We created Data-centric Foundation Model Development to bridge the gaps between foundation models and enterprise AI. New Snorkel Flow capabilities (Foundation Model Fine-tuning, Warm Start, and Prompt Builder) give data science and machine learning teams the tools they need to effectively put foundation models (FMs) to use for performance-critical enterprise use cases. The need is clear: despite undeniable excitement about FMs, Gartner found less than 5% of enterprises have them in production today.
Given our roots in the Stanford AI Lab, we don’t launch anything without doing the research to validate the impact. The Snorkel AI Research team (along with our academic partners at Stanford University and Brown University) set up an experiment to understand if and how Data-centric Foundation Model Development in Snorkel Flow could help enterprises adopt foundation models. We hypothesized it would address the two primary blockers to enterprise FM adoption: adaptation (creating enough training data to fine-tune generalist FMs against domain-specific tasks) and deployment (ability to put FMs into production within cost and governance constraints). You can learn more about these challenges in our announcement post.
While we expected our hypothesis to bear out, the magnitude of the impact across quality and cost surprised our team. We took on a complex 100-way legal classification benchmark task, and with Snorkel Flow and Data-Centric Foundation Model Development, we achieved the same quality as a fine-tuned GPT-3 model with a deployment model that:
- Is 1,400x smaller.
- Requires <1% as many ground truth (GT) labels.
- Costs 0.1% as much to run in production.
Now let’s take a closer look at how we arrived at Data-centric Foundation Model Development before we dive into the case study method, experimental design, and results.
Why Data-centric Foundation Model Development?
Most foundation model advancements have come from the data they’re trained on. Perhaps the best-known large language model, GPT-3, set this in motion by proving that by training on massive amounts of data (in this case, open web text), you can create a model with an unprecedented ability to solve NLP problems (especially those that are generic enough to be answered by the internet). This core insight—that the secret sauce is in the data—continues to be true as the latest FMs like BLOOM (Le Scao et al., 2022), OpenAI Whisper (Radford et al., 2022) use roughly the same architectures but differ in their creatively curated training data sets.
Observing that data is the key to FMs—as it is with AI at large—we set out to apply the data-centric AI practices we’ve pioneered over the past 7+ years to this latest breakthrough of foundation models. After a year of R&D and validation in partnership with customers, the outcome is Data-Centric Foundation Model Development, which makes FMs dramatically more accessible for the enterprise in two key ways:
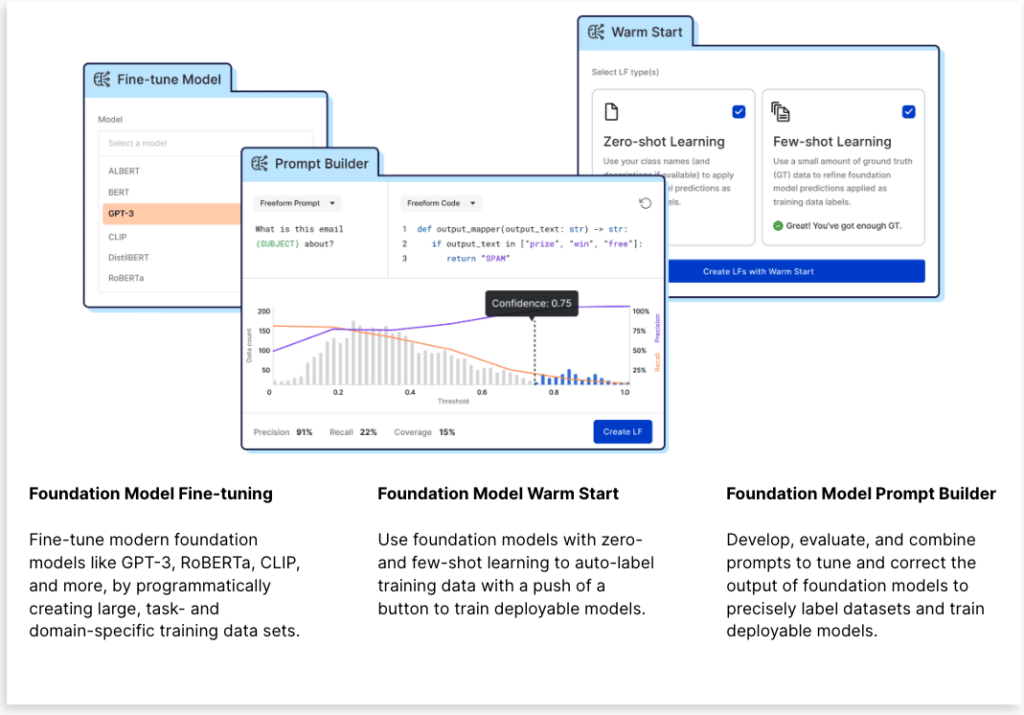
- Adapt foundation models radically faster by eliminating the bottleneck of training data creation across complex, domain-specific data. We do this using core Snorkel Flow programmatic labeling and data-centric development capabilities and now offer Foundation Model Fine-tuning to unify the workflows to create training data and fine-tune FMs.
- Build deployable models by distilling relevant foundation model knowledge into training data used to train more efficient, specialized models that can be shipped to production within governance and cost constraints and MLOps infrastructure. This is done using two new features, Foundation Model Warm Start and Foundation Model Prompt Builder.
Method
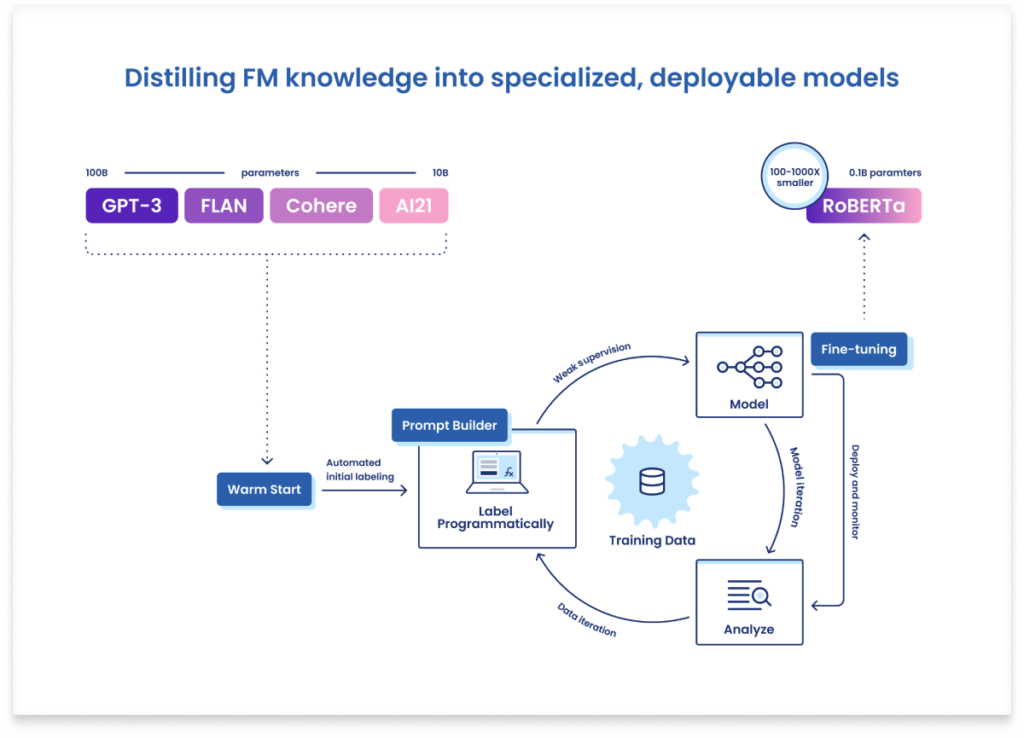
Given our goal was to solve both adaptation and deployment challenges, our approach with this case study was to distill relevant foundation model knowledge and transfer it via training data into a smaller, more deployable model. Here’s a high-level overview of Snorkel Flow’s standard data-centric development process, which we followed:
- We began by using Foundation Model Warm Start to create few-shot learning labeling functions from foundation models created by various companies—OpenAI, Google, Cohere, and AI21.
- Each of these models proposed training labels for the unlabeled data points in the training set. Using Snorkel Flow’s label model, these noisy and often conflicting labels were intelligently combined to produce a single higher-confidence training label per example.
- With Foundation Model Fine-tuning, we fine-tuned a significantly more deployable model (RoBERTa), which still has plenty of capacity to perform well on this task (given a sufficient quantity and quality of training data), but can be deployed at a fraction of the cost of the larger foundation models.
- By analyzing the resulting model, we identified opportunities to add new sources of signal (new labeling functions) to correct the errors propagated by the foundation models. This could be done using the Foundation Model Prompt Builder to write custom prompts for foundation models or by introducing other types of labeling functions. In this case, we observed that certain classes with rare words were being consistently misclassified by the foundation models and so added a labeling function that uses a simple TF-IDF transformation to assign documents to classes with high similarity based on the class name.
- Having reached the extent of our legal domain knowledge, we trained a final RoBERTa model and stopped there, but a true subject matter expert could have improved the score further, if necessary, by systematically identifying additional errors with the help of Snorkel Flow’s analysis tools and addressing them by editing or adding labeling functions or (if necessary) manual labels.
Experimental design
In this section, we describe the specific dataset, task definition, and the properties of the models and prompts used in this case study.
Dataset and task
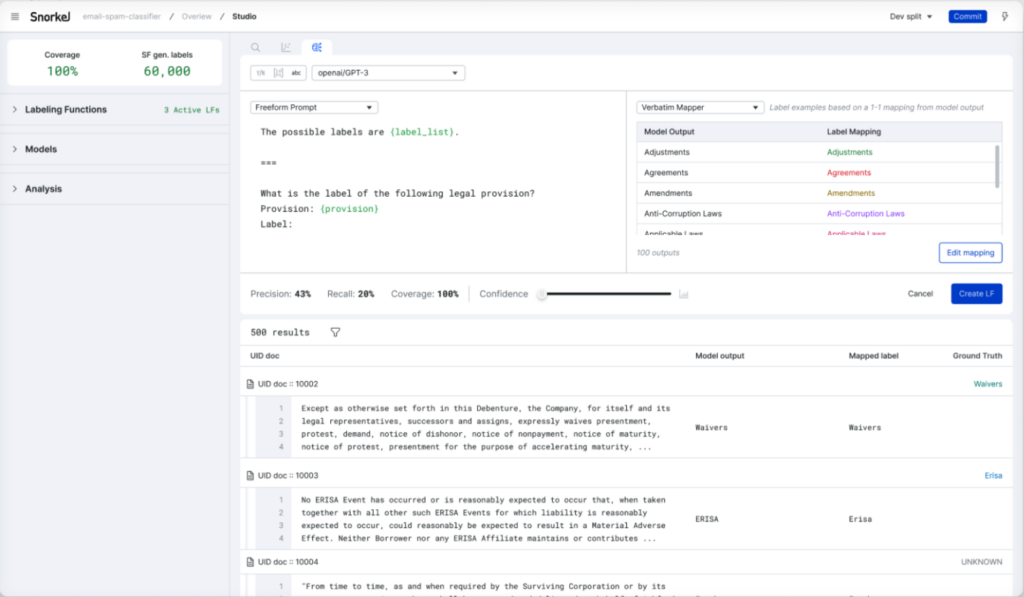
The legal domain is a growing application area for NLP and AI; there are exciting opportunities to analyze legal documents at unprecedented scale and efficiency. LEDGAR2 is a dataset of 80,000 contract provisions from company filings that was crawled from the U.S. Securities and Exchange Commission’s public EDGAR website. Each contract is divided into a set of labeled provisions that comprise the core discourse units of a contract and are critical for analyzing and understanding the legal meaning (see the figure below). We use the LexGLUE benchmark formulation of this task, which takes the 100 most frequent provision labels (out of 12,608 possible classes). Even in this simplified form, this is a very challenging, high-cardinality, multi-class classification problem. The dataset is split train/valid/test of 60,000/10,000/10,000 provisions.

Models and prompts
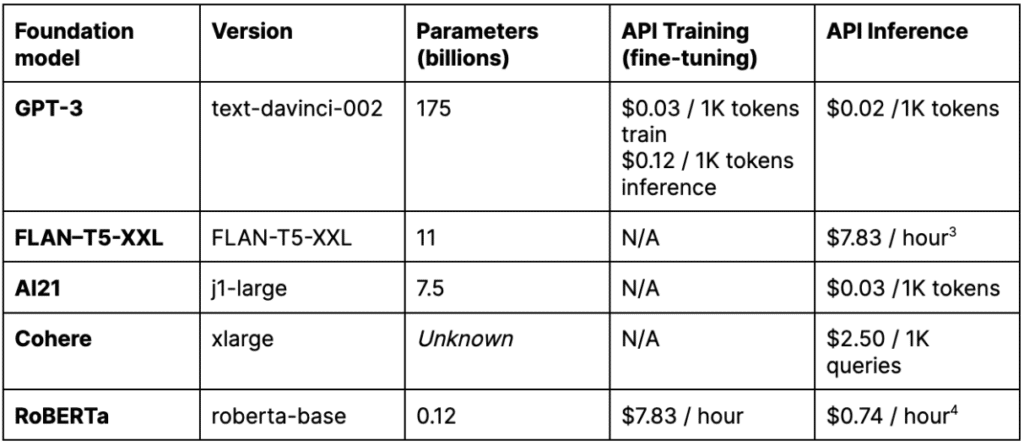
In this case study, we use GPT-3, FLAN-T5-XXL, AI21, and Cohere with Foundation Model Warm Start to create few-shot labeling functions. The prompt used for Warm Start is shown in the figure below. GPT-3 and RoBERTa are also used with Foundation Model Fine-tuning to create models for deployment. For GPT-3, AI21, and Cohere, we used their respective APIs. For FLAN-T5-XXL and RoBERTa we used the Hugging Face implementations run on AWS instances noted in Table 1. Relative to the foundation models, the execution of the TF-IDF labeling function was near instantaneous, and the cost to run was negligible.
Results
In this section, we compare both the quality and the cost of the various foundation models used in the case study, observing that the RoBERTa deployment model trained on weak labels from multiple foundation models:
- Outperforms individual few-shot foundation model predictions
- Matches the quality of a dramatically larger and more expensive GPT-3 model fine-tuned on manually annotated GT labels
Quality
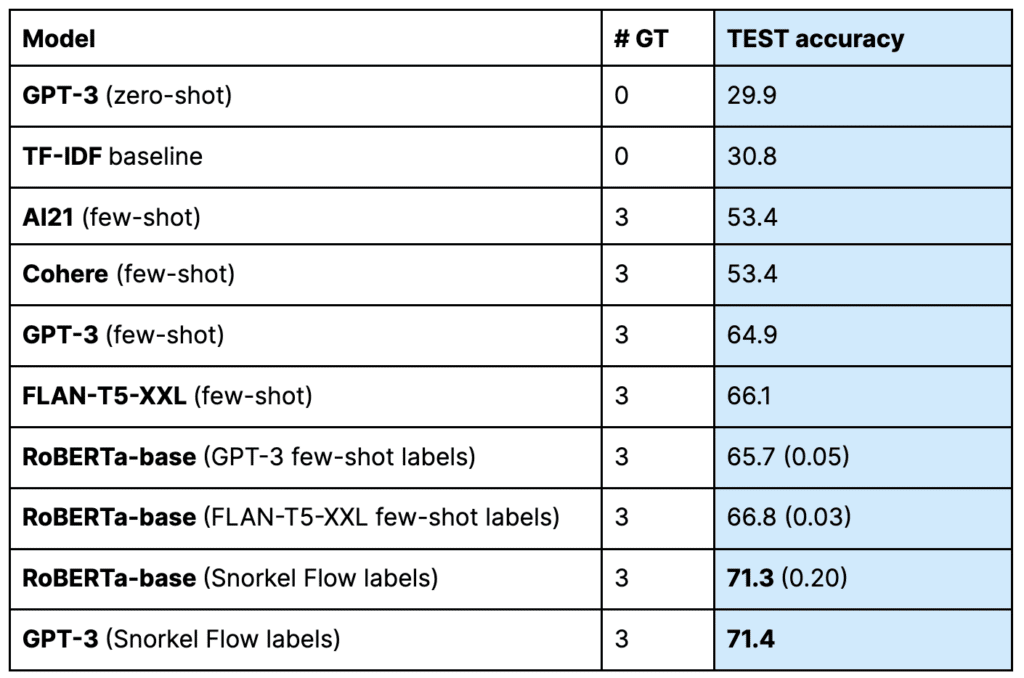
The test accuracies of our Foundation Model Warm Start labelers and the TF-IDF baseline on the LEDGAR test set are reported in Table 2 for reference—in practice; these models are used only to create training labels. We also report the quality of RoBERTa models fine-tuned on different sets of training labels. From this table, we make five observations:
- There is quite a bit of diversity in performance between different foundation models. Even the AI21 and Cohere models, which happened to achieve the same test score, had many disagreements. Each foundation model is trained on different data and will have different strengths and weaknesses. That is true of the four models used in this case study, and we can expect a similar diversity of models in the coming months and years as the market is flooded with new models from researchers and model vendors.
- The highest quality is achieved (by a significant margin) when we fine-tune a model on the Snorkel Flow labels that combine many sources of signal. Rather than trying to determine which model is the single best option (among an ever-growing set of options) for each new application, with Snorkel Flow you can use a variety of sources which the platform will automatically and intelligently combine for higher quality labels.
- A GPT-3 model fine-tuned on the Snorkel labeled dataset does no better than RoBERTa-base fine-tuned on the same data, despite being over 1400x larger. This suggests that for this task, as is so often the case, the bottleneck for achieving higher quality is not model capacity, but training signal.
- The GPT-3 (Zero-shot) model actually underperforms the naive TF-IDF baseline, underscoring the need for adaptation to make a generalist foundation model effective on a specialized task. As is often the case, adding a few in-context examples helps the model do a much better job of aligning its knowledge with the task at hand (which is why we used few-shot Warm Start LFs for this case study).
- Finally, this model built with Snorkel Flow’s Warm Start plus Fine-tuning is just a starting point. If quality is sufficient for our needs this quickly, we can go ahead and deploy it. But if we would like to improve model quality further (and had the legal expertise to do so), at this point we could begin to systematically identify and address specific error modes using Snorkel Flow’s analysis suite and other labeling function builders, including the recently released Prompt Builder. With programmatic labels, model quality can typically be improved by either increasing dataset size (more raw documents to label) or increasing training label quality (by improving or adding labeling functions).
Cost
From Table 2, we observed that with Snorkel Flow’s Warm Start and Fine-Tuning, we were able to successfully distill much of the relevant knowledge from various foundation models into a smaller form factor that’s more suitable for deployment. But how does this compare to doing things the “old-fashioned way”: manually labeling as much ground truth as you can and fine-tuning the largest model you can get your hands on (bigger is better, right?)? Is it worth it?
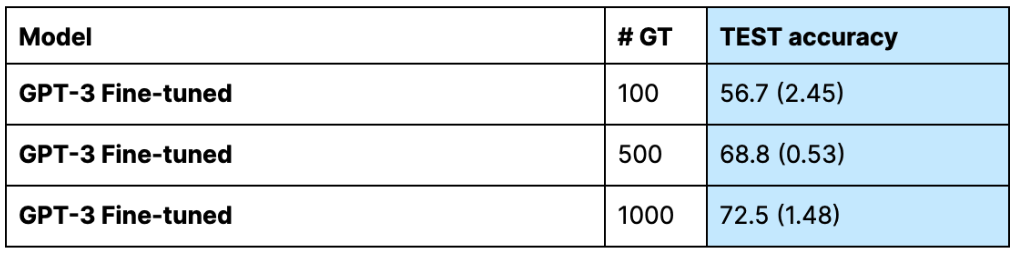
To achieve the same score (within the margin of error) as our RoBERTa model trained on Warm Start labeling functions with only 3 GT, we need to fine-tune GPT-3 (using the OpenAI fine-tuning service) on approximately 1000 GT. Ignoring for a moment the extra time cost of engaging in a manual labeling process, let’s consider the monetary costs.
We’ll start with the cost of training the model. Let’s assume we hire two contract lawyers (average hourly rate of $74/hr6 near Snorkel AI headquarters) who label each provision and adjudicate disagreements. We assume each provision, which requires choosing 1 out of 100 possible labels, takes about 3 minutes to label on average (including overhead). Include the cost to perform the fine-tuning, and the total cost to create the model comes to $7,418. The cost to get predictions on the 10k instances in the test set comes to $173.
The model trained in Snorkel Flow with labels from Warm Start has almost no costs associated with collecting GT labels but does require paying the API costs of any third-party foundation models or compute costs for self-hosted models. The final fine-tuning operation is once again very cheap, with the total cost to create the model landing at $1,915 (~75% less than the GPT-3 fine-tuned model). Importantly, once that rich foundation model knowledge has been transferred into our RoBERTa deployment model (which can run inference on a machine that costs mere pennies per hour), we can avoid paying the costs associated with serving those massive models at inference time, resulting in an inference cost that is 0.1% of our fine-tuned GPT-3 model!


Closing thoughts
Foundation models are exciting! And you should be able to take advantage of the relevant knowledge they have for your task without sacrificing quality or committing to serving a model orders of magnitude larger than you need. Using Snorkel Flow, you can adapt foundation models to your specific task and distill their knowledge into smaller models for deployment. In this case study, we see that doing so can result in the same high quality at a dramatically lower (0.1%!) cost.
Learn more about Data-centric Foundation Model Development in Snorkel Flow:
- Join us at the virtual launch event led by Alex Ratner, Co-founder and CEO at Snorkel AI, on November 22, 2022.
- See a demo of the new features in Snorkel Flow by Braden Hancock, Co-founder and Head of Research at Snorkel AI, on December 15, 2022.
- Attend the Data-Centric Foundation Model Summit, a one-day research event with speakers from Cohere, Google, SambaNova Systems, Snorkel AI, Stanford AI lab, and more, on January 17, 2023.
Footnotes
1 The TF-IDF labeling function worked by building a TF-IDF vector space on the training documents and then measuring the distance between each provision and class name, voting in favor of the maximum similarity score. Here is the code:
vectorizer = TfidfVectorizer(min_df=1, stop_words="english")
vectorizer.fit([example["text"] for example in dataset["train"]])
tfidf_docs = vectorizer.transform([example["text"] for example in dataset[split]])
label_names = get_label_names()
tfidf_labels = vectorizer.transform(label_names)
similarity_scores = tfidf_docs * tfidf_labels.T
lf_votes = np.argmax(similarity_scores, axis=1)
2 LEDGAR: A Large-Scale Multilabel Corpus for Text Classification of Legal Provisions in Contracts
6 According to https://www.indeed.com/career/contract-attorney/salaries/CA on 9 Nov 2022.
Featured image generated by DALLE-2

Stephen Bach
Applied Research Scientist
Stephen Bach is the Eliot Horowitz Assistant Professor in the Computer Science Department at Brown University. Previously, he was a visiting scholar at Google, and a postdoctoral scholar in the computer science department at Stanford University advised by Christopher Ré.
He received his Ph.D. in computer science from the University of Maryland, where he was advised by Lise Getoor. His research focuses on weakly supervised, zero-shot, and few-shot machine learning. The goal of his work is to create methods and systems that drive down the labor cost of AI. He was a core contributor to the Snorkel framework, which was recognized with a Best of VLDB 2018 award. He also co-led the team that developed the T0 family of large language models. The team was also one of the proposers of instruction tuning, which is the process of fine-tuning language models with supervised training to follow instructions. Instruction tuning is now a standard part of training large language models. Stephen is also an advisor to Snorkel AI.

I’m an Assistant Professor of Biomedical Data Science and of Medicine at Stanford University. My research focuses on training and evaluating foundation models for healthcare and is positioned at the intersection of computer science, medical informatics, and hospital systems. Much of my work explores using electronic health record (EHR) data to contextualize human health, leveraging longitudinal patient information to inform model development and evaluation. My work has appeared in NeurIPS, ICLR, AAAI, Nature Communications, and npj Digital Medicine.

Braden Hancock
Co-founder
Braden is a co-founder and Head of Technology at Snorkel AI. Before Snorkel, Braden spent four years developing new programmatic approaches for efficiently labeling, augmenting, and structuring training data with the Stanford AI Lab, Facebook, and Google. Prior to that, he performed NLP and ML research at Johns Hopkins University and MIT Lincoln Laboratory and earned a B.S. in Mechanical Engineering from Brigham Young University.
Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

