
In my capacity as a machine learning researcher, I’ve observed a profound paradigm shift in the field of AI development. We are transitioning from a focus on the models and algorithms that underpin AI to a greater emphasis on the data that powers these models.
In the enterprise context, where complex, domain-specific data is often the norm, this shift is particularly salient. This evolution in our approach, which places data at the forefront, is what we now refer to as data-centric AI development, and it’s particularly important as enterprises move into the next phase of the hype cycle. We’ve seen a lot of engineers build flashy demos in the last year by using python code to glue LLM APIs to vector databases, but those flashy demos fall short when it’s time to move to production. The key to bridging that gap lies in data development.
I recently expressed my thoughts at my company’s Enterprise LLM Summit: Building GenAI with Your Data in a keynote address I titled: “Your enterprise will succeed or fail in AI depending on how you use your data.” I would encourage you to watch the whole presentation for extra commentary (embedded below), but I’ve put together this summary.
The importance of data (and programmatic data development)
Data is the new frontier in AI. It’s no longer just about developing algorithms; it’s about developing the data that goes into these algorithms. This approach is particularly crucial for large-scale models with billions of parameters, where data effectively becomes their programming interface.
In the past, data was a janitorial thing that AI people “didn’t do.” You downloaded ImageNet, or you got a spreadsheet from a line of business team or some outsourced Mechanical Turkers. And then you started your real work as a data scientist tweaking and tuning and developing models and algorithms.
In the era of foundation models ahead of us that’s basically dead. Data scientists will need to have a hand in developing data. A lack of properly prepared data presents the biggest blocker for enterprise AI projects, and programmatic data development presents the most practical answer to clearing this bottleneck.
Our perspective on this has remained consistent over the last decade, starting with the Snorkel project at Stanford and continuing through our ongoing work on Snorkel Flow, the AI data development platform. We believe that programmatic approaches to data development are critical for actually productionizing and customizing AI.
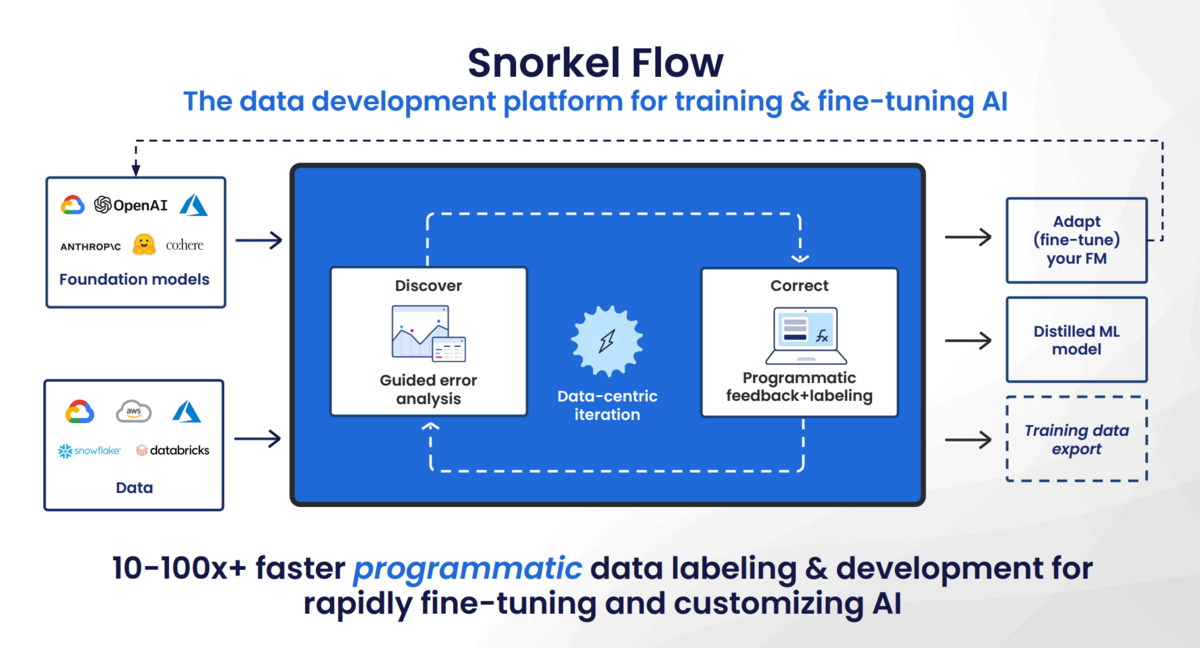
Understanding programmatic data development
Programmatic data development is about elevating the process from manual, one-data-point-at-a-time labeling, to developing data operators that perform labeling, filtering, and sampling operations as code functions. These functions can be written quickly, applied to large volumes of data, inspected, weighted, and optimized. This approach replaces the traditional manual and ad hoc decision-making process with a more streamlined and efficient method.
This strategy bears similarities to software development, making data development more organized, more auditable, and much faster. We’ve observed users with our tools get to a final data training set ten to a hundred times quicker than they could have with manual tools.
This approach also offers increased efficiency and adaptability. Programmatic data development allows for rapid iterations, making it possible to quickly identify and address errors or inefficiencies in the data. This not only accelerates the development process but also enhances the accuracy and reliability of the data being used.
One of the most exciting aspects we’ve observed is the innovative ways users have applied programmatic data development. Some have used it to automate data labeling, freeing up valuable time and resources. Others have used it to filter out irrelevant or redundant data, ensuring that their models are trained on the most relevant and high-quality data. Additionally, we’ve seen users apply this approach to optimize data sampling, ensuring a more balanced and representative dataset for their models.

How programmatic data development on Snorkel Flow works
Snorkel Flow is a prime example of a platform that fully embraces a data-centric approach in AI development. It provides a comprehensive and iterative method for users to start with any large language model (LLM), identify subsets of data where the model makes errors, and correct those errors via programmatic data development.
The data-centric AI development process in Snorkel Flow involves several steps. In our most common workflow, a user Initially selects a foundation model and constructs a generic prompt, the output of which acts as the baseline for further development. As the user identifies areas where the foundation model underperforms or makes errors, they employ programmatic data development to make corrections. This could involve prompting, adjusting the data mixture by sampling or filtering, or even adding new data via augmentation or synthetic data generation.
Programmatic data development in Snorkel Flow is achieved by writing functions either via code or no-code interfaces. This allows for rapid iteration and flexibility, enabling users to quickly adjust their models according to the unique requirements of their specific use cases.
The effectiveness of Snorkel Flow can be seen through its real-world applications.
Banking chatbot intent predictor: more accurate at 10,000x smaller
One of our engineers recently completed a case study based on a use case we’d seen from our banking customers. The task required a model to identify the intents of unstructured text entered into a chatbot. Our engineer initially applied a basic LLM, which resulted in an F1 score of 50.
After employing Snorkel Flow for programmatic data development, they trained a model thousands of times smaller that achieved an F1 score of 88. This represents a significant 38-point improvement in a format that would cost a tiny fraction as much to run at inference time.
Banking legal document RAG system: 54-point accuracy gain
One of our baking customers aimed to build a generative application to extract necessary insights from unstructured legal documents. They started with a basic system: GPT-4 plus a basic retrieval augmented generation (RAG) pipeline. When we first encountered the application, it was about 25% accurate on their problems.
This was complex data, and they needed high accuracy. This 25% wouldn’t cut it.
By fine-tuning several parts of the system with programmatically curated data, our team was able to increase the system’s accuracy to 79% in just three weeks. That was just the first sprint. In later work, we further boosted the system’s accuracy to 89%—a 64-point accuracy gain, and an overall 350% improvement.
Your data: the key to your business’ success (or failure)
The key takeaway from all this is that data development is the cornerstone of making AI work. For enterprise practitioners working with complex, domain-specific data, adopting a data-centric approach in AI and machine learning development is not just a nice-to-have; it’s a necessity.
In many ways, this shift to data-centric AI development is about specialization. It’s about using your data, curating it, and tuning models to perform on it, rather than just using out-of-the-box models.
As we continue to move in this direction, I believe we’ll see more enterprises realizing the value of this approach and making data development a first-class operation in their AI development process.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Alex Ratner
Co-Founder & CEO, Snorkel AI
Alex Ratner is the co-founder and CEO at Snorkel AI, and an affiliate assistant professor of computer science at the University of Washington. Prior to Snorkel AI and UW, he completed his Ph.D. in computer science advised by Christopher Ré at Stanford, where he started and led the Snorkel open source project. His research focused on data-centric AI, applying data management and statistical learning techniques to AI data development and curation.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

