Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Long context models in the enterprise: benchmarks and beyond
Long context models (LCMs) promise to ease the creation of enterprise AI applications that reason over large quantities of text. However, evaluating the effectiveness of these models and adapting them to enterprise tasks both pose challenges. The Snorkel AI research team has developed a new, more realistic evaluation for these models for enterprise tasks (Snorkel Working Memory test) and a novel approach to counteract their shortcomings (medoid voting).
In this post, we will cover the following:
- The current state of LCM evaluation (and the challenge of evaluating large language models generally).
- Our alternative evaluation approach for LCMs.
- How the position of vital information within the context window changes LCM performance.
- Compensating for LCM positional bias with a straightforward training-free approach that leads to performance gains of up to 28 accuracy points on GPT4-Turbo.
In total, our investigation found that long context models—while impressive—need further development and customization to work appropriately on enterprise tasks.
Let’s dive in.
How long context models are evaluated today
Large language models (LLMs) pose significant evaluation challenges. Unlike traditional machine learning models, data scientists can’t point an LLM at a validation set and quickly understand its performance. Data scientists must check responses for accuracy, tone, and alignment with organizational policies and guidelines—all of which can require detailed human review. This has been further challenged with recent models accommodating long context windows, some as long as 2 million tokens.
At present, researchers and engineers primarily evaluate the long context capabilities of LLMs according to a limited set of tools: academic benchmarks1,2, or the popular “Needle in Haystack” (NIAH) test3. While these serve as useful starting points for evaluating new model releases, their relevance and applicability to real-world business scenarios remain questionable.
- Unrelated Tasks: The NIAH test often uses unrelated toy needles, which do not capture the intricacies of information retrieval in business documents, where context and relevance are crucial.
- Limited Representativeness: Academic benchmarks are often derived from datasets that do not represent the nuances and complexities of business documents, such as financial reports, legal documents, or customer feedback.
At Snorkel AI, we’ve seen firsthand how complex real-world problems render generic benchmarks insufficient or unreliable for gauging enterprise performance. To help remedy that challenge, we developed our Snorkel Working Memory test (SWiM) to measure LCM capabilities with enterprise-specific documents and task pairs. SWiM’s four-step process includes task generation, task validation, task completion, and evaluation. Directly testing on the relevant data and tasks allows a more realistic evaluation of a model’s long context capabilities for specific business applications.
Why standard benchmarks don’t work for custom problems
We used the needle-in-a-haystack test to evaluate GPT-4 and Claude 2.1. The test uses the question “What is the best thing to do in San Francisco” (as the needle) on a large collection of unrelated essays (the haystack). Both models obtained perfect scores at all document depths, but demonstrated deficiencies on our more realistic SWiM test (explained fully in the next section).
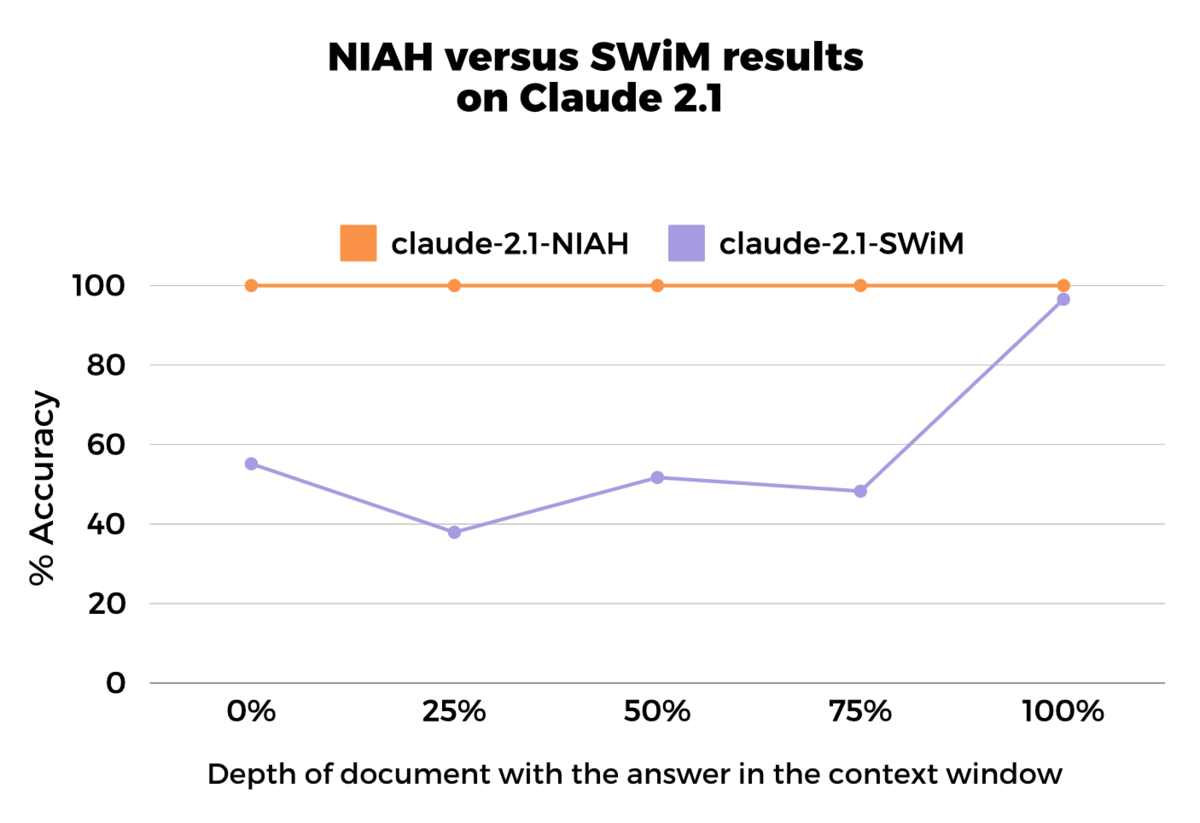
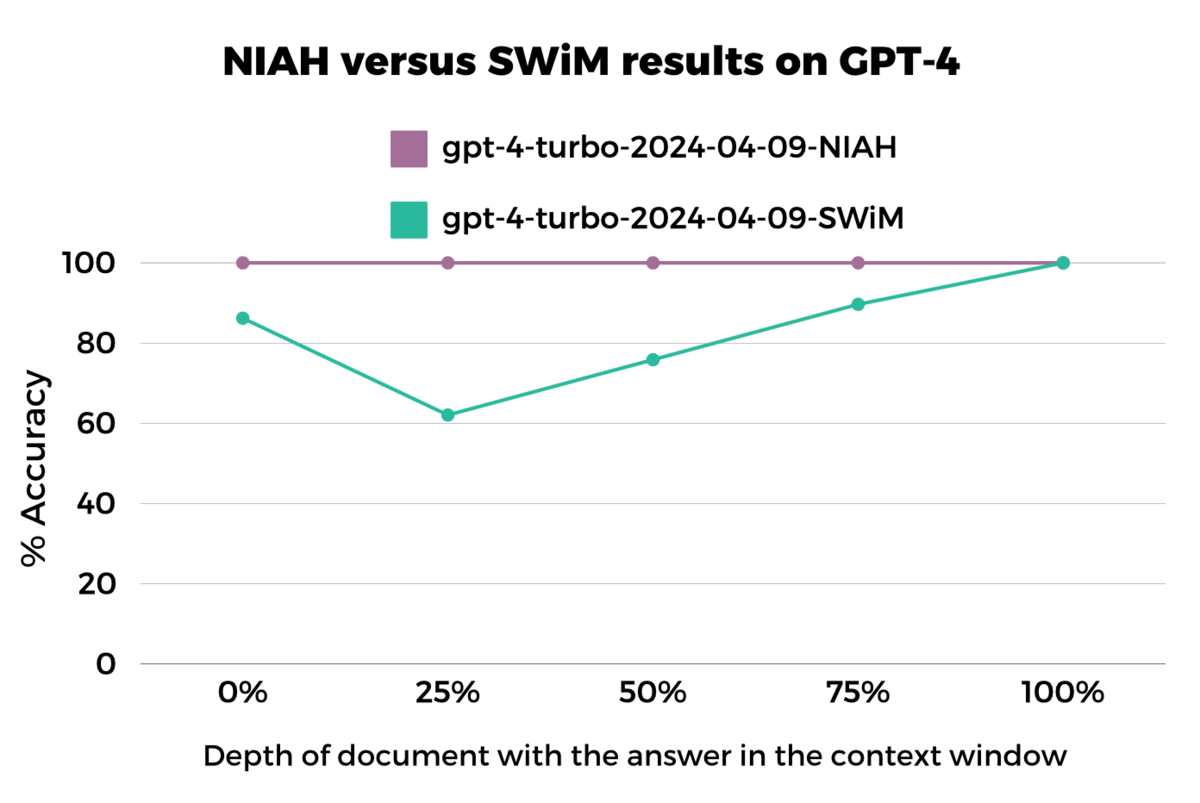
We found similar results using the RULER4 benchmark, a synthetic benchmark with flexible configurations for customized sequence length and task complexity, which showed that model performance varied significantly depending on the task and data. For instance, despite near-perfect scores on NIAH, GPT-4 scored 79.7% on word extraction tasks and 59.0% on Question Answering tasks.
Are standard benchmarks a good measure of performance on enterprise problems? No.
Business environments are often characterized by diverse data sources, complex decision-making processes, and multifaceted objectives. This presents a clear need for a tailored evaluation framework that can account for the challenges of enterprise data and tasks, providing a more realistic and informative assessment of long context model capabilities.
A tailored framework to test models on long context
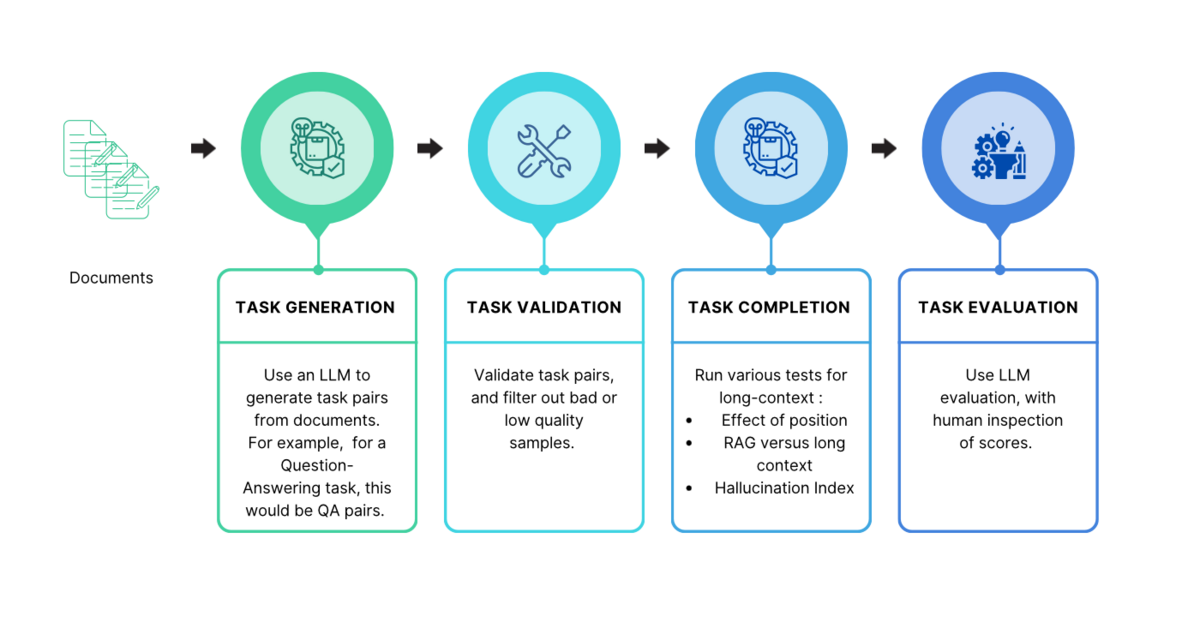
We propose the same data-driven approach to evaluation that has been crucial for model development. An evaluation framework that is purpose-built with enterprise data and expertise, and tailored to specific data slices or features, allows a more thorough and nuanced evaluation for real world applications.
With our SWiM framework, we first use an LLM to create task pairs on user documents. Then, we filter out low-quality task pairs and send the remainder to the target long context model to generate a response. Finally, we evaluate responses using an LLM-as-judge with human verification of scores. This approach enables direct assessment of the intended task on long context models, bypassing the need for proxy benchmarks.
We used SWiM to test long context models by Open AI, Anthropic, Google, and Mistral on a Document QA task.
Not all models utilize their long context windows effectively
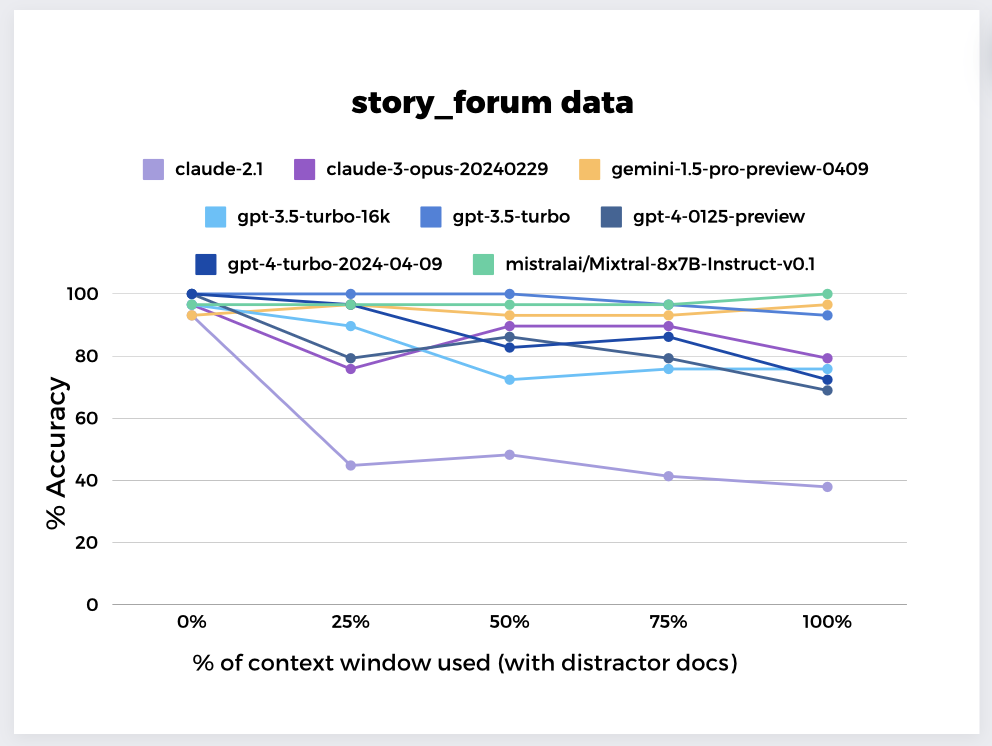
In Single Document QA, the test prompts the model with a question, the answer to which resides within a single document. We tested the Single Document QA task performance with an increasing number of documents that do not contain the answer (distractor documents in the same domain as the target document), on QA pairs created from the Hugging Face Cosmopedia story_forum dataset5. Starting with only the answer document, we added distractors to fill the context window to 25, 50, 75, and 100% of its capacity*.
As the number of distractors increased, performance degraded, but the performance of some models degraded faster than others. Among models with a long context window (1M tokens), Gemini-1.5-Pro handled the noise extremely well.
Smaller context length models (such as GPT-3.5 Turbo and Mistral-8x7B-Instruct) proved more effective at using their context lengths. This implies that for some applications where the noise-signal ratio is high (such as Question Answering), simply using a model’s long context window may not be the optimal solution. Digging deeper into the incorrect responses, we found the target document’s position in the context contributed to the models’ answer accuracy, which we discuss next.
Document position affects long context performance
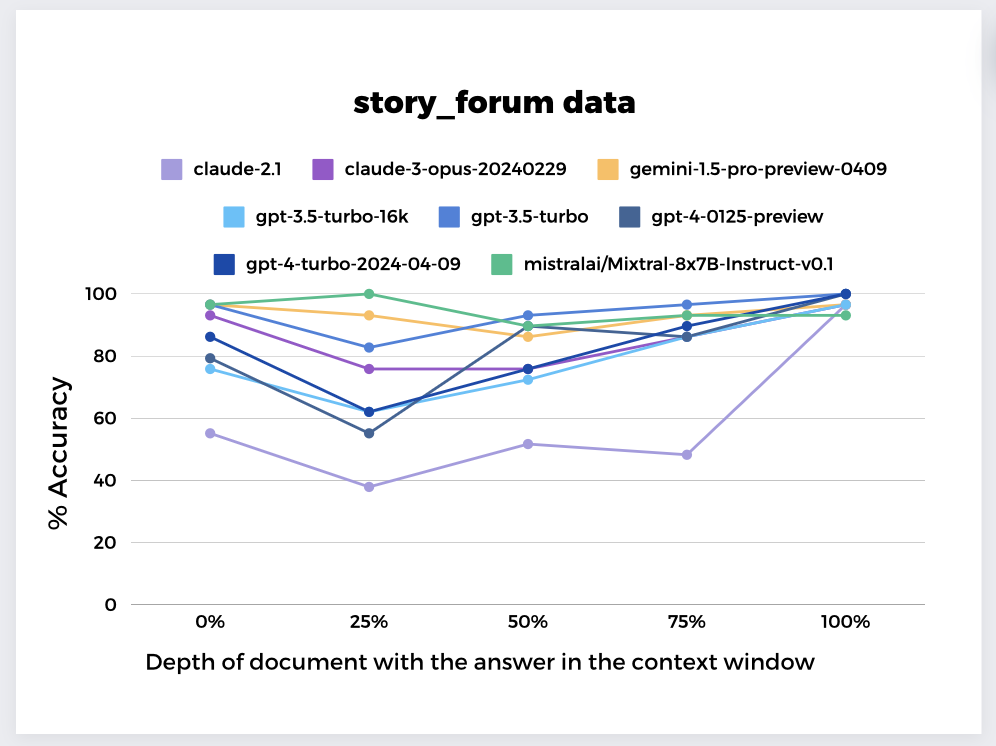
Previous investigations firmly established that position impacts the retrieval performance of long context LLMs, but the exact effect is still unclear. Liu et al. conducted studies6 where models exhibited a “Lost in the middle” effect. However other studies3 to replicate this on different models have not always yielded the same behavior. Alternately, the popular but synthetic NIAH test has reported behavior that differed from model to model.
We used SWiM to test eight long context models for the position effect on the Single Document QA task. Most models exhibited a degradation in performance, in the middle, and specifically, at the 25% depth, similar to Greg Karmadt’s findings7 for GPT-4, where low recall performance was observed at 7%-50% document depth. We found this more generally across all models.
Furthermore, we found that the NIAH test, while quick, often serves as a poor indicator of real-world performance.
This is evident in Claude-2.1’s results. NIAH results showed strong performance with the needle at the beginning and end of the context window8, but our SWiM test showed low performance when the needle lay at the beginning of the context.
The observed performance degradation of long context models in the middle poses significant implications for enterprise data applications. In enterprise datasets, valuable information is often interspersed in all sections of documents or data sequences. If models consistently struggle to maintain performance across depths, they could overlook or misinterpret crucial insights.
Flattening the curve: Reducing the “lost-in-the-middle” effect through medoid voting
Recently proposed research9 attempts to reduce the “lost-in-the-middle” effect by fine-tuning models on long context tasks. But this is computationally expensive when it’s even possible; developers often have no access to long-context models to fine-tune (for instance, when using closed models, or when teams do not have expertise in fine-tuning large language models).
Developers can also sidestep the lost-in-the-middle effect by removing distractors ahead of time through retrieval-augmented generation (RAG). The RAG approach uses a retrieval model to try to isolate and return only the context relevant to each given task. However, retrieval models may miss relevant context and also require fine-tuning—especially for domain-specific use cases.
How can we mitigate the lost-in-the- middle effect of long context models, without additional fine-tuning or retrieval models?
Since we know models generally struggle more at retrieving information from some positions when compared to others, it would help if we positioned the answer documents in the right places. Of course, we do not know what the right place is a priori. To solve this, we run the task completion a few times, each time randomly permuting documents in the context, and then use a selection criteria to pick the best response.
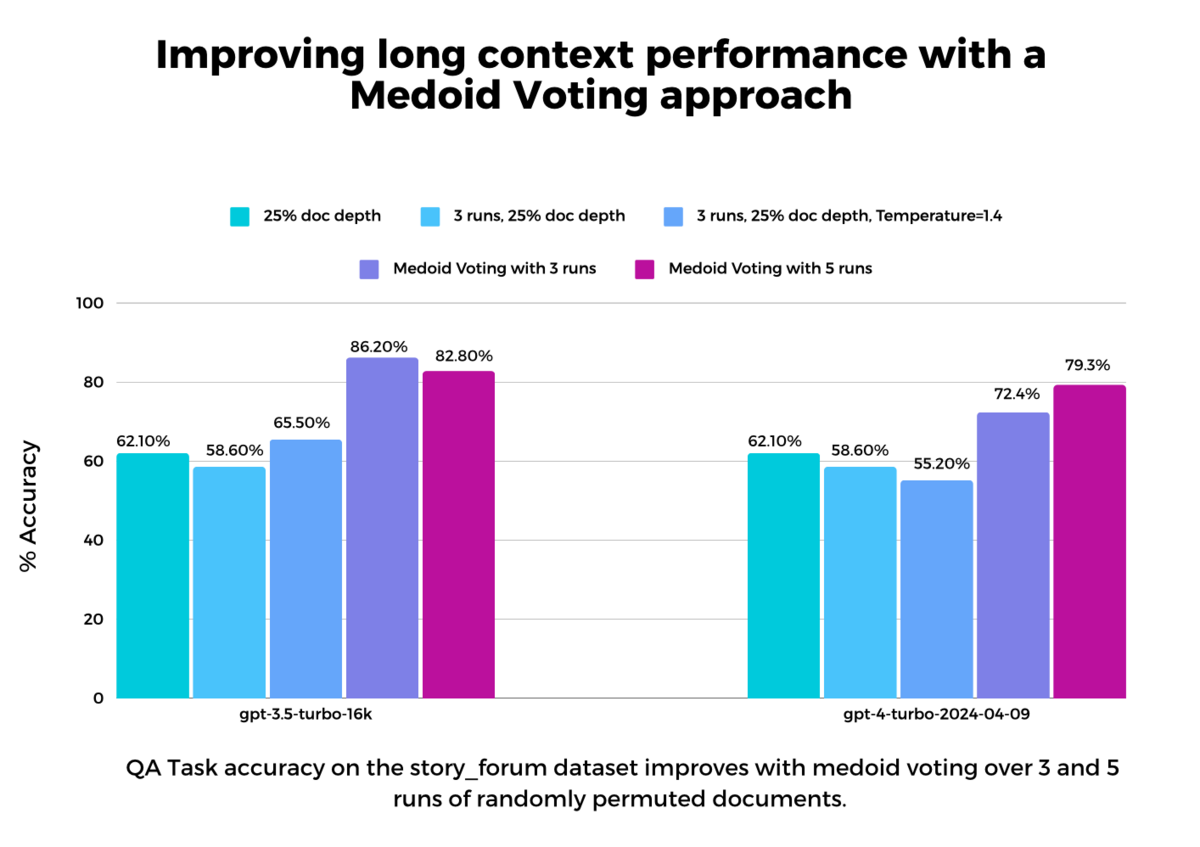
We tested this approach, which we refer to as “medoid voting”, on GPT-4-Turbo and GPT-3.5-Turbo-16k, both of which we had observed demonstrated the lost-in-the-middle effect.
We used an embedding model to calculate an embedding for each response from multiple runs, and calculated pairwise cosine similarities among the embeddings. We then chose the “medoid” response—the one with the highest average cosine similarity to all other answers—as our final answer.
We found this approach effective in practice, even on as few as three runs.
To isolate the impact of the medoid voting technique, we conducted a control experiment that generates multiple runs keeping document position constant at the unfavorable 25% document depth, with model stochasticity as the only source of variation. We did this with model generation temperatures of 0.7 (default) and 1.4 (a high temperature to induce higher variance in responses). This lets us test the specific effect that varying position has over other forms of variation in generating the final response.
Results show the medoid voting method surpasses performance over both the baseline and controls, on both models; a 28-point lift on GPT-4-Turbo, and 14-point lift on GPT-3.5-Turbo-16k. This underscores medoid voting’s superiority—a straightforward strategy that can be used to triage the types of declines in performance identified by the SWiM test.
Importantly, this method can also be used in tandem with fine-tuning strategies aimed at more robust LCM development for specific use cases when overall LCM accuracy is not high enough out of the box.
Future enhancements
Evaluating LLMs is hard. We believe the future of LLM evaluation is, as Snorkel AI CEO Alex Ratner says, in a “customized benchmark for your use case.” We developed SWiM with this in mind—enabling users to create a personalized benchmark to evaluate their use cases.
While some models such as Gemini-1.5-Pro resisted noise well in the setting of single document QA, they may be less effective in more complex scenarios. For instance, when distractors are related to the document in question or when reasoning over multiple documents in a non-trivial manner, or when a task requires citations to specific sources within documents.
We hope to extend SWiM in the future, to include more complex scenarios such as multi-document tasks for reasoning and retrieval, measuring hallucinations, and extreme classification tasks.
To learn more about this project, see our GitHub repo here: https://github.com/snorkel-ai/long-context-eval
* For simplicity we use tiktoken to count tokens. For non OpenAI models, this means that we use slightly lower context sizes than the reported size.
References
[1] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding https://arxiv.org/abs/2308.14508 [2] ∞Bench: Extending Long Context Evaluation Beyond 100K Tokens https://arxiv.org/abs/2402.13718 [3] Needle In A Haystack – Pressure Testing LLMs https://github.com/gkamradt/LLMTest_NeedleInAHaystack/tree/main [4] RULER: What’s the Real Context Size of Your Long-Context Language Models? https://arxiv.org/abs/2404.06654 [5] Huggingface Cosmopedia https://huggingface.co/datasets/HuggingFaceTB/cosmopedia [6] Lost in the Middle: How Language Models Use Long Contexts https://arxiv.org/abs/2307.03172 [7] Pressure Testing GPT-4-128K With Long Context Recall https://twitter.com/GregKamradt/status/1722386725635580292 [8] Claude 2.1 (200K Tokens) – Pressure Testing Long Context Recall https://twitter.com/GregKamradt/status/1727018183608193393 [9] Make Your LLM Fully Utilize the Context https://arxiv.org/abs/2404.16811
Amanda Dsouza
Amanda Dsouza is Staff Applied Research Scientist at Snorkel AI. Before joining Snorkel, she was Staff Data Scientist at Jasper.ai, working on large language models, and Lead Data Scientist at Fractal.ai, where she led a team working on natural language processing and text mining problems for industry and applied research.