
The Future of Data-Centric AI Talk Series
Background
Alex Ratner is CEO and co-founder of Snorkel AI and an Assistant Professor of Computer Science at the University of Washington. He recently joined the Future of Data-Centric AI event, where he presented the principles of data-centric AI and where it’s headed. If you would like to watch his presentation in full, you can find it below or on Youtube.
Below is a lightly edited transcript of the presentation.
What is “data-centric AI”?
The notion of data-centric AI might sound a little tautological to many. When we as a field say “AI” nowadays, we are talking primarily about machine learning, which is by definition about data and always has been. So the question we begin with is first: What is “data-centric AI” and why is the industry’s increasing focus on it new and different? A good way to answer that is to start by contrasting data-centric AI with what has been the focus of machine-learning development for many years: model-centric AI. In model-centric AI development, the data is more or less a fixed input, and the majority of your development time, as an AI/ML engineer, is spent iterating on the model.
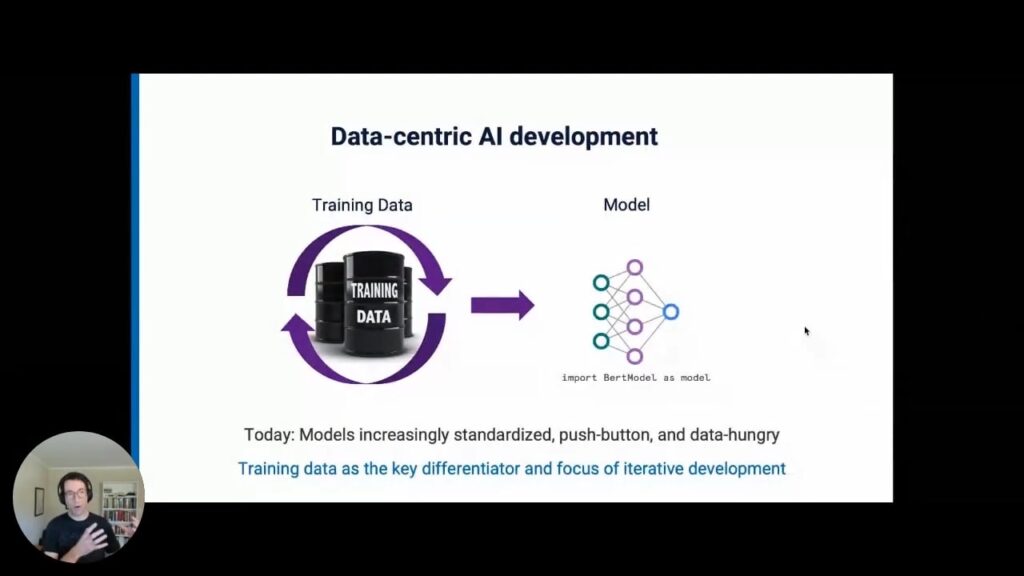
In a data-centric AI development cycle, data is instead the central object you iteratively develop, that is you spend relatively more of your time labeling, managing, slicing, augmenting, and curating the data, with the model itself remaining relatively more fixed.
While artificial intelligence has mainly focused on ML models, those engineers actually putting models into production know that focusing on the data is crucial 1.
Data-Centric AI vs. Model-Centric AI
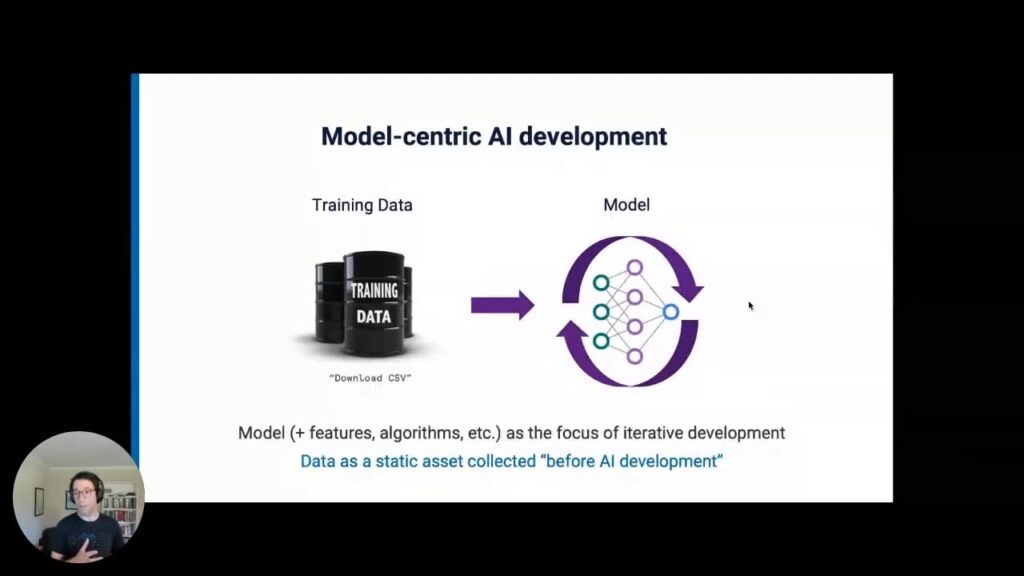
In the model-centric approach to development, there is frequently the sense that the dataset is something “outside” or “before” the actual AI development process. Machine learning development (at least the predominant supervised learning kind) starts with a training dataset: a collection of “ground truth” labeled data points that your model learns from or fits to. In a traditional model-centric ML development process, the training data is treated as a fixed input that is exogenous from the machine-learning development process. When, for example, you start your academic experiment against one of the benchmark datasets like ImageNet, your training data is something you download as a static file. After that, any new iterations of your project result from changes to the model (at least in the broadest sense). This process includes things like feature engineering, algorithm design, bespoke architecture design, etc- all about iterating on and developing the model. In other words, you are really “living” in the model and treating the data as a static artifact.
In a data-centric approach, you spend relatively more of your time labeling, managing, slicing, augmenting, and curating the data, with the model itself remaining relatively more fixed.
The tectonic shift to a data-centric approach is as much a shift in focus of the machine-learning community and culture as a technological or methodological shift—“data-centric” in this sense means you are now spending relatively more of your time on labeling, managing, slicing, augmenting, and curating the data, with the model itself relatively more fixed.The key idea is that data is the primary arbiter of success or failure and is, therefore, the key focus of iterative development. It is important to note that this is not an either/or binary between data-centric and model-centric approaches. Successful AI requires both well-conceived models and good data.

The Principles of Data-Centric AI Development
1. AI development today increasingly centers around the data, especially training data.
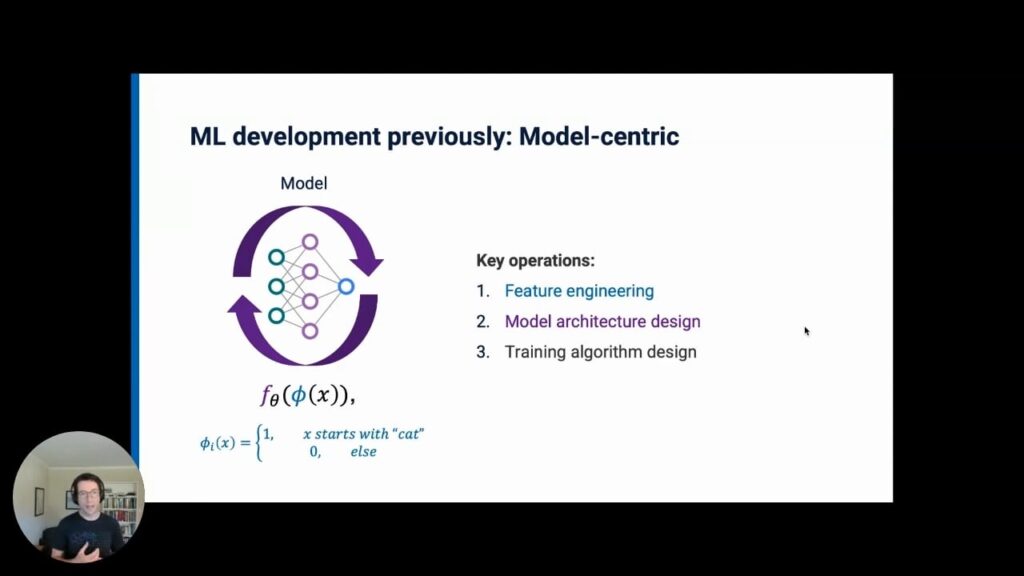
As mentioned above, until recent years, machine-learning development had been almost entirely model-centric, where the data was mostly imagined as “outside” the process. Even just five years ago, the primary toolkit and focus of development for almost every single machine-learning team was centered around:
- Feature engineering, i.e., selecting specific attributes or features of the data that the model is actually seeing and learning from.
- Model architecture design, meaning the actual structure of whatever weights or parameterizations of those features that get fed into the model as input.
- Training algorithm design.
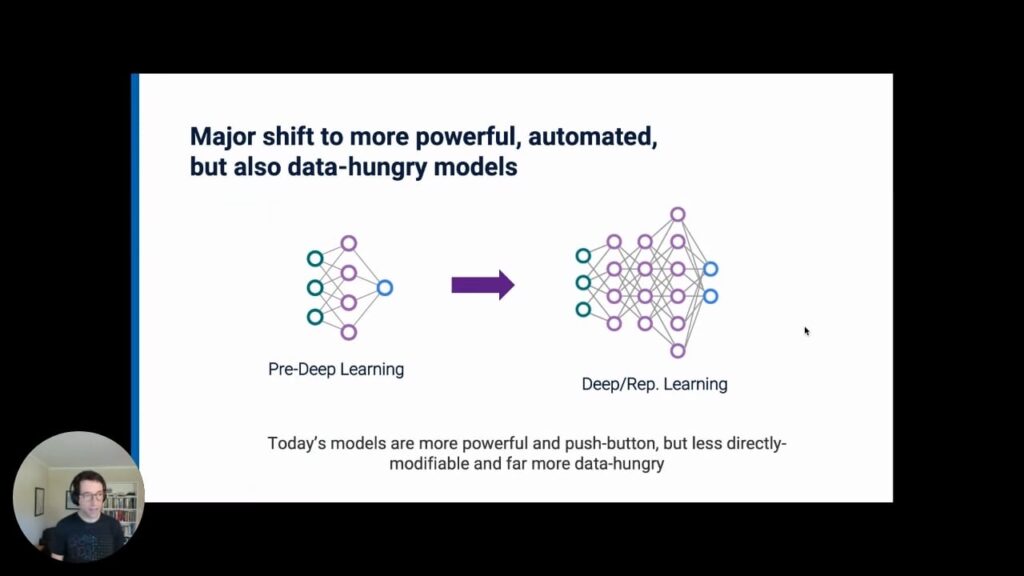
More recently, though, the industry has begun to exhibit a major shift to much more powerful, automated, but also data-hungry representation learning models. We often call these “deep learning” models. Rather than, say, thousands of free parameters that need to be learned from your data, there are sometimes hundreds of millions. So, despite their power and utility, these models need a great deal more label training data to get to their peak level of performance.
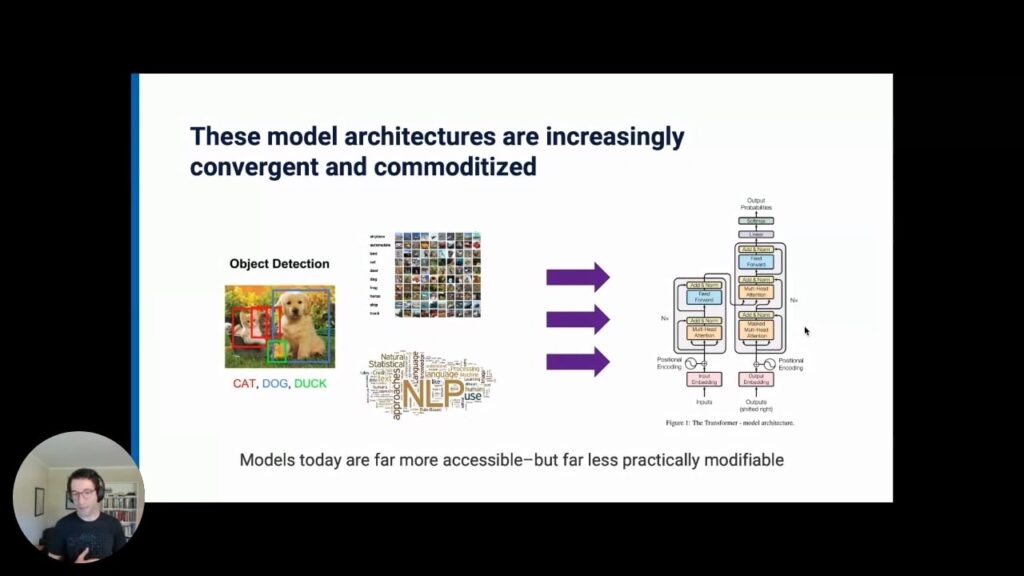
An increasing diversity of tasks and data modalities are all being handled by an ever smaller and more unified set of model architectures that are more push-button, accessible, and powerful than ever before. But they are also far more data hungry and far less practical to modify.
Excitingly, deep learning model architectures are increasingly convergent and commoditized, which means that they are far more accessible than models from years or decades ago. An increasing diversity of tasks and data modalities are all being handled by an even smaller and more stable set of model architectures. But as a result, they are far less practical to modify for users.

And even as these black-box models are increasingly more powerful, they are that much hungrier for data. Because of this, your training data—including data volume but also your data’s quality, management, distribution, sampling, etc.—is more and more the primary arbiter of success. Looking at the most recent literature in the field 3, it seems clear that most progress on state-of-the-art benchmark tasks is finding creative ways to collect more data, augment it, and then transform or boost it to use it more effectively. In order to meaningfully improve machine learning technology, data now has to become your primary focus.As a result, though, most of the key operations that used to be what machine-learning and AI development teams spent most of their time on—feature engineering, model architecture design, training algorithm design, and on—are no longer so prominent or time-intensive. Instead, your team’s largest chunk of time is spent on training data collection, augmentation, and management of your data. That presents a conundrum, because while data is the key emerging interface to developing AI today, it is likewise the key bottleneck that constrains progress. This challenge brings us to the second principle of data-centric AI.
2. Data-centric AI needs to be programmatic
Given the growing prominence of data-hungry machine-learning models, how teams interface with their data needs to be something much more efficient than manually labeling and curating one data point at a time.
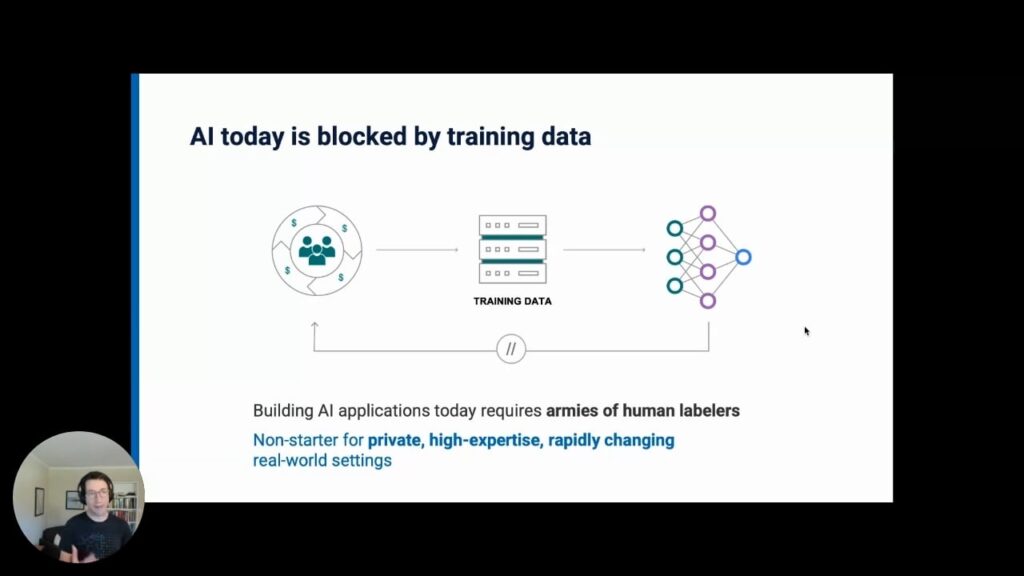
Building AI applications today often requires virtual armies of human labelers, and that kind of investment and labor requirement is almost always a non-starter for private, high-expertise, and rapidly changing real-world settings. Far from hours or days, it can take multiple person-years for data to actually be ready for machine learning development.
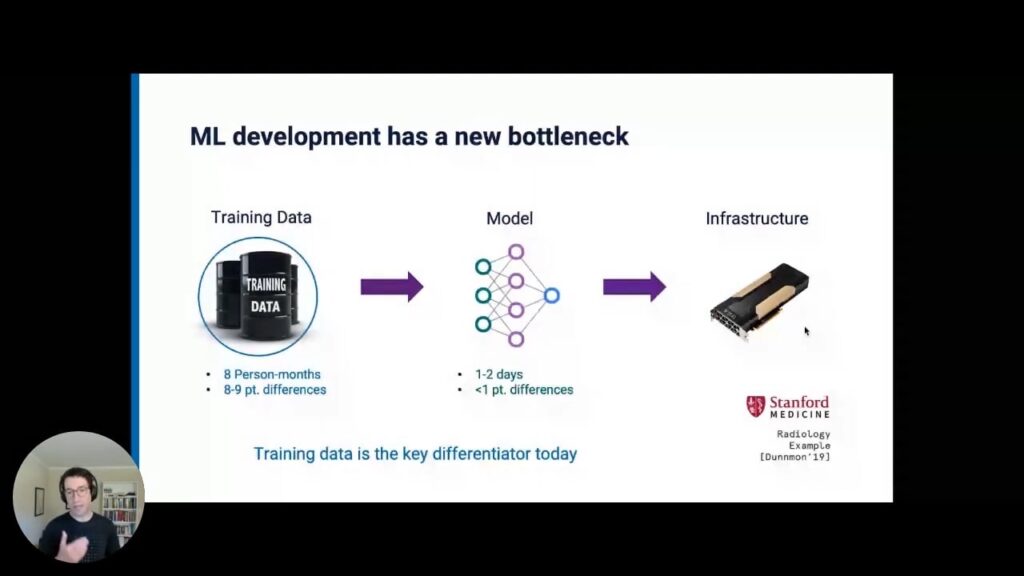
For one use-case example, the Stanford AI Lab Snorkel research project partnered with Stanford Medicine to research using machine learning to rapidly classify and triage chest x-rays 2. Building the actual ML models took only a day or two using OSS libraries, and the differences in results between different models were actually quite minimal, usually less than one point. Whichever state-of-the-art model we fed the data to, it did not make much difference in the accuracy of our results. In contrast, it took between eight and fourteen person-months of manual labeling by our radiology and medical partners to label the training data originally, and the quality of the labeled training data we fed the models was immensely impactful, making eight- or nine-point differences. This underscores the theme: while the model is still a critical part of the machine-learning process, the highest leverage point for improvements is the data—how it is managed, partitioned, and augmented. But again, getting that labeled data took the equivalent of eight person-months. And it highlights the fundamental challenges of training data:
- Real-world use cases require subject matter expertise (SME) for labeling. For example, for a usable medical or clinical dataset, you need medical doctors or professionals doing the labeling. For usable legal datasets, you need qualified lawyers. Often these are SMEs who already have little time to devote to manual labeling tasks.
- Real-world data is private and proprietary to a particular organization or enterprise. It cannot simply be exported or put in open source for others to use, modify, or learn from.
- Real-world data and objectives often change rapidly, including the data distribution coming in and the modeling objectives for which you’re actually building your model. As a result, you frequently have to re-label data.
Manual data-labeling and curation, then, is essentially a non-starter for most real-world organizations, even for the largest of them.
Manual data-labeling and curation, then, is essentially a non-starter for most real-world organizations, even for the largest of them. This is before machine learning teams run into the ethical and governance challenges of manually labeling training data. How do we inspect or correct the biases that human labelers bring to the table? How do we govern or audit a dataset of hundreds of millions of hand-labeled data points? How do we trace the lineage of model errors back to where in the dataset the model learned it from? Solving these critical challenges with large, manually-labeled training datasets is a practical nightmare for organizations. In fact, it can actually be a bigger problem than the problem you were trying to solve in the first place.
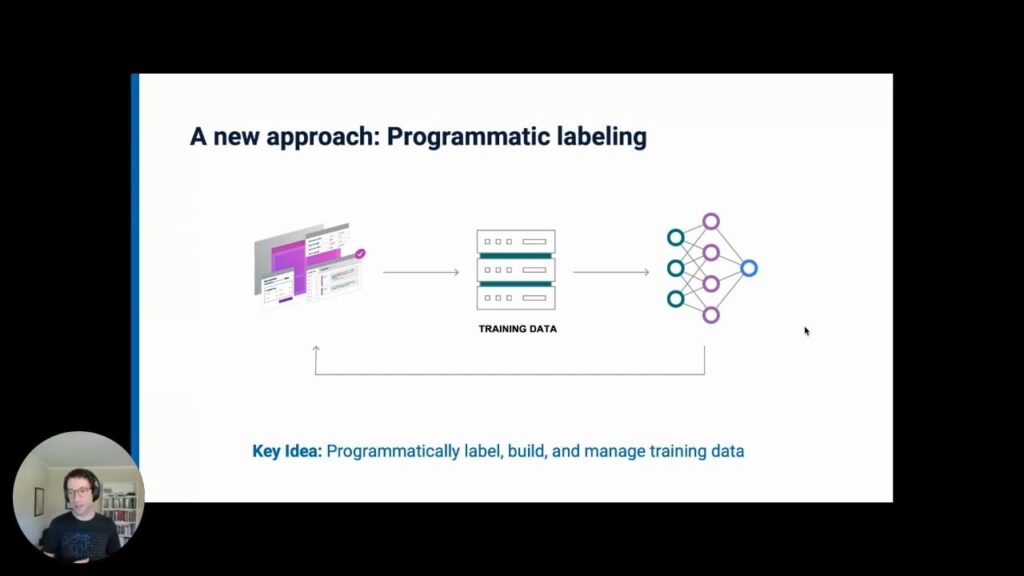
The way Snorkel AI solves the manual-data-labeling problem is programmatic labeling. For a simple example, you might ask an SME to just write some keywords or phrases, and then label data points with lines of code, rather than laboriously labeling each data point, one by one, manually.
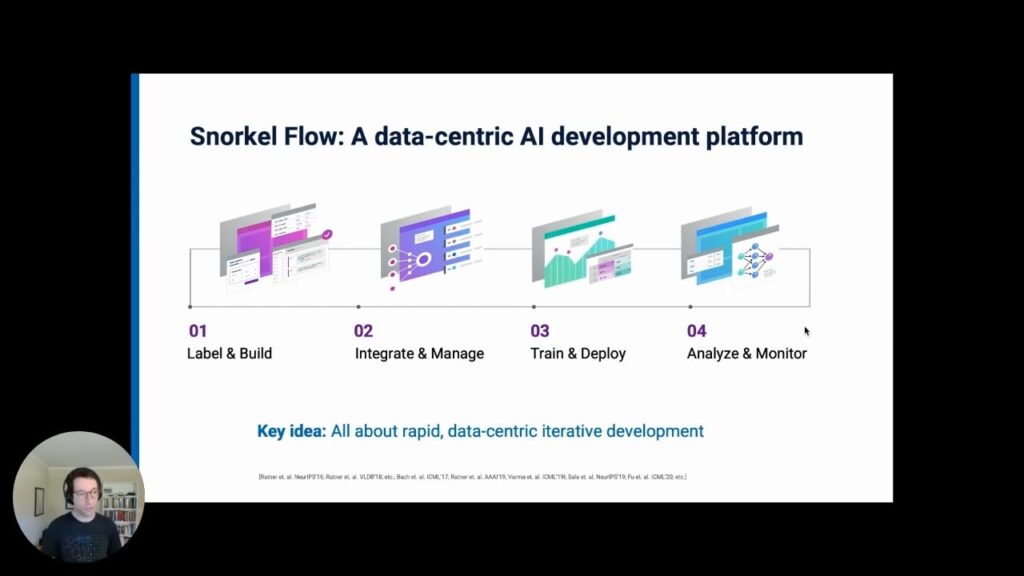
At Snorkel AI, our goal is creating a platform for rapid, data-centric, iterative AI development. In other words, it revolves around modifying, labeling, and managing your data. We call it Snorkel Flow. It has four basic steps:
- Label and manage your training data, doing so programmatically by developing what we call “labeling functions”, based on work we did the Stanford AI lab starting in 2015 and continuing through to today. In Snorkel Flow, these labeling functions can be developed with either a no-code UI, featuring auto-suggest and guidance, or with a Python SDK.
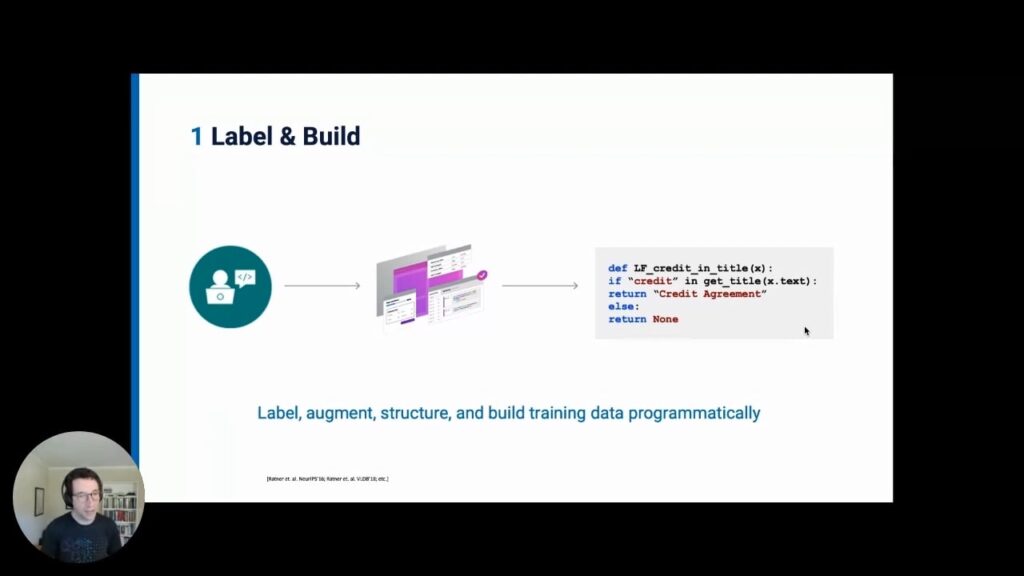
Snorkel Flow then serves as “Supervision Middleware” for diverse sources of input including patterns, models, knowledge bases and ontologies, and more.

- Integrate, clean, and manage this programmatic input, which is far more efficient and practical but also is messy- i.e. these labeling functions will make mistakes, they will have coverage gaps, they will have correlations, and more; we call the modeling and integration of this noisy data “weak supervision”.
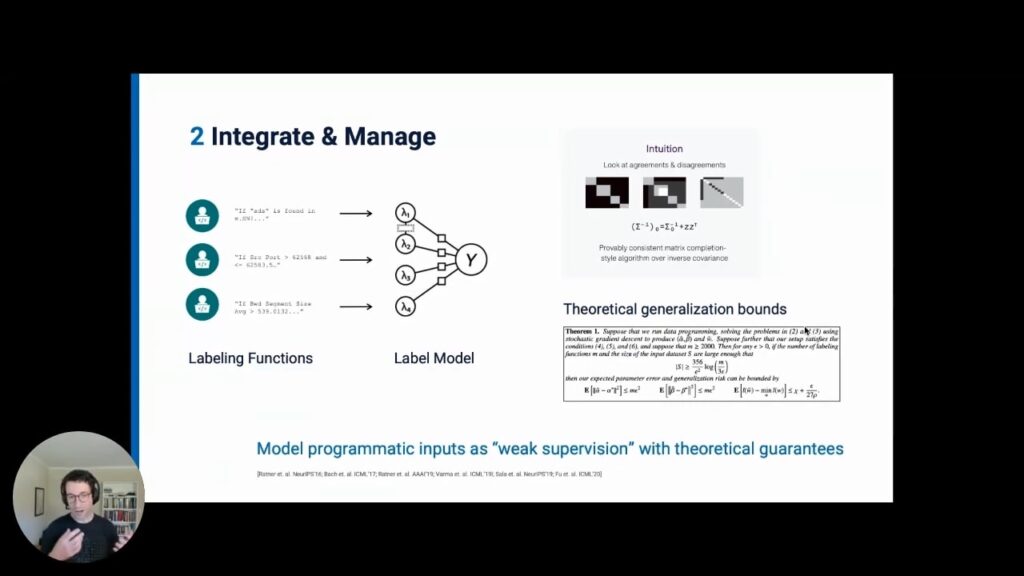
- Use this data to train and deploy models, allowing you to train the latest data-hungry model architectures on your data.
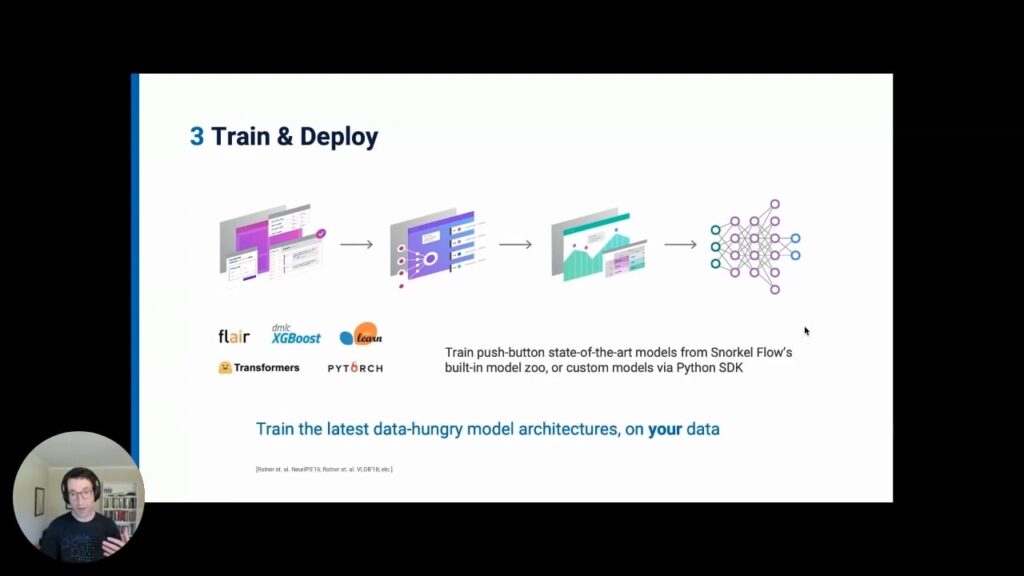
One way of looking at this overall process: You can take some of the best of what rules-based inputs provide–efficiency and transparency of specification, modifiability, auditability, etc.– and bridge that with the generalization capabilities of modern machine learning techniques, including transfer, self-, and semi-supervised approaches.The key idea here, which we’ve provided theoretical rates for, is that you can then scale up with unlabeled data at the same rate as with adding labeled data. In other words, you can dump more unlabeled data (which are too expensive to label) into these programmatic labeling approaches, thus taking advantage of the volume of unlabeled data present in documents or network signals and actually get similar scaling benefits in terms of model performance.

- The fourth step in Snorkel Flow is to analyze and monitor errors in the model, which we can correct by going back to modify the data, effectively “closing the loop” of the flow.

Snorkel Flow “closes the loop” by rapidly identifying and correcting error modes in the data and models just by writing and editing labeling functions (LFs), thus allowing you to rapidly adapt to real-world conditions constantly and iterativelyIn 50+ peer-reviewed publications over the years, and customer case studies via the Snorkel AI company 3, this Snorkel approach offers an empirically proven way to accelerate AI—it saves person-months and even years, at or above quality parity, on a diverse set of applications.
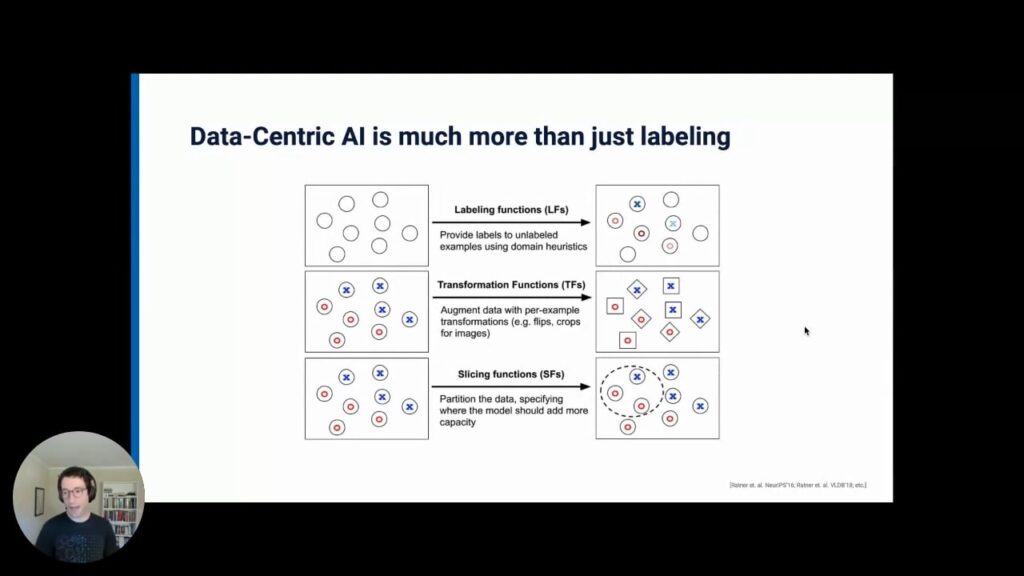
Snorkel Flow has implemented this data-centric approach across the entire workflow for AI because “data-centric” AI is much more than just labeling. It also includes Transformation Functions (TFs), Slicing Functions (SFs), and more.Finally, we come to the third main principle of data-centric AI.
3. Data-centric AI needs to be collaborative with subject-matter-experts
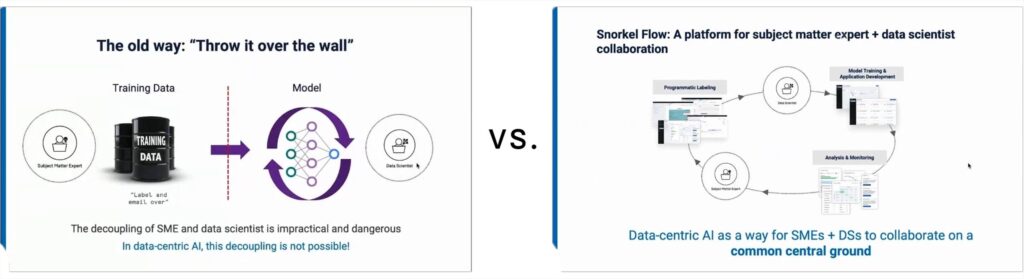
For AI to be effective and safe, the SME who actually knows how to label and curate the data has to be included in the loop–and data-centric AI enables this
In the traditional way of doing things, SME labelers and ML engineers/data scientists are disconnected. With Snorkel Flow, SMEs and MLEs collaborate as a fundamental part of the process.
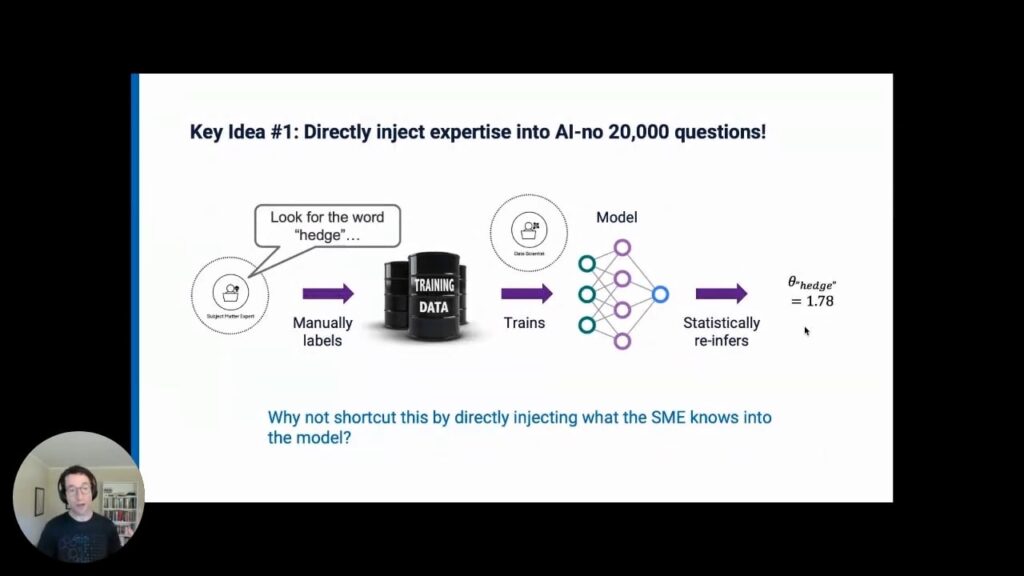
When the SME who actually knows how to label and curate the data is included in the loop, it makes for a much better AI platform. Here are three reasons why:First, including the SME in the loop allows you to directly inject expertise into the model, rather than the model trying to infer features or heuristics that the SME already knows.
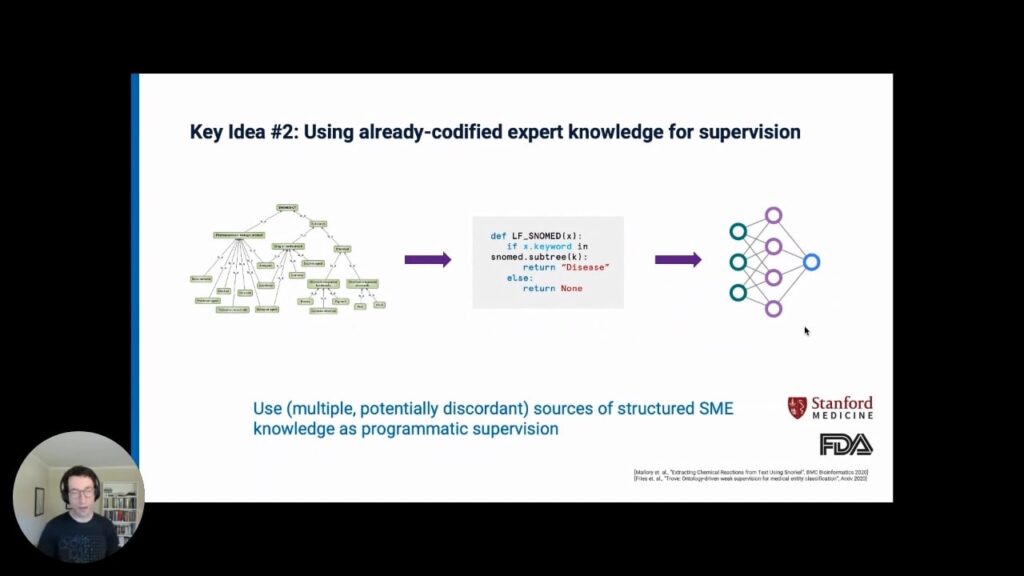
Second, Snorkel Flow enables you to leverage subject matter expertise that has already been encoded–e.g. knowledge bases, ontologies, legacy heuristics and rules. Snorkel Flow can use already-codified (potentially discordant) sources of structured expert knowledge for programmatic supervision.
Finally, and most importantly: including SMEs in the loop is the only real way to ensure that AI models are effective, safe, and ethical, i.e. actually aligned with the output goals and principles of the domain that the SMEs uniquely are expert in.Crucially, all these benefits of SME / data scientist collaboration are far easier to attain in a data-centric model- since you are meeting at the common ground of data as your centerpoint for iteration and development.
Summary:
The traditional model-centric approach to ML has been tremendously successful and has brought the field to a place in which the models themselves are ever more downloadable, commoditized, and, above all, widely accessible. But the newer, powerful, “deep-learning” models are now so data-hungry that not only have datasets and manual labeling of training data become unwieldy, there are diminishing returns to be had in terms of how much progress can be made iterating only on the model. The answer to pushing AI forward now and over coming years can be found in a data-centric approach.With data-centric AI development, teams spend much more time labeling, managing, and augmenting data, because data quality and quantity is increasingly the key to successful results. Data should thus be the primary focus of iteration. There are three main principles to keep in mind with a data-centric approach:
- As models become more user-friendly and commoditized, the progress of AI development increasingly centers around the quality of the training data that AI models learn from, and the ability to iterate on this data in an agile and transparent way, rather than around feature engineering, model architecture, or algorithm design.
- Data-centric AI has to be programmatic in order to cope with the volume of training data that today’s deep-learning models require, and the practical difficulty of repeatedly and manually getting these labels in most real world contexts. Manually labeling millions of data points is simply not practical. Instead, a programmatic process for labeling, managing, augmenting, cleaning, and iterating the data is the crucial determiner of progress.
- Data-centric AI should treat SMEs as integral to the development process. Including SMEs in the loop who actually understand how to label and curate your data allows data scientists to inject SME expertise directly into the model. Once done, this expert knowledge can be codified and deployed for programmatic supervision.
As the field of ML progresses, successful AI will continue to involve both well-built models and well-engineered data. But because of the sophistication of today’s models, the biggest returns moving forward will emerge from approaches that prioritize the data. And if data is increasingly the key arbiter of success or failure, data has to be the focus of iterative development moving forward. There are many exciting advances in this emerging field of data-centric AI, both here now and to come on the road ahead!If you’d like to watch Alex’s full presentation you can find it on the Snorkel AI Youtube channel. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, Facebook, or Instagram.
1 “Github – Hazyresearch/Data-Centric-Ai: Resources For Data-Centric AI”. 2021. Github. https://github.com/HazyResearch/data-centric-ai.
2 Dunnmon, Jared A., Alexander J. Ratner, Khaled Saab, Nishith Khandwala, Matthew Markert, Hersh Sagreiya, and Roger Goldman et al. 2020. “Cross-Modal Data Programming Enables Rapid Medical Machine Learning”. Patterns 1 (2): 100019. doi:10.1016/j.patter.2020.100019.
3 “Research Papers”. 2022. Snorkel AI. https://snorkel.ai/resources/research-papers/.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

