Takeaways from MLSys Seminars with Chip HuyenIn November, I had the opportunity to come back to Stanford to participate in MLSys Seminars, a series about Machine Learning Systems. It was great to see the growing interest of the academic community in building practical AI applications. Here is a recording of the talk.The talk was originally about the principles of good machine learning design, but most questions I received from the audience was about the myths of machine learning production. Therefore, in this summary post, I’d like to go over the six production myths I often encounter when talking to people who have only experience with machine learning in an academic environment.
Myth #1: Deploying is hard
I’ve heard many data scientists in their early careers telling me how worried they are about not being able to deploy a model since they don’t get to learn that in school. The truth is: deploying is easy. If you want to deploy a model for your friends to play with, it’s straightforward. You can create a couple of endpoints, push your model to AWS, create an app with Streamlit or Dash — if you’re familiar with these tools, it can take an hour.However, deploying reliably is hard. Making your model available to millions of users with a latency of milliseconds and 99% uptime is hard. Setting up the infrastructure so that the right person can be immediately notified when something went wrong and figuring what went wrong is hard. Debugging a machine learning model during training is hard. It’s 100x harder doing it online.
Myth #2: You only deploy one or two ML models at a time
When doing academic projects, I was advised to choose a small problem to focus on, which usually led to a single model. Many people from academic backgrounds I’ve talked to tend to also think of machine learning production in the context of a single model. Subsequently, the infrastructure and plans they have in mind don’t work for actual applications, because it can only support one or two models.In reality, companies have many, many ML models. An application has different features, each feature requires its own model. Consider a ridesharing app like Uber. It needs a model each to predict rider demand, driver availability, ETA, optimal price, fraudulent transaction, customer churn, etc. If this app operates in 20 countries, and until you can have models that generalize across different user-profiles, cultures, and languages, each country would need its own set of models. So with 20 countries and 10 models for each country, you already have 200 models.In fact, Uber has thousands of models in production. Booking.com has 150+ models. I can’t find the number of ML models that Google, Amazon, or Facebook has in production, but it must be in the order of thousands, if not tens of thousands. Here are some of the tasks that Netflix uses machine learning to solve.

Myth #3: If we don’t do anything, model performance remains the same
Software doesn’t age like fine wine. It ages poorly. The phenomenon in which a software program degrades over time even if nothing seems to have changed is known as “software rot” or “bit rot”.ML systems aren’t immune to it. On top of that, ML systems suffer from what’s known as concept drift: the data your model runs inference on drifts further and further away from the data it was trained on. Therefore, ML systems perform best right after training.One tip for addressing this: train models on data generated 6 months ago, 2 months ago, 1 month ago & test on current data to see how much worse their performance gets over time.
Myth #4: You won’t need to update your models as much
People tend to ask me: “How often SHOULD I update my models?” It’s the wrong question to ask. The right question should be: “How often CAN I update my models?”Since a model performance decays over time, we want to update it as fast as possible. Here’s an area of machine learning where we can learn from existing DevOps best practices. Even back in 2015, people were already constantly pushing out updates. Etsy deployed 50 times/day, Netflix 1000s times/day, AWS every 11.7 seconds.In the words of Josh Wills, a former staff engineer at Google and Director of Data Engineer at Slack, “we’re always trying to bring new models into production just as fast as humanly possible.”
Myth #5: Most ML engineers don’t need to worry about scale
What “scale” means varies from application to application, but examples include a system that serves hundreds of queries per second or millions of users a month.You might argue that if so, only a small number of companies need to worry about it. There is only one Google, one Facebook, one Amazon. It’s true, but a small number of large companies employ the majority of the software engineering workforce. According to StackOver Developer Survey 2019, more than half of the respondents worked for a company of at least 100 employees.
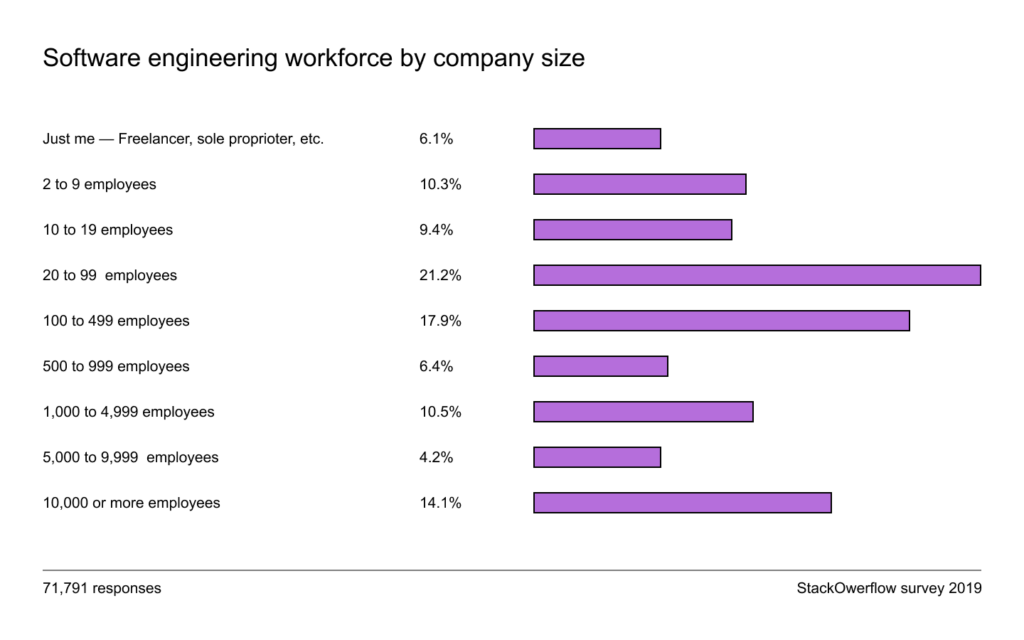
I couldn’t find a survey for ML specific roles, so I asked on Twitter and found similar results. This means that if you’re looking for an ML-related job in the industry, you’ll likely work for a company of at least 100 employees, whose ML applications likely need to be scalable. Statistically speaking, an ML engineer should care about scale.
Myth #6: ML can magically transform your business overnight
Due to all the hypes surrounding ML, generated both by the media and by practitioners with a vested interest in ML adoption, some companies might have this notion that ML can magically transform their businesses overnight.Magically: possible, but overnight: no.There are many companies that have seen payoffs from ML. For example, ML has helped Google search better, sell more ads at higher prices, improve translation quality, build better phone apps. But this gain hardly happened overnight. Google has been investing in ML for decades.Returns on investment (ROIs) in ML depend a lot on the maturity stage of adoption. The longer you’ve adopted ML, the more efficient your pipeline will run, the faster your development cycle will be, the less engineering you’ll need, and the higher your ROI will be. Among companies that are more sophisticated in their ML adoption (having had models in productions for over five years), almost 75% can deploy a model in under 30 days. Among those just getting started with their ML pipeline, 60% takes over 30 days to deploy a model.
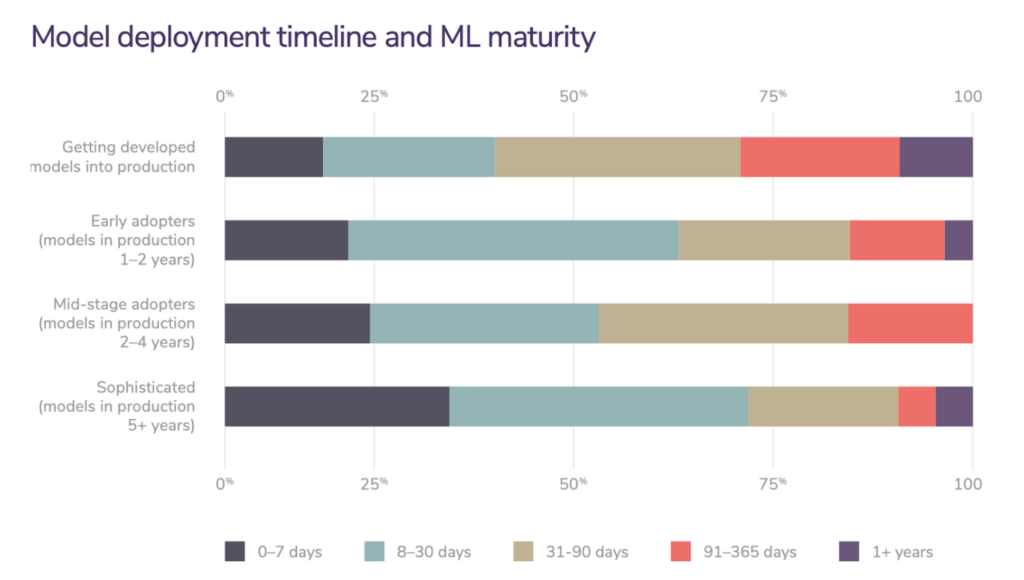
2020 state of enterprise machine learning (Algorithmia, 2020)
Conclusion
Deploying ML systems isn’t just about getting ML systems to the end-users. It’s about building an infrastructure so the team can be quickly alerted when something goes wrong, figure out what went wrong, test in production, roll-out/rollback updates.It’s fun!At Snorkel, we have encountered some of these challenges first hand as we develop Snorkel Flow and help leading organizations put ML systems into production. For the past few years, we have focused on a new approach to the AI workflow stemming from programmatic training data creation. This approach allows accelerated model development, systematic and iterative performance improvement and rapid adoption to changing input data or business goals. If you are interested to learn more check out more talks by Snorklers or signup for a demo.

Chip Huyen
ML Engineer & Open Source Lead
Chip Huyen is a co-founder of Claypot AI, a platform for real-time machine learning. Previously, she was with Snorkel AI and NVIDIA. She teaches CS 329S: Machine Learning Systems Design at Stanford. She’s the author of the book Designing Machine Learning Systems (O’Reilly, 2022).
Recommended articles
View all articles

The Standard for Agents You Can Trust: Lessons from the Federal Front Lines
In the first installment of Agentic in Action — a series about real AI deployments, not demos — Snorkel AI’s Kevin Olivieri sat down with three people who have spent their careers where trust isn’t optional: Chris Sniffen, Federal Applied AI Lead at Snorkel AI; John Hickey, President of August Schell; and Mike Baca, CIO of August Schell. The conversation focused on
June 5, 2026
•
Snorkel Team

Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
At our latest Snorkel AI Reading Group, Yijia Shao (Stanford NLP) stopped by our San Francisco office to present Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration. As LLM agents get better at automating tasks on their own, a large class of real-world problems still needs a human in the loop – for their preferences, their domain expertise, or simply for control.
June 4, 2026
•

Benchtalks #2: The future of coding benchmarks
For our second Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with John Yang, a Stanford PhD student and creator of the SWE-bench franchise, SWE-smith, CodeClash, and most recently ProgramBench. Highlights More on ProgramBench: See the benchmark and the upcoming leaderboard at programbench.com. More from John Yang: Publications and writing at john-b-yang.github.io. Snorkel
June 3, 2026
•

