
Schlumberger is the world’s leading provider of technology and services for the energy industry, operating in over 120 countries. The company provides well maintenance and analytics services to the world’s biggest oil companies, and it believes that large-scale data analysis and artificial intelligence/machine learning will help them remain a leader in the market. One way they’ve been able to achieve this is by building their own AI application using Snorkel Flow to automatically extract geological entities and critical field data across a variety of document structures and report types they receive from their customers.
Providing proactive well maintenance with automated information extraction
Schlumberger (SLB: NYSE) is a technology company that partners with customers to access energy. The Software Technology Innovation Center (STIC), within the 85,000-person industry leader, is dedicated to using new AI/ML applications to support the company’s mission to improve the performance and sustainability for the global energy industry. One way is to streamline information extraction from critical field data that underpins Schlumberger’s efforts to do a large-scale analysis of business operations and deliver data-driven insights into their performance.
Challenge
The energy industry generates tons of daily reports ranging from daily drilling reports to well maintenance logs. Each document has its structure and format, which makes it difficult for Schlumberger’s team to extract crucial information quickly. Automating the information extraction of the text within these unstructured PDFs using Named Entity Recognition (NER) would greatly accelerate the team towards their goal of delivering highly-accurate large-scale analysis.
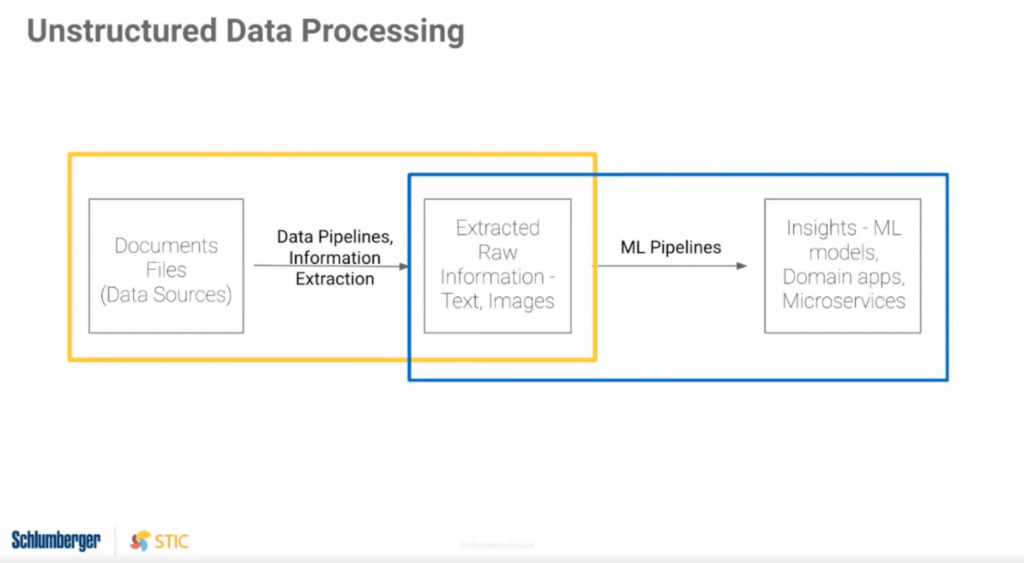
The team explored typical off-the-shelf ML models but wasn’t able to identify the scientific terms related to the Exploration and Production (E&P) industry. They also tried to create a domain-specific training dataset using various labeling tools and borrowing from precious subject matter expert (SME) time, but that took anywhere from 1-3 hrs per document, which wasn’t scalable. Ultimately, the team needed to identify 18 different industry-specific entities and automatically identify and associated data with these entities, but a few things stood in the way:
- Rich information was buried within tabular and raw text in PDFs with varied formatting across reports from different companies.
- Poor collaboration between domain experts and data scientists with cumbersome file sharing and ad-hoc meetings.
- Time to label training data manually was a bottleneck to building AI to automate this effort.
“What would have taken us months to go through an iteration can happen in minutes now. Literally!”
Swaroop Kalasapur
Head Of Schlumberger Technology Innovation Center, Schlumberger
Goal
Minimize the time subject matter experts (SMEs) spend labeling training data while ensuring that the system can adapt to new or changing document formats.
Solution
In just three days, Schlumberger was able to build an AI application using Snorkel Flow to automatically extract key scientific data from geological and field data reports and use it to guide recommendations for better well management across multiple clients. By using a data-centric artificial intelligence (AI) development lifecycle accelerated by programmatic labeling, Monisha Manoharan, a Machine Learning Engineer at Schlumberger, and her team built a classification task that reached an 85% F1 score in those initial three days with the Snorkel Flow team.
After a few rounds of rapid iteration using Snorkel Flow’s model-guided error analysis and programmatic labeling, they improved their F1 score to 91.4%. Which was “impressive compared to what we had achieved previously,” Monisha said.
The AI application Monisha and her team built with Snorkel Flow reduced the processing time of reports from 1 to 3 hours per report to just a few seconds. Using their new AI app, they extracted several different entities from unstructured data, including well maintenance activity description (textual), time of activity (numerical), and more. They also overcame the challenge of non-standard reporting formats, successfully identifying entities across 15 different document structures.
- ML solution generalized to a variety of document structures, including unseen PDF and tabular formats.
- Improved collaboration between domain experts and data scientists across labeling, troubleshooting, and iteration.
- Auto-labeled by capturing labeling expertise as labeling functions and applying intelligently en-masse.
Not only did Monisha and the STIC team successfully develop an AI-enhanced tool to help Schlumberger extract key field/scientific data automatically, they’ve also established a repeatable data-centric AI development lifecycle as a foundation for the future of data science development at Schlumberger.
“We created a binary classification task and we were able to reach an 85 F1 score in under three days… later improving that score to 91.4 which is highly impressive compared to what we had before.”
Monisha Manoharan
Senior Machine Learning Engineer Schlumberger
<3 Days
to build a highly-performant ML application
47%
improved generalization over previous rules-only approach
This work was presented at the Future of Data-centric AI event hosted by Snorkel AI. Watch this and many other sessions on-demand at future.snorkel.ai.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

