The Snorkel AI team will present five research papers advancing weak supervision and programmatic labeling at the NeurIPS 2022 conference that started this week.
Over the last year, Snorkelers wrestled with fundamental problems in understanding how to build useful models quickly by extending core approaches to data-centric AI in the context of ever-more-powerful foundation models.
Are you planning to attend NeurIPS 2022 in New Orleans? Several of the Snorkelers that drove this work will be at NeurIPS this year – we’d love to chat with you!
Snorkel AI prides itself on developing cutting-edge research in data-centric AI. We intentionally designed Snorkel Flow with flexible abstractions and extensible interfaces that allow us to continually integrate the latest and most remarkable technologies from our lab and create an ever more powerful tool for our customers. As part of our science-first culture, Snorkel AI founders and researchers present at distinguished AI conferences such as NeurIPS.
During NeurIPS 2022, we are honored to present the following five papers:
BIGBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jason Fries, Leon Weber, Natasha Seelam, Gabriel Altay, and the BigScience Biomedical Working Group
- As part of BigScience, members of the Snorkel AI research team participated in a year-long collaborative workshop on creating large language models. This led to the development of a community library of 126+ biomedical NLP sets covering 12 task categories and 10+ languages distributed via the BIGBIO package.
- BIGBIO facilitates meta-dataset curation via programmatic access to biomedical NLP datasets and their metadata. it is compatible with current platforms for prompt engineering and end-to-end few/zero-shot language model evaluations
- Key utilities include: 1.) source-preserving schema and task-specific, harmonized schema, 2.) unit tests to enforce unique IDs across elements and maintain dataset integrity for properties like labeled span offsets , and 3.) integration with the PromptSource prompt engineering framework and EleutherAI Language Model Evaluation Harness.
This work sets the stage for domain experts to construct and share new biomedical instruction tuning datasets for training and evaluating models across multiple, complex biomedical NLP tasks using the most modern foundation models available. It’s an exciting contribution to the open-source community.
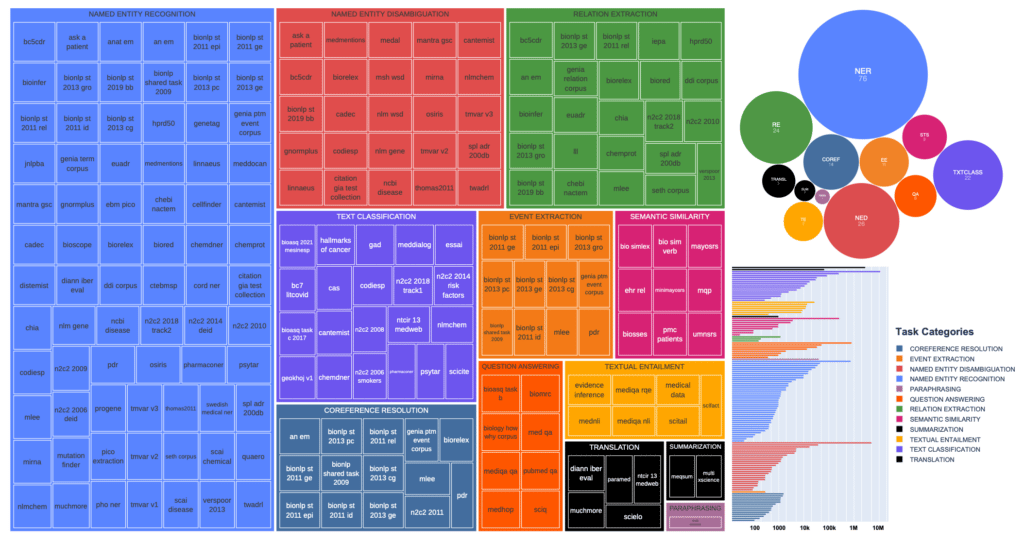
(left); the distribution of dataset sizes measured by number of examples (bottom right); and a circle
plot of task categories and their relative size (top right).
Understanding Programmatic Weak Supervision via Source-aware Influence Functions
Jieyu Zhang, Alexander Ratner, Haonan Wang, Cheng-Yu Hsieh
- For popular Programmatic Weak Supervision (PWS) applications (like Snorkel) this work shows that one can build on Influence Function (IF) approaches for understanding the influence of training data on model performance by using source-aware IFs, which leverage knowledge of the PWS process used to generate training data.
- Source-aware IFs provide several distinct pieces of value: 1.) interpreting incorrect predictions in a way that allows PWS debugging, 2.) identifying mislabeling with a gain of up to 37% over baselines, and 3.) improving end model generalization by up to 24% versus standard IFs by removing harmful components in the training objective.
- These results point to a significant value proposition of PWS techniques; you can not only figure out which data points are potentially harmful but identify which labeling signals are causing those trends and programmatically correct them!
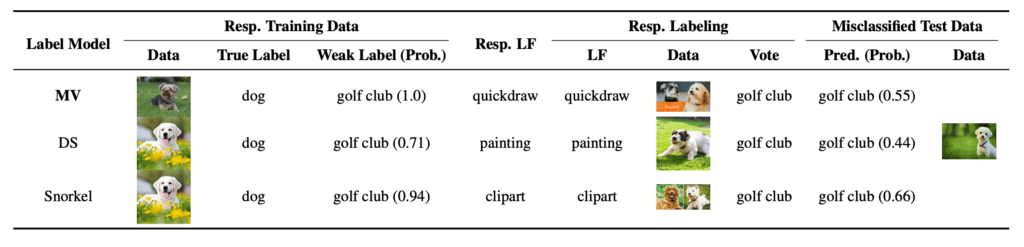
misclassification of end models (trained with difference label models) on the same test image. We
can see that source-aware IF can reveal the cause of misclassification from multiple angles.
Lifting Weak Supervision to Structured Prediction
Harit Vishwakarma, Fred Sala
- In this work, the team tackles a critical unresolved problem in Weak Supervision (WS) theory: do key results from binary or multiclass classification generalize to structured prediction problems that output rankings, graphs, manifolds, and more?
- The authors demonstrate and analyze new techniques for WS for these contexts, leading to 1.) a generalization of existing WS results to structured prediction and manifold-valued regression, 2.) finite-sample error bounds for these contexts, 3.) generalization error guarantees for training downstream models on WS-generated labels and 4.) empirical results demonstrating improvements over existing techniques.
- The WS community has been waiting for results like this for a while – it’s exciting to see more evidence that the type of WS approaches used in Snorkel have strong theoretical performance guarantees.

AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
Nick Roberts, Fred Sala et al., collaborating with Aws Albarghouthi
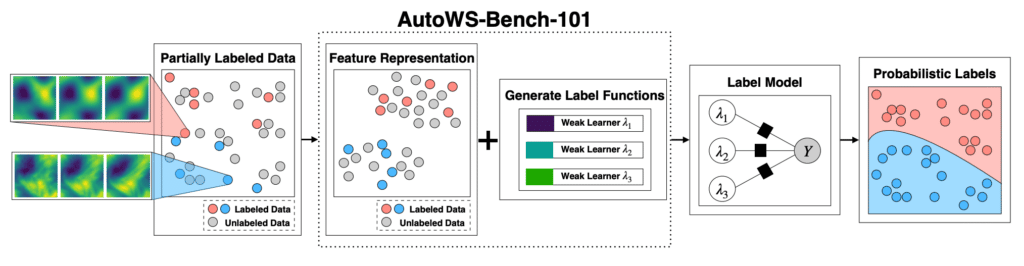
- The core question of this work is how to systematically measure, analyze, and compare the performance of Automated Weak Supervision (AutoWS) methods where labeling functions can be automatically generated by training weak learners on a small set of labeled data.
- The AutoWS-Bench-101 benchmark attempts to answer this question by allowing plug-and-play combinations of feature representations, labeling function candidate generation approaches, and labeling function selection procedures built to enable rapid development and experimentation.
- Key findings from analyzing several leading methods from AutoWS and few-shot learning demonstrate that 1.) foundation models are only helpful to AutoWS for in-distribution or related tasks, 2.) LFs that output multiple classes might be better than class-specialized LFs, and 3.) foundation model usage can hurt coverage, the fraction of points labeled by AutoWS.
- Work on AutoWS is still in its infancy, and this work will help us better understand how these potentially powerful techniques should be evaluated.
Tight Lower Bounds on Worst-Case Guarantees for Zero-Shot Learning with Attributes
Alessio Mazzetto, Cristina Menghini, Andrew Yuan, Eli Upfal, Stephen H. Bach
- The authors theoretically analyze the setting of attribute-based Zero-Shot Learning (ZSL), in which attributes from seen classes (e.g., the mane or four-leggedness of a lion) can be used to predict unseen classes that have particular alignments of attributes (e.g., a sheep does not have a mane but is four-legged).
- They observe that attribute-based ZSL suffers from two possible sources of error: domain shift (e.g., the legs of a lion don’t look exactly like the legs of a sheep) and insufficiently precise class-attribute signatures (e.g., a bobcat and a leopard both have four legs and no mane, but their colors vary so they can sometimes still be distinguished).
- This work derives a tight lower bound on this second type of error (unclear class-attribute signatures). It supports it with empirical results, providing valuable information for ZSL users attempting to apply their models to new contexts using an attribute-based method.
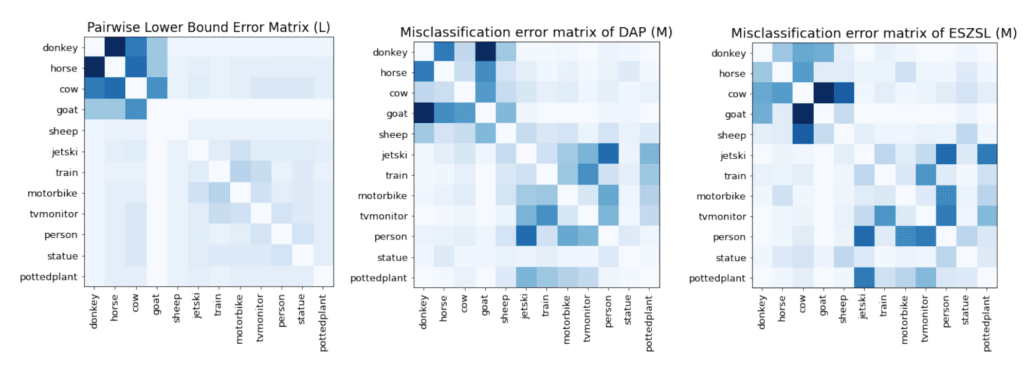
lower bound between pairs of classes L (Section 4.2), and the misclassification error matrix M of two
ZSL models: DAP and ESZSL. Darker squares indicate higher values, and light blue on the diagonal
is 0. High values of the lower bound indicate classes that are harder (in the worst-case) to distinguish
in theory, and high values in M indicate pair of classes that are often confused by the ZSL model.
If you’re also attending NeurIPS 2022, we look forward to seeing you there and hope you’ll stop by our presentations and posters! You can find more past research papers by the Snorkel AI team on our website. To learn more about data-centric AI with Snorkel Flow, request a demo, or stay informed about future news and research from the Snorkel team, you can follow us on Twitter, Linkedin, and Youtube.
