Snorkel AI just hosted the second day of The Future of Data-Centric AI conference 2022. Across 40+ sessions, 50+ Data scientists, ML engineers, and AI leaders came together to share insights, best practices, and research on adopting data-centric approaches with thousands of attendees from all around the world.
Aarti Bagul, a Snorkel AI ML Solutions Engineer and one of the conference hosts, warmly welcomed the audience to day 2, laying out the plan of the day. The agenda included more than 20 talks across three tracks running in parallel: Data, Techniques, and Applications—all of which will be available to watch later on at future.snorkel.ai.
This article will provide highlights from day 2, including the morning keynote talks and a handful of the many track talks from this day. You can read highlights from day 1 here.
Specifically, I will cover 10 out of 21 sessions:
- A Holistic Representation Towards Integrated AI by Xuedong Huang, CTO of Azure AI at Microsoft
- Adopting Data-Centric AI at Enterprise Scale with Devang Sachdev, VP of Marketing at Snorkel AI, Sourabh Deb, SVP, Artificial Intelligence Center of Excellence (AI COE) at Citi, and Richard Finkelman, Managing Director at Berkeley Research Group LLC
- Using Snorkel to Programmatically Label Pathology Reports for ML App by Subratta Chatterjee, Principal Data Scientist, and John Cadley, Bioinformatics Engineer at the Memorial Sloan Kettering Cancer Center
- HoloClean and Kamino: Structured Learning for Data Cleaning and Private Data Generation A by Ihab Ilyas, professor of Computer Science and the NSERC-Thomson Reuters Chair on data quality at the University of Waterloo and Apple’s head of the Knowledge Graph Platform
- Data for AI & AI for Data with Ravi Teja Mullapudi, Research Scientist at Snorkel AI and Madhu Lokanath, Product Owner at Metapix—Ford Motor Company
- Principles of Data-Centric AI development by Alexander Ratner, CEO and Cofounder, Snorkel AI
- Data and Manual Annotation Monitoring for Training Data Management by William Huang, Senior Data Scientist at Capital One and NLU/NLP expert
- Practical Paths to Data-Centricity in Applied AI with Robert Crowe, TensorFlow Developer Engineer, and Abhishek Ratna, Developer Marketer for artificial intelligence and machine learning technologies at Google
- Closer look at Fairness in Job Ecosystem by Sakshi Jain, Senior Manager of Responsible AI at Linkedin
- MLCommons and Public Datasets by Peter Mattson, Senior Staff Engineer at Google
As with day 1, the day was packed with interesting and diverse sessions with valuable takeaways for anyone interested in learning more about data-centric AI. You’ll be able to find even more on future.snorkel.ai once the recordings are available.
A holistic representation towards integrated AI

Xuedong Huang, CTO of Azure AI at Microsoft, kicked off the sessions with a great talk offering behind-the-scenes stories of the Microsoft Azure team and how integrative AI using APIs is transforming the industry just as much as GUI did. Xuedong discussed the many breakthroughs in the field, focusing on speech and language technologies. He also gave interesting insights on upcoming Microsoft work revolutionizing speech and language models involving foundation models often discussed by Yann LeCun. Xuedong continued with an exclusive primer demo showcasing their novel multilingual translation model (and future Microsoft Azure API) called Z-Code, where they were able to recognize speech and translate it automatically into multiple written languages.
Xuedong then introduced Florence, Microsoft’s first foundation model for vision applications (e.g., image classification with ImageNet), including complex tasks like video summarization, as he revealed in a very cool demo where the model described not only the overall scene but also a continuous summary of what each “object of interest” (including a rhinoceros in the background) was doing in the video. He finished his talk by explaining how Microsoft Azure uses Snorkel Flow to enhance their training pipeline and improve their foundation models, for example, the Azure Form Recognizer. The talk ended with a Q&A where Dr. Chenguang Zhu, Principal Research Manager in Microsoft Cognitive Services Research Group, shared a crucial perspective on foundation models.
“No single model (even foundation models) can yet check all three boxes: moderate size to deploy efficiency (<1B parameters), state-of-the-art results in the context of few-shot learning, and state-of-the-art results in fine-tuning with enough data.”
Chenguang Zhu
Principal Research Manager in Microsoft Cognitive Services Research Group
Adopting data-centric AI at enterprise scale
Devang Sachdev, VP of Marketing at Snorkel AI, introduced Sourabh Deb, SVP, Artificial Intelligence Center of Excellence (AI COE) at Citi, and Richard Finkelman, Managing Director at Berkeley Research Group, to talk about data-centric AI at enterprise scale. With a great “fact or fiction?” format, Sourabh and Richard answered a few of the most interesting industry-related questions we can ask as data scientists.
This talk’s highlight is the second question when Devang asked Richard about whether our job as data scientists is finished once the model is put into production. Richard explained why this is patently false in part by describing concept drift, where real-world conditions (whether the production data or model objectives, such as a new regulation) change, requiring new training data to appropriately teach deployed models.
They continued the conversation by discussing the opportunity and limits of using large language models in production, including the fact that while they have vast amounts of generalized knowledge, they need to be trained on data specific to your context. One example they cited was the limited understanding an LLM is likely to have of specialized legal speak. Next, they discussed the importance of collaboration with subject matter experts (SMEs) and the challenges that can be inherent. Sourabh emphasized the importance of reviewing training data labels often and improving your labeling system and SME partnership:
“It’s important to identify the right SME for your project; you’ll often receive different answers across SMEs; someone has to ‘break the tie’. Identifying the person to make that call is important given labeling can often get assigned to someone lower in the org without full understanding of the implications of labeling decisions.”
Sourabh Deb
SVP, Artificial Intelligence Center of Excellence (AI COE) at Citi
Finally, in an important thread on improving the practical application of AI, they discuss a barrier to data-centric AI approaches of programmatic labeling, which by design, reduce the demand for hand-labeling by experts, especially when that is a source of revenue.
“Reducing manual annotation can require an organizational shift for professional services organizations. They need to buy into the idea that fewer lawyers analyzing and labeling contracts is better even when it means fewer hours billed; that it’s the right solution for clients and therefore the better long-term strategy.”
Richard Finkelman
Managing Director at Berkeley Research Group
Using Snorkel to programmatically label pathology reports for ML app
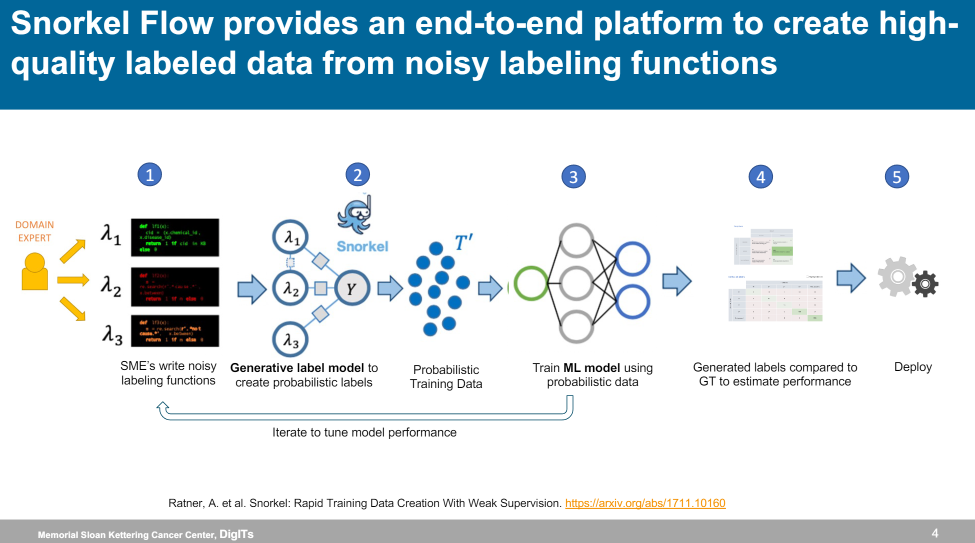
Subratta Chatterjee, Principal Data Scientist, and John Cadley, Bioinformatics Engineer at the Memorial Sloan Kettering Cancer Center, covered how to make use of a huge amount of unlabelled data in clinical settings where the false positives actually have real-life consequences. They discussed the challenges of relying on manual annotations for training data given the high degree of expertise required from high-value, time-starved clinicians, and how this led them to a careful study of available alternatives, ultimately landing on Snorkel Flow’s data-centric AI platform. Programmatic labeling allowed them to scale organizational insight and expertise by codifying it into labeling functions and applying them at scale.
They shared two case studies where they proved their ability to achieve high F1 scores in a fraction of the time required previously. John highlighted his ability to iterate rapidly and strategically using analysis as to where a model (trained within the core workflow) was confused as a key driver of success and speed. The team also touched on how programmatically labeling allows them to change labels and classes very quickly and easily in response to objective changes.
They also highlighted the importance of understanding the rationale behind their labels, something that cannot be done when experts label manually as none of the rationales behind their decision is captured. Labeling functions and transparent error analysis make the model’s decisions and errors easy to understand, which is particularly important when stakeholders—clinicians—are cautious and require a concrete understanding of model behavior, as Srubatta highlighted in the quote below.
“Using the programmatic labeling concept of ‘rules’ which can be imprecise, is much more transparent compared to a black box. We can use this to understand why a given label was applied as such to avoid medical bias and support model governance in the future—critical for a clinical setting.”
Subratta Chatterjee
Principal Data Scientist, Memorial Sloan Kettering Cancer Center
They ended the talk by covering their data labeling processes, training pipelines, validation and test approaches, and shared checklists, challenges, and concrete examples of how they use Snorkel Flow for their particular needs. Truly a must-see for real-world examples of data-centric AI in action.
HoloClean and Kamino: Structured learning for data cleaning and private data generation

Ihab Ilyas, Professor of Computer Science and the NSERC-Thomson Reuters Chair on data quality at the University of Waterloo and Apple’s head of the Knowledge Graph Platform, told us about his journey and projects at Waterloo and the creation of HoloClean. As most speakers mentioned, data annotation is highly labor-intensive and costly. Similarly, as highlighted in the previous talks, the annotation errors are often hard to understand and find. Human errors are unpredictable and hard to clean automatically due to high sparseness (errors appear randomly and rarely, making them even more dangerous than constant and repeated (easily patchable) errors).
Ihab’s answer: use machine learning for cleaning data to train our machine learning-based models! Does that sound like a déjà vue? This idea is very similar to Joseph “Rich” Baich’s talk on the first day of the event, where he defended that AI should be used mainly to remove human errors. Still, this is a challenging problem as the data is complicated to annotate, constantly changing and evolving, contains sparse errors and random noise, etc., which is why they built a company (HoloClean)—partnering with some of the team members from Snorkel AI—around this serious issue.
Ihab continued his presentation by going more in-depth on using AI and ML for automation and data cleaning at HoloClean to improve label quality.
Data for AI and AI for data
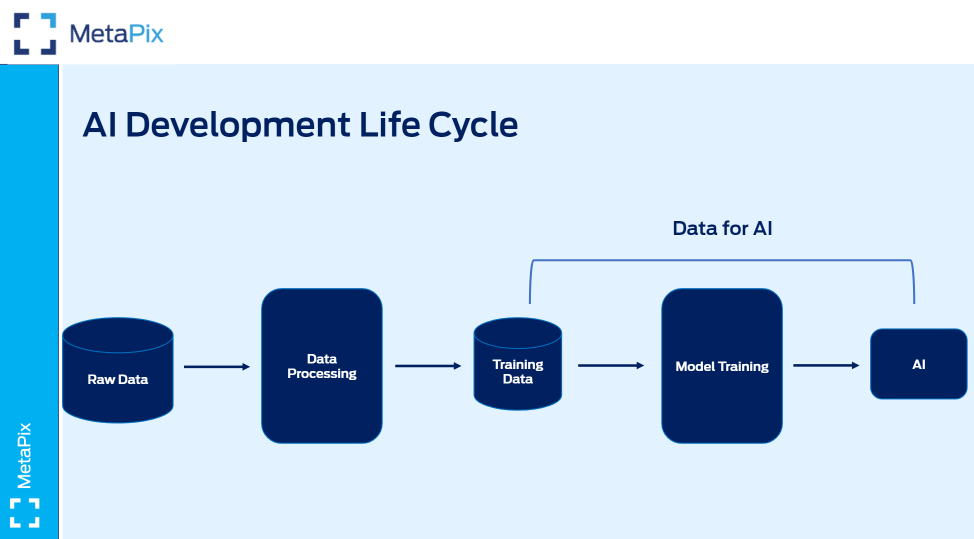
In this session, Research Scientist at Snorkel AI, Ravi Teja Mullapudi and Metapix Product Owner at Ford Motor Company, Madhu Lokanath, discussed creating a data-centric AI platform for images, covering different steps and challenges for preparing data and going from raw data to training data. In other words, cleaning and transforming data into labeled training data used to teach a machine learning-based algorithm we can have confidence in. He pursued covering model training and building the end-to-end platform with which you iterate for new and improved data as long as the model is online (i.e., an active learning loop). They also discussed the importance of explaining your model’s decisions, a recurring issue with AI models that data-centric approaches (and explainable AI) aim to correct.
If you can take one thing out of this event is definitely how important it is to build a sustainable lifecycle for your models where you can quickly iterate, correct, and improve your training dataset following real-world changes, and Snorkel Flow can help for that.
The principles of data-centric AI development
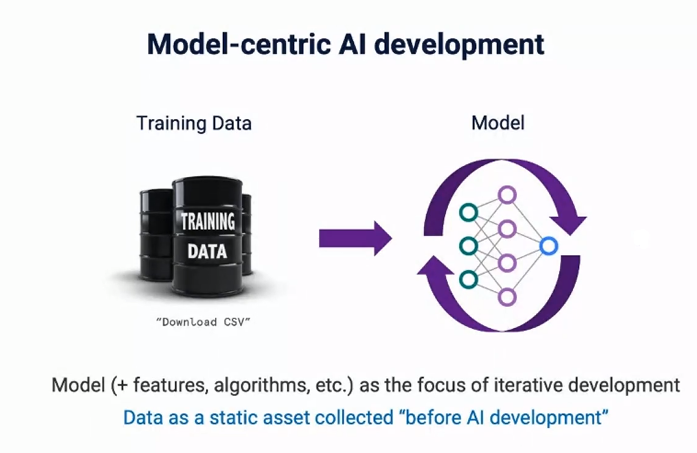
In this talk, Snorkel AI Co-founder and CEO Alex Ratner broke down the difference between model-centric AI and data-centric AI. TL;DR: in data-centric AI, you spend more time focusing on your data—annotating, improving, curating, and cleaning it—as compared to model training and tuning. The need for data-centric AI is unquestionable when you compare the results of the multiple models on benchmarks like Imagenet, where each architecture performs very similarly even though they have huge fundamental differences—further proving the importance of focusing (and investing time and money) on data and simply using a “good enough” model. That is even more true considering the recent accessibility of the new hyper-powerful models (transformers and vision transformers), beating state-of-the-art on many tasks but extremely data-hungry. And what can you do with a data-hungry model? Feed it data easily labeled through the use of programmatic labeling!

Alex also quickly highlighted how important it is to collaborate with SMEs when labeling programmatically and troubleshooting—the aim cannot be to replace them. This is a worthwhile talk for anyone still doubting data-centric AI or unsure about shifting towards this approach.
Data and manual annotation monitoring for training data management
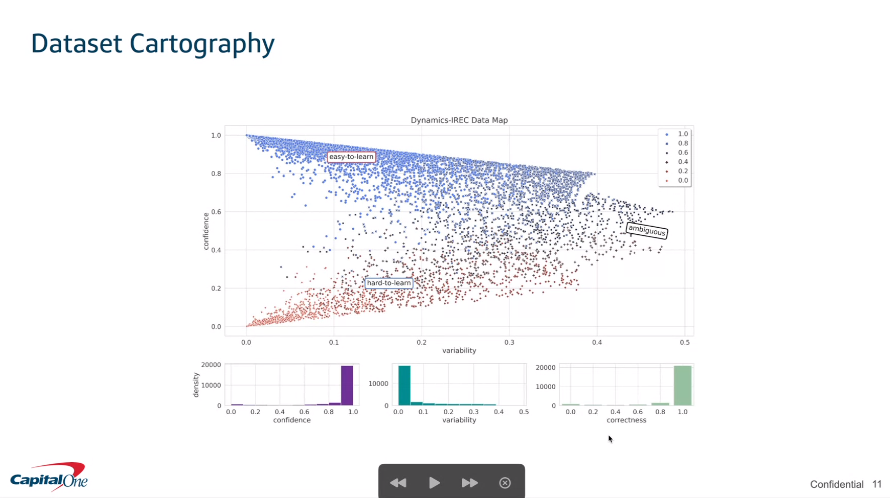
In this session, William Huang, Senior Data Scientist at Capital One and NLU/NLP expert, carried out a particularly interesting introduction covering a “day in his life” as an NLU data scientist at Capital One, covering a typical real-life NLU pipeline using a data-centric approach. He goes over what dataset cartography is (mapping model behaviors throughout training as shown in the above image) and how it is implemented within their training pipeline, giving visual diagnostics on your training scheme like helping you spot mislabeled data.
Practical paths to data-centricity in applied AI
In this talk, Robert Crowe, TensorFlow Developer Engineer, and Abhishek Ratna, Developer Marketer for Artificial Intelligence and Machine Learning Technologies at Google, go over some of the most common questions they get regarding moving to a data-centric AI, such as:
- Is more data always better? Short answer: No. The volume itself isn’t a good measure as it can include tons of duplicate data, or only encompass a narrow region of feature space.
- Is feature selection necessary? While you don’t need to use feature selection, you may end up with a more computationally complex model than necessary. Another reason to use feature selection is to better understand and govern your data.
- What are some of the challenges of supervised learning in production use cases? In supervised learning, you need labeled data. This data dependency requires labelers (oftentimes humans with expensive salaries like neurologists annotating brain MRIs). Getting these high-quality labels is by far the most challenging (and expensive) part of the whole pipeline for supervised approaches. There are also known issues of data and concept drift. Weak supervision, which Robert calls out Snorkel AI is famous for, directly addresses these challenges.
- What are some of the challenges of applying large language models in production use cases? Easy answer: The sheer size of the model! They need to be high-value use cases. A second challenge is having confidence in its predictions (once again, understanding how the model makes its decisions greatly helped through a better understanding of your data and labels), especially for edge cases.
- In a production use case, how should developers think about change? Robert answered this in no uncertain terms, saying “change is true for models just like it’s true for humans.” You will need to adapt your model to new treatments, new diseases (hello, Covid), and new events and trends.
I won’t spoil it all for you. Listen to the talk on future.snorkel.ai once the recordings are available for more details as they go back and forth about each question with very insightful points.
Closer look at fairness in the job ecosystem

In this close-to-my-heart session Sakshi Jain, Senior Manager of Responsible AI at LinkedIn, addresses fairness in the jobs ecosystem and why we should care about this topic. She starts defining fairness broadly (spoiler, it means no discrimination and equal representation!) and gets deeper into how it is applied to our field and especially at LinkedIn, a company with massive impact on the communities, growth, and career trajectories of workers across the world.

Sakshi dives into why systems are biased, going beyond the classic “garbage in, garbage out” answer to pose it’s also because of biases in human labels and even product design which can drive users toward specific (and sometimes unwanted) behaviors. She also outlines concrete mitigation approaches for your data and models in all pipeline steps (pre-processing, in-processing, and post-processing).
MLCommons and public datasets
In this last (but definitely not the least) session of the day, Peter Mattson, Senior Staff Engineer at Google and President at MLCommons, discusses the future of public datasets and his non-profit organization, the MLCommons association. In his talk, Peter puts emphasis on the importance of data with a slamming quote:
“You cannot do better than your data.”
“You cannot do better than your data.”
Peter Mattson

Peter also highlights the most important pain points we need to change and further discusses why we need to change them, how to change them, and with what tools, which is what they are working on at the MLCommons association to remediate challenges of ML research. To name a few, he discusses how we design datasets, create them, measure data quality, evolve datasets, increase data efficiency, and, ultimately, how we can build better public datasets.
As you see, these pain points of and priorities for ML research are all around data, which tracks with Peter’s assertion that “datasets are the language we use to communicate the results of our ML research.”

Event summary
What an exciting two-day event! If you’ve arrived to this conclusion, you are now surely part of the data-centric team and understand the importance of shifting your focus to continuous data quality improvement to achieve your model performance targets. Ready to implement the best practices outlined during this event within your organization? Request a demo of Snorkel Flow, the data-centric AI platform.
To view these talks, as well as the many others not mentioned in this article, bookmark future.snorkel.ai where recordings will be available in the coming weeks. You’ll find inspiration from the real-world experiences from experts already using data-centric approaches, including many immediately actionable insights you can apply to accelerate the success of your AI/ML projects.
I hope you learned and enjoyed the event as much as I did. I will see you at the next Snorkel AI event, maybe in person this time! Follow Snorkel AI on Twitter, Linkedin, and Youtube.


Recommended articles
View all articles

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

