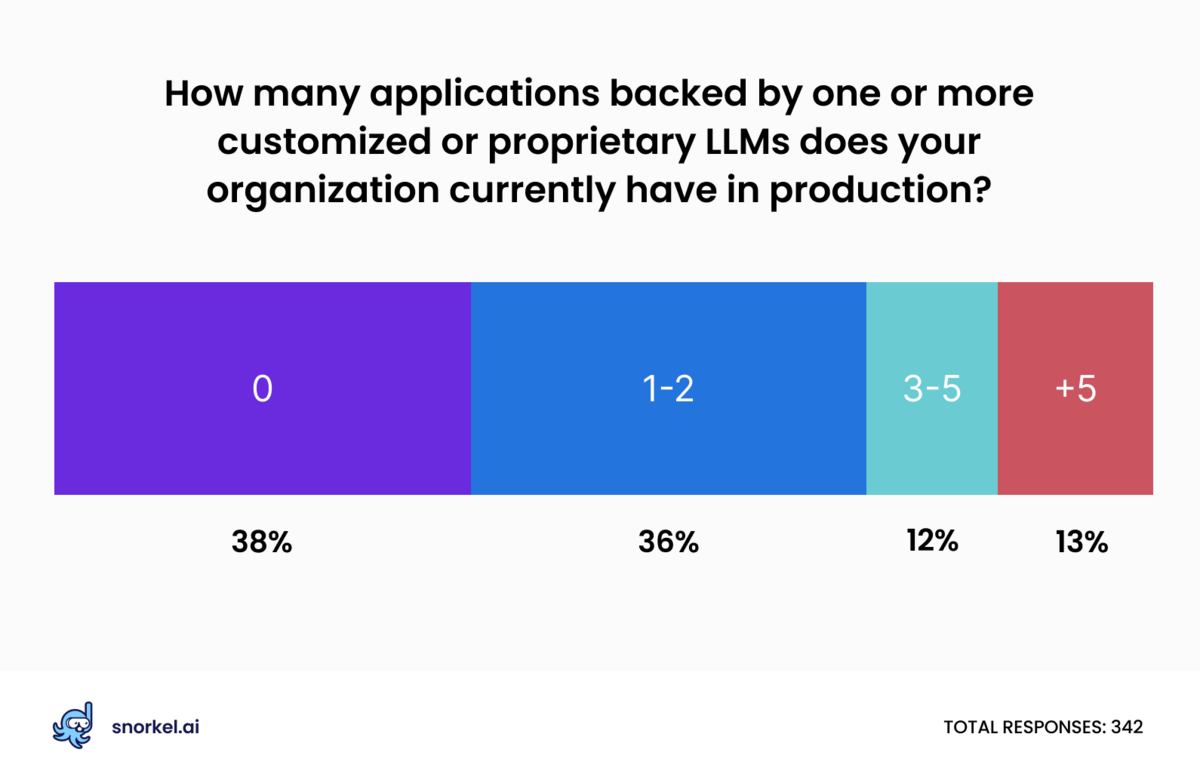
About 38% of respondents indicated that their organization currently has zero applications backed by customized or proprietary large language models (LLMs) in production. Only 7% of respondents expected that to be the case at the end of 2024.
We divided our survey audience into two groups: those at organizations with more than 10,000 employees and those at smaller organizations. Small and big company trends mirrored each other on the questions of how many LLM applications they currently have and how many they expect by the end of the year, though the details differed. A smaller share of respondents at large organizations said they had no applications backed by customized LLMs currently in production (29% vs 43%), and many more respondents at large companies said their organization had more than five such applications in production (27% vs 5%).
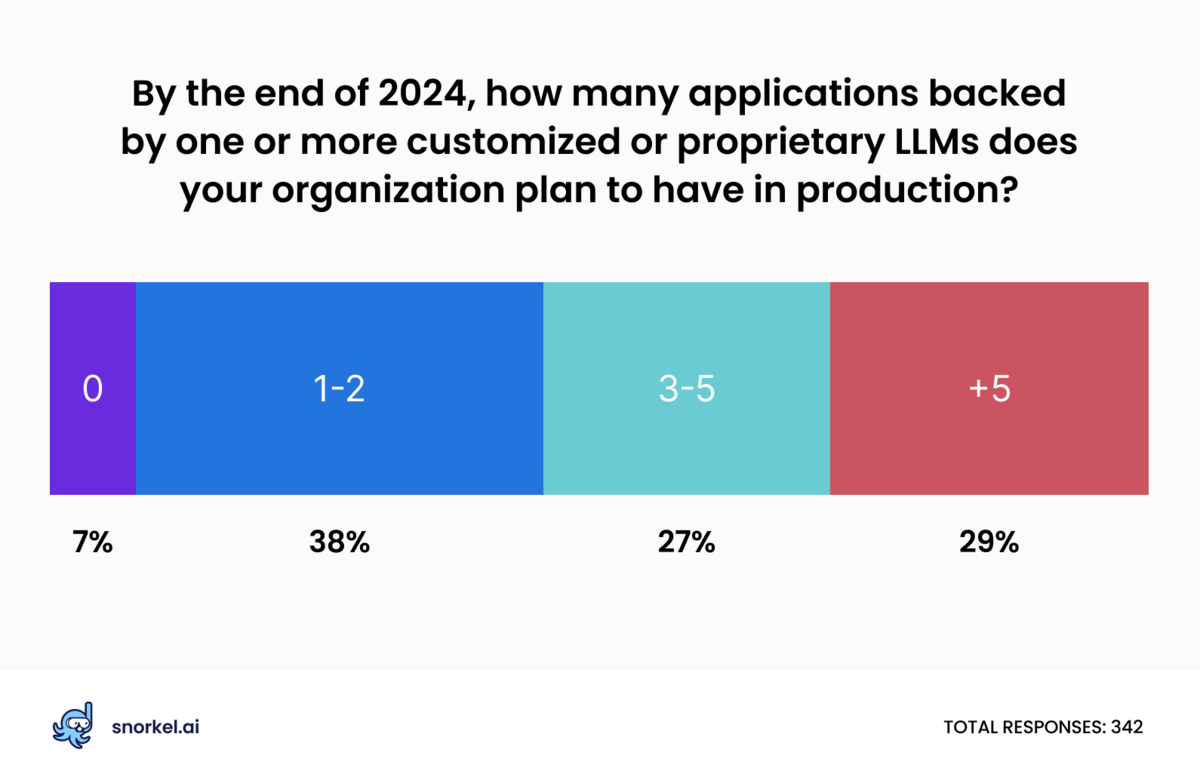
That intensity carried through to each group’s predictions for the end of 2024: 69% of our respondents at large organizations said they expected to see three or more custom-LLM-backed applications in production, compared to 47% at smaller firms.
While our respondents signaled high hopes (as might be expected for an audience at an Enterprise LLM Summit), those projections likely exceed what most companies will achieve by the year’s end. Gartner last year placed GenAI at the peak of their “Hype Cycle.” This high point immediately precedes the “Trough of Disillusionment,” which Snorkel CEO Alex Ratner said he believed global industry is currently plunging into.
Enterprises already building real, valuable applications with GenAI (we’ve helped some of them do it), but many of our respondents will likely look back at their predictions next year and find they were overly optimistic.
Data scientist + SME collaboration: crucial to LLM development
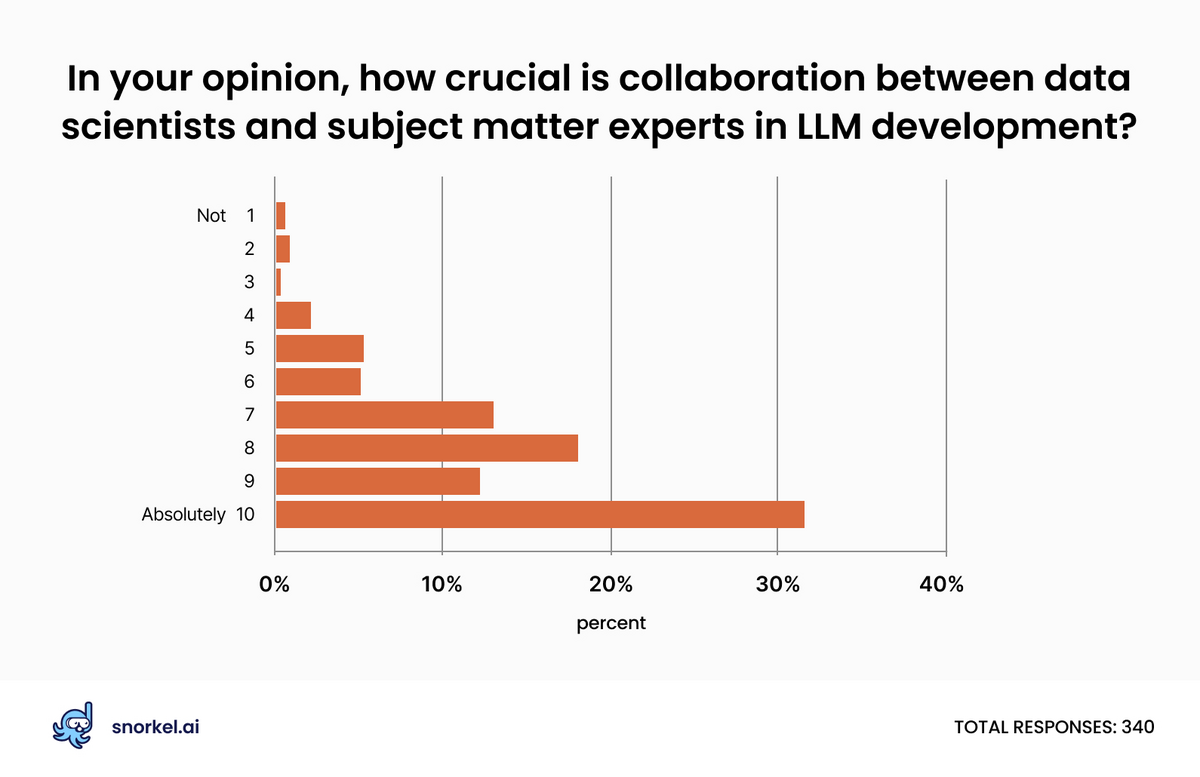
In a stark result, the vast majority of survey respondents indicated that SME and data scientist collaboration was crucial to developing LLMs. Nearly 36% of respondents gave the statement a ten out of ten on the agreement scale, and 84% gave it a 7 or greater.
Those numbers were slightly higher at large enterprises (39% at ten and 87% at 7 or greater), but still strong at smaller enterprises (34% at 10 and 83% at 7 or greater).
Regardless of the details, that result suggests that the audience at our Enterprise LLM Summit strongly agrees with one of Snorkel’s core principles: data scientists can’t develop production-quality AI applications on their own, and neither can SMEs.
Top priority: computer vision
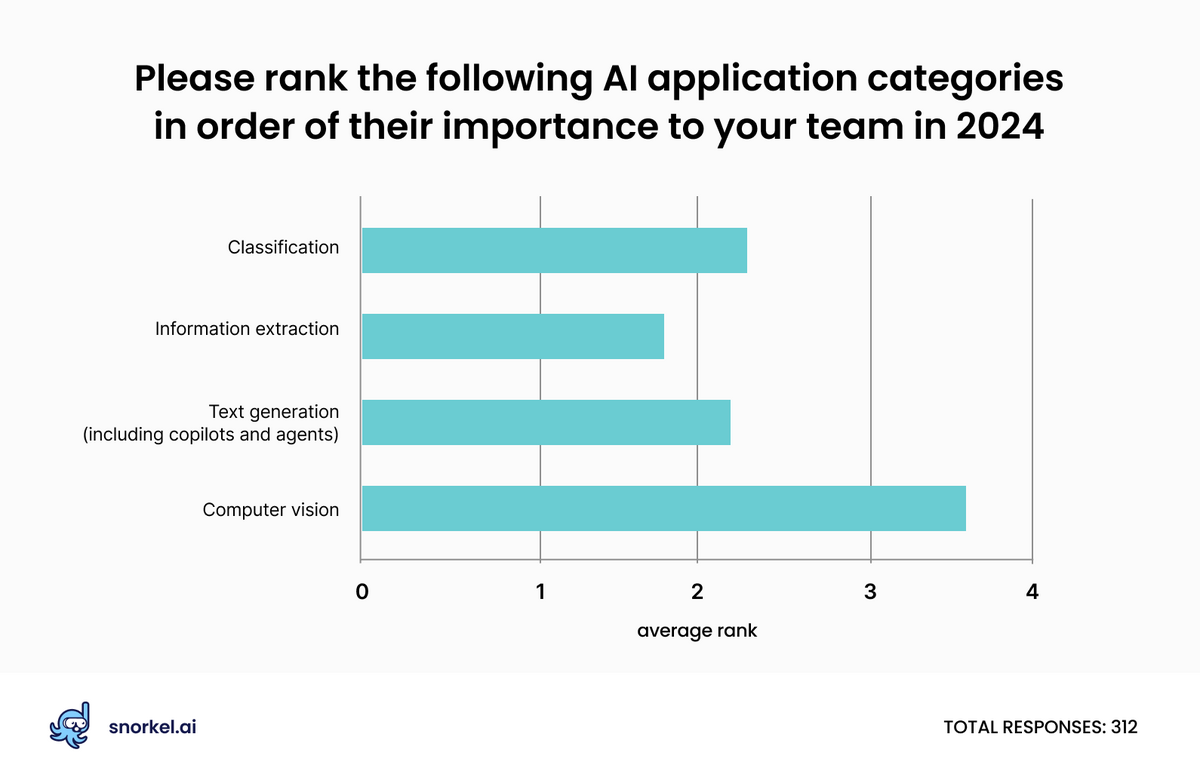
The vast majority of respondents (77%) named computer vision as their top priority for AI applications in 2024—a number that was significantly higher among respondents from large organizations (86%) than for smaller ones (72%).
(Related: Snorkel partnered last year with Wayfair to buid highly-succesful computer vision applications.)
Respondents displayed the least interested in information extraction. A total of 41% of respondents ranked information extraction as the least important AI application for them in 2024. While this event’s audience was not excited about information extraction applications, several Snorkel customers have created significant business value through IE applications.
Evaluation: benchmarks above all—but narrowly
When asked how their organizations evaluated LLMs, 40% said they used benchmarks. That percentage narrowly topped “quantified user feedback” at 39%, but a higher percentage of survey takers used only benchmarks than used only quantified user feedback (17% vs 13%). Another 10% said that they evaluated LLMs through both benchmarks and quantified user feedback, which was greater than the percent who used benchmarks and quantified human feedback in addition to anecdotal human feedback.
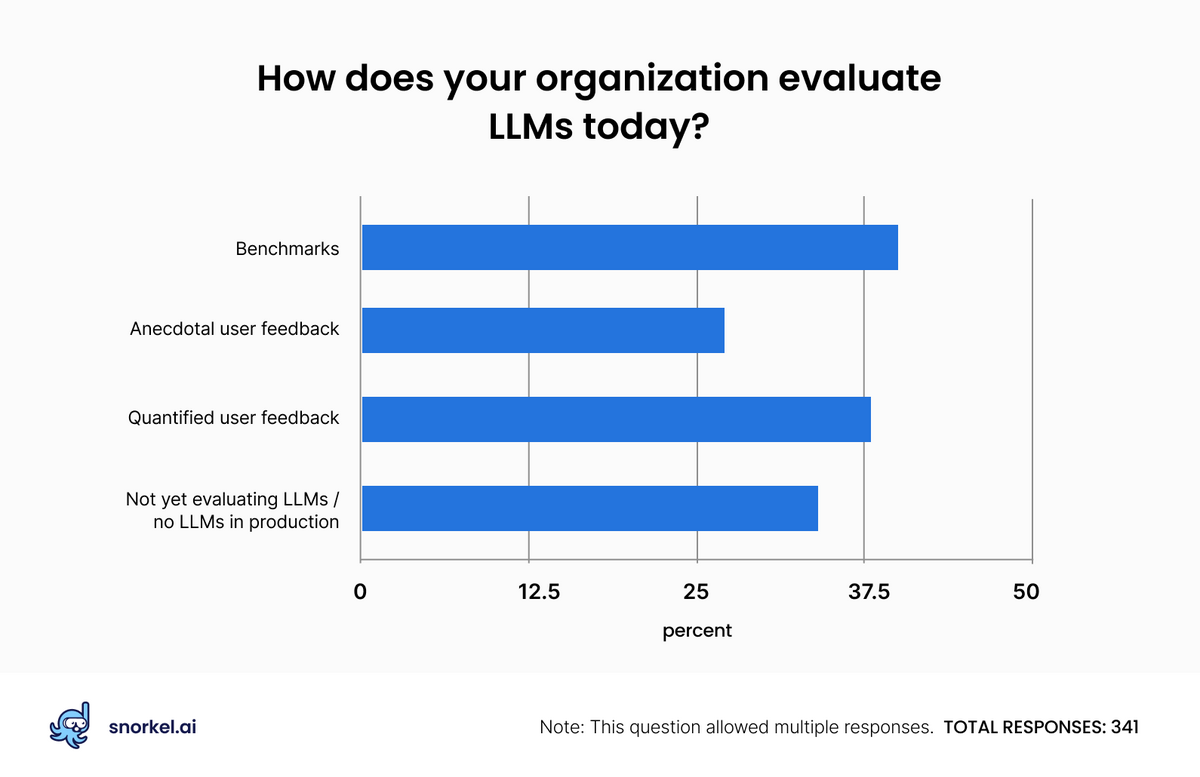
While anecdotes can be a useful way to investigate LLM performance (not all meaningful product experiences easily lend themselves to numeric values), it is perhaps distressing that 8% of respondents said they evaluate LLMs only through anecdotal user feedback.
Another 32% of respondents said they either had no LLMs in production or were not evaluating those that they did have in production.
Enterprise GenAI 2024: surging through the trough?
Some amount of GenAI disillusionment is on the horizon; with the amount of hype the technology gathered last year, that’s unavoidable. But it appears that pragmatism is working its way in—at least for the audience at our Enterprise LLM Summits.
The response data above suggests sobriety toward the topic; a stunning majority realize that LLM customization demands collaboration, which suggests they no longer expect LLMs to perform miracles. Our audience also placed benchmarks and quantifiable user feedback well above anecdotes for assessing the models they aim to use in their businesses. While the quantity of generative applications our attendees predicted for their enterprises will likely turn out to be optimistic (and perhaps overly so), the intensity of that optimism suggests that this technology will be deployed in their organization.
As large enterprises deploy GenAI applications, they will get a better grasp on how to squeeze value from it, pushing them—perhaps quickly—up Gartner’s Slope of Enlightment and into the plateau of productivity.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Matt Casey
Data Science Content Lead
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

