New Snorkel benchmark leaderboards. See the results.
What can Data-Centric AI learn from data & ML engineering?

Matei Zaharia is an Assistant Professor of Computer Science at Stanford University and Chief Technologist at Databricks. Recently he gave a presentation at Snorkel AI’s The Future of Data-Centric AI Conference 2022. Following is a lightly edited transcript of his talk. Visit future.snorkel.ai to watch 50+ sessions presented by speakers from some of the largest enterprises, leading AI companies, and notable academic institutions.
What can data-centric AI learn from data engineering and machine-learning engineering? In other words: how can we make data-centric AI easy to use at scale in production? My piece here is based on a research paper I wrote with Alkis Polyzotis (also at Databricks). It is what might be missing from the field of data-centric AI and posits how that field may look in the future.

We know that data-centric AI places the data scientists’ and engineers’ primary focus on building high-quality datasets to improve AI. This is as opposed to model-centric AI, which emphasizes iterating on models or algorithms. Data-centric AI is, in some ways, a special subset of data-centric applications, more generally. Creating computer applications that aim to build a quality dataset isn’t a problem unique to AI. Broadly speaking, there are many applications used by companies and organizations of all sizes whose main job is to produce a dataset.
For one simple example, think about your local power company. Your power company must figure out how much power each customer has used at different times. Then it must use that data to compute and deliver a bill for each customer. The application’s output is a giant dataset containing each user and their bill. It has to be correct, and no one can manually review every bill for accuracy. This is an example of an application that’s required to process incoming datasets and reliably produce a certain output.
For another example, if you want to provide shoppers with recommendations in an online store, you need to create an accurate dataset of past events that records what was visible to the customer when they made their purchase decisions. Then you need to train a model on that information. You also need to monitor what happens afterward with your model and feed that information into training.
In both the power company and online store examples, there are existing engineering disciplines that focus on how to build applications that reliably create datasets. These are:
- Data engineering, for the data problem more broadly, and
- Machine-learning (ML) engineering.
Traditionally, ML engineering hasn’t focused very much on how you obtain labeled data, but that is changing. There is now an entire ecosystem of tools that work on this problem, and they are important to know about. The open-source project MLflow (which I co-founded) is one, but there are many others for data and machine learning.
I want to look at these tools and consider what ideas we can transfer from these other fields and apply them to data-centric AI. These are fields in which millions of data engineers around the world already build applications with established best practices. I will highlight five of these lessons (that might be surprising to some ML engineers) that we at Databricks think are important.

First, data and AI applications must be updated continuously, which means numerous things, as I will explain. Next, I will discuss what works and does not work for monitoring. Third, I will examine how people deploy applications, which are often code-centric. Then I will go over the ways that versioning is critical. Finally, I will discuss applications that cannot show data to humans at all, which makes it hard to get humans to label the data or do anything with it.

1. Data and AI Applications must be continuously updated
A common assumption for a lot of ML researchers and even for practitioners is that when you are doing machine learning, you prepare your data once. For example, let’s imagine a Ph.D. student at Stanford who wants to help machine-learning models obtain information from CAT scans. They might think, “what I have to do is gather a lot of images, then work with a lot of human experts to generate labels for them, and then perhaps curate the final dataset to check for quality.” Then they want to publish this, with the idea that everyone will then be able to do ML with CAT scans. In other words, their focus is on creating a high-quality dataset once. A lot of data-centric AI tools start with this assumption.

When you try to use these applications in production, you will usually need continuous data preparation. That is because both your data distribution and your task definition change over time.
To return to the CAT scan example, the CAT scan machines might receive a software update in which they produce images that look different from the ones you trained with. Your entire dataset is not quite as valid, and you must address it. The machines might be placed in new hospitals where the patients are simply different. Any other conditions might be different—perhaps different diseases appear that change your data. Perhaps your labeling ontology changes. There could be a new disease, like COVID-19, that suddenly becomes important to identify. So, to build an AI system that works with this data, you will likely need to keep creating high-quality datasets continuously for a continuously evolving ML task. This differs from most research settings, where you make something once and hope you have made a big step forward.

What does this all mean for data-centric AI? It means that in many settings, data collection and labeling need to be automated and monitored so that they happen all the time. Manual curation and manual evaluation of your results and process should be reduced to a minimum to ensure that you can run this process continuously without hassle.
It also means you should consider tools that accommodate changing problem definitions and data schemas. This is where programmatic supervision tools like Snorkel Flow are very powerful and aligned with these requirements. You would not want to throw out an entire dataset to bring in new data. You need algorithms that can help integrate that new data into the set you already have.
2. Monitoring must be actionable

This need for continuous data updating has a few implications downstream that we can see in how people do data engineering and ML engineering. These implications also apply to data-centric AI. One of these concerns monitoring and what kind of monitoring is “good.”
In a lot of research, the assumption is that data monitoring is just about alerts This means you start by defining some metrics and then computing metrics that reflect the data quality or changes in distribution. Then you set up some thresholds and fire alerts if a metric exceeds that threshold. There is a lot of interesting work on robust metrics and alerting with minimal data, which is great. But in practice, we found in working with many production users that good monitoring is both about alerts and action.
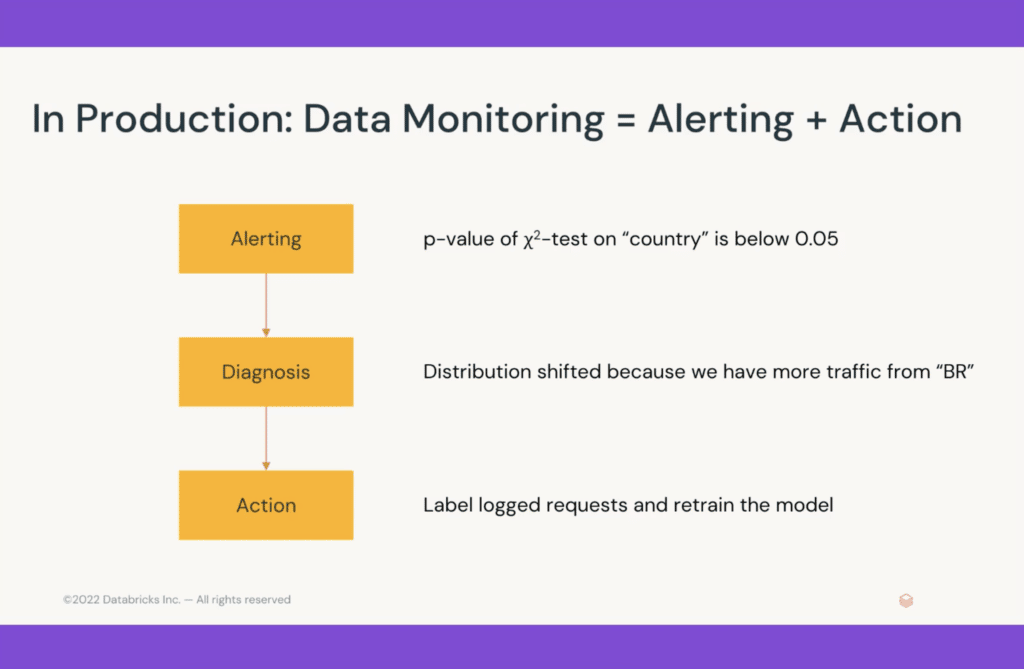
If you only get alerts, but it is not easy to act on them, then you don’t have a great solution. Let’s look at some examples of why the action part is important and why the monitoring design affects it.
Say, for example, you get an alert that the P-value of the Chi-square test on your “country” feature is below 0.05. This means something changed in the country feature. The next thing you would have to do if you are running this application is to diagnose the problem. You might look and notice that the distribution shifted because you suddenly have a lot of traffic from Brazil—maybe your product just launched in Brazil for the first time. The remedy is to label more data from Brazil and retrain your model to account for that new country distribution.

Another thing that might happen is that you see the same alert—P-value on “country” less than 0.05—but you look at why it is happening, and the diagnosis is that you are producing data differently. Your application upstream is now writing countries in lowercase instead of uppercase, and here the action required from you is very different. You need to fix your data pipeline and keep serving the same model. You don’t want to completely retrain the model for this one change.
The main point is that a team will need to do both of these things, and you need to design them together for them to work well.

For effective monitoring, we found that you need three things:
- You must think hard about human attention and where people will spend their time.
- You need what we call “deep monitoring.”
- You need to consider automation of both the alerting diagnosis and the action.

Let’s look at the first one: prioritizing for human attention.
Whenever you set up new alerts, people will look at them. If the alerts are often false positives, those people will essentially start ignoring alerts. It is really important to minimize the number of times you show alerts to people and make it easy for them to get ahead of false positives. It is good, for instance, if you can block specific alerts–and the design of your alerts affects that. You shouldn’t, for example, use a fixed threshold. Maybe you should be able to change it or say, “I don’t care about this feature.” Something like that.
Also, alerts are better if they provide context that lets people immediately fix the problem. If you see that the distribution has changed and the P-value is low, it would be much better if the alert tells you that the mode of the distribution, the most common value, changed from lowercase to uppercase “U.S.” This way, you immediately see what is happening instead of having to stare at all the data. Additionally, monitoring should be easy to set up. Monitoring, in general, takes some work to set up and likely won’t give you anything at first. It only helps when something goes wrong. So, you need to significantly lower the barrier to setting it up in the first place so that teams will do it, even if the benefits don’t manifest for perhaps a few months down the line.
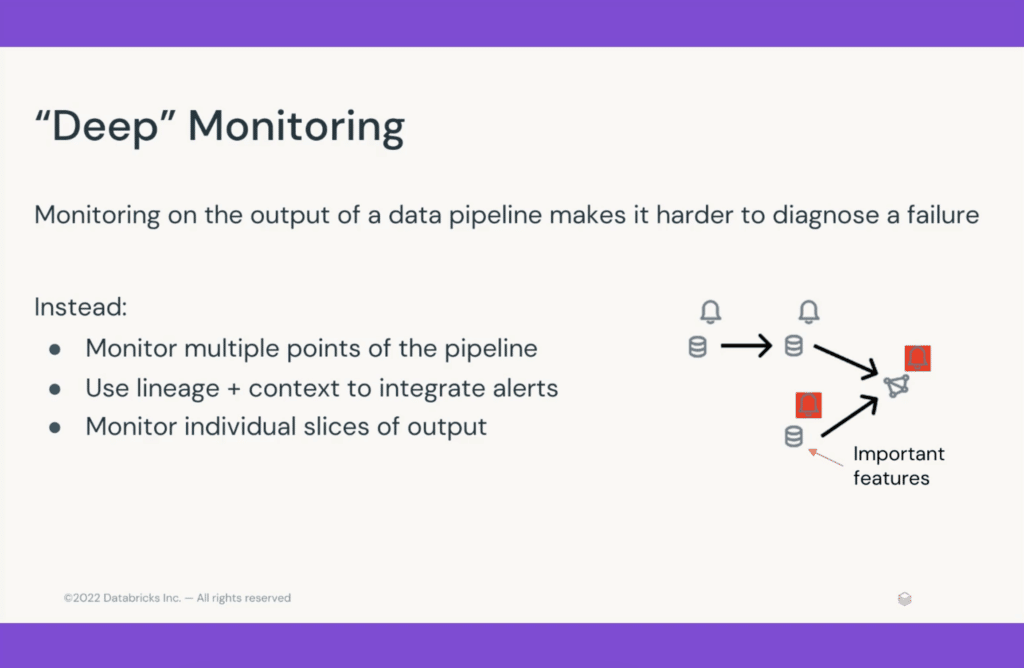
The second thing we found useful in data and ML engineering is “deep monitoring.” Simply monitoring the output of a pipeline makes it very hard to diagnose a failure. Instead, you want to monitor at multiple stages along the pipeline. This way, you can find out when things go wrong early on. Ideally, it should be easy to set up monitoring at all stages and even monitor different subsets of the output. You should be able to easily see how every output was produced. When there is something wrong with part of your data, this enables you to understand what things downstream might be affected, as well as what things upstream might have contributed to the problem.

The third important part of good monitoring is automation. You can automate alerting, for example, and recommend alerts based on the data type. You can automate diagnosis, finding slices of interest in the dataset. And you can even let people automate actions. It is probably difficult to fully automate those, but you want to empower people to quickly listen to specific alert types and then act on them automatically. A very common example in many types of software is just reversion back to the previous version of your software if something goes wrong, especially if it occurs right after a release.
3. Deployment is often code-centric
It is critical to think about how you will move between development and production and what that deployment workflow will be like. What we found is that the process is often code-centric. We saw this at enterprises of all sizes. You might imagine only very tech-heavy companies think all about code, but many teams we talked with do this–even if it is only a small data science team or some equivalent.

Many ML researchers, and even much of ML infrastructure, assume that you have a model-centric workflow. In this approach, during development, someone gathers data and some code and produces a model, and then the artifact being deployed is the model.
But in practice, many teams are adopting a code-centric workflow. The data scientist works on some data, trains a model, and evaluates and approves it. But then they deploy the code they trained with, not the final weight and the model itself. Then there is a separate ML engineering group that runs that code repeatedly in production to be able to update the model when new data comes in. This makes sense if you recall my first point about applications running continuously. If you want to update this application quickly or retrain and fix your model in response to changes, things can go wrong in your data and production. You do not want a block on a data scientist figuring out what environment they were in and rerunning many Jupiter notebooks to produce that model. Instead, you want a recipe for doing this. In many companies we talk to, this is the most common approach they use to manage things.
This is interesting for data-centric AI because now your code is not just for training the model but also for labeling it, showing UIs to people, collecting data, and so on. You would also want it to be something that can be easily handed off to an engineering team. This is tricky to do, but it will be interesting to see how enterprises might implement it so that someone else can operate that process instead of hunting down a specific data scientist who may not be immediately available.
4. Versioning is critical

End-to-end versioning is one of the most important things we have seen across data engineering and ML tools. It is useful to version everything in your application, not just code—which everyone does—but also models, data, metrics, and every concept you might think about.
Many people assume that versioning code is enough, but we found numerous benefits from versioning everything else. At Databricks, just as an example, and in the open source MLflow project, we can version data, code (using Git), models, the actual weights, metrics, and even things like a plot or a Jupyter notebook analyzing model performance. And you can go back and see exactly which artifacts were used to produce a specific result.
This will be very interesting to extend to data-centric tools. We need these sorts of versioning and lineage features to extend back into data labeling. And since we will be collecting labels over time with different populations of experts, differing UIs, different settings, etc., we also want to be able to track exactly where each label came from. The ultimate goal would be to have training methods that deal with that complexity. These methods could know these labels are really old—likely, the data distribution is out of sync, but maybe I can still learn something—whereas some other labels over here are newer.
Of course, when your labeling is programmatic, some of these issues go away. But for anything that requires human supervision, you will need these kinds of versioning capabilities.
5. When applications can’t show data to humans

Lastly, it can be surprising to people that there are a lot of interesting applications in which people are not allowed to look at the data or maybe only see it in very rare cases. Especially when you are working with data from another enterprise or private user data, you may not have permission to inspect it. This breaks a lot of the assumptions of data-centric AI tools because how can you build data-centric AI without looking at the data? However, there are some solutions you can consider in these situations.
Can you, for instance, do your data and model debugging using aggregate queries instead of examining individual data points? Can you do it using proxy datasets, where you create a few examples by hand and then see how your models perform on them? Maybe you can query things like “how many data points are similar to x,” and so on, and then you can debug based on that information.
Another solution is available if you can look at just a few examples from the dataset. When a customer complains that you made the wrong prediction, for example, perhaps you can look at a few data points, if not all.
Finally, this is another setting where weak supervision methods are especially nice because they do not require humans to look at the data as much. It still helps to do so, of course, but you can hone these weak labeling functions over lots of data and still get something useful from it.
There is a lot left to build here on how to get data-centric AI into production. At Databricks, we are working to make it easy to integrate these ideas into the MLflow and into the general development flow that everyone has for data and machine learning. But I am excited to see more research in this space and how to make this something that you can use continuously to keep applications running well. If you want to learn more, I encourage you to check the paper I referenced above.
Visit future.snorkel.ai to watch 50+ sessions on data-centric AI presented by speakers from some of the largest enterprises, leading AI companies, and notable academic institutions.
Session Q&A
The following is a lightly edited version of the Q&A that followed Matei’s presentation. Snorkel AI’s Aarti Bagul moderated it:
BAGUL: Is there open-source software that systematically supports the deep monitoring approach, or is it just a best practice that should be incorporated into the software?
ZAHARIA: There are a bunch of open-source data quality tools, and they work on a table, so you could apply them to lots of tables. I don’t think there is anything that is aware of lineage or that tries to tell you, based on the issues you are seeing, here is where your problem likely is, or even shows you those issues in a graph. But that would be pretty interesting.
Some of the open-source data catalogs, like Amundsen, support tags, and they do have a lineage view. So you could imagine adding tags to marketing that look suspect, for example. But I do think it is mostly custom-built.
BAGUL: What are some of the biggest gaps in terms of tooling that exist today for supporting this type of methodology?
ZAHARIA: I think, in general, ML tooling as a whole is pretty disjointed. You have a lot of point solutions to do specific things–like a feature store, a training algorithm, model quality, and so on. And, of course, in some ways, it makes sense for them to be separate. But it can also be hard to connect them. One thing we have done in the open source MLflow project is to create this component called MLflow Pipelines, which lets you create a templated pipeline for an ML developer to then sort of “fill in the blanks” to build an application.
That means an engineering team or someone more interested in hooking up all these components can create a template, and then an ML expert can focus on the logic of their template, and they don’t have to learn how to integrate all these other things like What are IAM holes? How do you convert data from TF records to Parque? All these weird sorts of questions. I think that could be a step forward. It is all open source in MLflow if you want to check it out.
BAGUL: That prompted another question from the audience about what plans are for MLflow and the roadmap. You just touched on that but do you have anything to add about what you’re looking to support in the near term?
ZAHARIA: We are seeing a lot of really interesting products in the ML space that are building integrations with MLflow, including Snorkel, which is awesome.
We want to make it easy. The philosophy behind the demo flow is that it is a generic platform to which you can add custom metadata and steps to your development process. We want to see what people do with that. We want to provide the infrastructure that lets you set up a workflow and get lots of people to collaborate. For example, there is no built-in data lineage concept in MLflow.
But it is too early to lock in a specific one, given our goals. We want it to be customizable.
BAGUL: You touched on what makes a good alert in terms of it being actionable and providing the right insight. To enable that, what do you think are some of the best practices for generating these artifacts in the first place? Like, versioning your data, your code, your models—how do you go about collecting the artifacts and setting up a system such that you can generate the alerts of the type you discussed?
ZAHARIA: Some tools make collecting and monitoring some of these artifacts easy. For data, you usually use some data catalog, like Hive Meta store, or discovery-centered ones, like Amazon. Platforms like MLflow and TFX do this for basically all the ML-specific things, like an experiment, metrics, models, and so on. There aren’t too many tools that integrate, although, at Databricks, we do integrate them because we are one company that works in both spaces.
In terms of what are good alerts and what are bad ones, I recommend checking out the paper on TFX data validation and also the open-source project as an example of what worked at Google. There are other projects like DQ and others that are trying to support data quality, but I think that paper does a great job of explaining why they do certain things.
In short, they try to make the expectations all written down and editable, things like schema or a range for a field. So when something happens, you can either edit the expectation and say, for a simple example, “it is ok for age to be more than 100” or something like that if you have a old user on the platform. Or, you can say, “ok, it is a problem, and I’m going to fix it.”

Team Snorkel