
SnorkelSpatial
A procedurally-generated benchmark for evaluating allocentric and egocentric spatial reasoning capabilities in LLMs.
Overview
Large language models (LLMs) show remarkable results on solving complex reasoning problems across domains — from mathematical proofs and logical puzzles to graduate-level science and engineering questions. However, their spatial reasoning capabilities are less understood, even though such reasoning underlies many everyday and scientific tasks involving geometry, diagrams, and spatial relations. To expand our understanding of spatial reasoning capabilities of LLMs, we design a simple spatial reasoning benchmark with a variety of problems based on a 2D grid world.
We design a benchmark that tests spatial reasoning through a controlled grid-based environment. The setup consists of a two-dimensional square board with a few particles placed on it. The board and the particles can move and rotate. A sequence of actions, such as rotations and translations, is applied to the board and particles. After these actions, the model is asked questions about the final positions and orientations of either board or particles. The complexity of the problems is controlled by changing the number of actions applied to the board and/or particles.
Types of actions
We define a set of primitive actions that are applied on the board and the particles to change their states.Movements: Board and particles can move FORWARD, BACKWARD, LEFT, or RIGHT one step with respect to their current orientation. Movement does not change the orientation of the board and particles. When the board moves in any direction, all the particles on it also move along with it in the same direction. Additionally, if the particle's movement causes it to cross the board's boundary, the position is wrapped around from the opposite side of the board.
Rotations: Board and particles can rotate by 0, 90, 180, 270 or 360 degrees counterclockwise with respect to their current orientation. When the board is rotated by a certain angle, all the particles on it are also rotated by the same angle. Particle rotations are with respect to their current orientation.
Types of queries
After performing a sequence of the above actions, we ask the LLM the following types of queries about the states of the board and particles to test its spatial reasoning capabilities. The absolute and relative queries are designed to test allocentric (absolute) and egocentric (relative) spatial reasoning, a fundamental dichotomy stemming from cognitive psychology. Questions are based on absolute location, tile queries (i.e. the tile on which a given particle is currently located at), absolute orientation, relative location and relative orientation.Dataset
We evaluate models on a dataset of 330 samples, varying the number of actions selected from the set {10, 20, 50, 100, 200}. Intuitively, we expect the problems with a larger number of actions to be harder.Data Sample
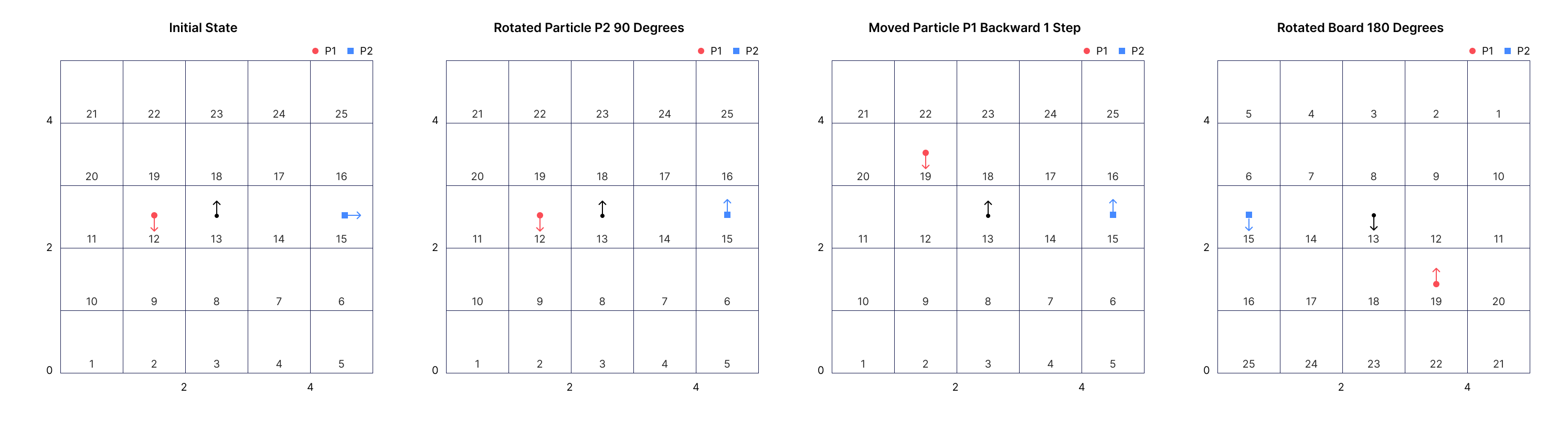
The following abridged version of a sample is based on the above figure. The problems used for the evaluation are on a larger board size and have more actions. Note, only textual description is provided to the models, the figure above is only for illustration.
question
# Initial States The environment consists of two particles P1, P2 and a square board B1 of width 5, with 1x1 tiles numbered from 1 to 25 in a zigzag pattern. The board's location and orientation are determined by its centroid's location and orientation. Initially the board is at location (2.5, 2.5) and oriented towards north. P1 is at (1.5, 2.5) and facing south. P2 is at (4.5, 2.5) and facing east.
# Actions The actions are the following: First, particle P2 is rotated by 90 degrees. Then, move particle P1 BACKWARD by 1 unit. Then, particle P2 is rotated by 0 degrees. Then, rotate board B1 by 180 degrees.
# Question What is the orientation of particle P1 after all the actions?
# Response format - JSON schema
You must get the final answer and convert it to the following JSON data structure.
Follow the schema exactly.
Key: particle_P1_orientation
Type: String
solution
Output: { "particle_P1_orientation": "NORTH" }
Evaluation Methodology
During evaluation, the model receives only a text description of the initial setup and the sequence of actions. It must reason through these transformations to answer correctly. The answers are returned using structured JSON output, and compared against ground truth obtained programmatically.
We report the accuracy@1 over the dataset. We attempt each question 10 times in case the model fails to output or returns invalid output. If it doesn't return a valid output in all trials we treat this missing output as incorrect while computing the accuracy.
In follow-up work, we will explore LLMs capabilities in solving these problems by generating code or doing visual chain-of-thought reasoning.
